 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards vision-based dual arm robotic fruit harvesting
Jun 16, 2023Interest in agricultural robotics has increased considerably in recent years due to benefits such as improvement in productivity and labor reduction. However, current problems associated with unstructured environments make the development of robotic harvesters challenging. Most research in agricultural robotics focuses on single arm manipulation. Here, we propose a dual-arm approach. We present a dual-arm fruit harvesting robot equipped with a RGB-D camera, cutting and collecting tools. We exploit the cooperative task description to maximize the capabilities of the dual-arm robot. We designed a Hierarchical Quadratic Programming based control strategy to fulfill the set of hard constrains related to the robot and environment: robot joint limits, robot self-collisions, robot-fruit and robot-tree collisions. We combine deep learning and standard image processing algorithms to detect and track fruits as well as the tree trunk in the scene. We validate our perception methods on real-world RGB-D images and our control method on simulated experiments.
Variable Grasp Pose and Commitment for Trajectory Optimization
May 21, 2023



We propose enhancing trajectory optimization methods through the incorporation of two key ideas: variable-grasp pose sampling and trajectory commitment. Our iterative approach samples multiple grasp poses, increasing the likelihood of finding a solution while gradually narrowing the optimization horizon towards the goal region for improved computational efficiency. We conduct experiments comparing our approach with sampling-based planning and fixed-goal optimization. In simulated experiments featuring 4 different task scenes, our approach consistently outperforms baselines by generating lower-cost trajectories and achieving higher success rates in challenging constrained and cluttered environments, at the trade-off of longer computation times. Real-world experiments further validate the superiority of our approach in generating lower-cost trajectories and exhibiting enhanced robustness. While we acknowledge the limitations of our experimental design, our proposed approach holds significant potential for enhancing trajectory optimization methods and offers a promising solution for achieving consistent and reliable robotic manipulation.
Robot Gaze During Autonomous Navigation and its Effect on Social Presence
May 10, 2023As robots have become increasingly common in human-rich environments, it is critical that they are able to exhibit social cues to be perceived as a cooperative and socially-conformant team member. We investigate the effect of robot gaze cues on people's subjective perceptions of a mobile robot as a socially present entity in three common hallway navigation scenarios. The tested robot gaze behaviors were path-oriented (looking at its own future path), or person-oriented (looking at the nearest person), with fixed-gaze as the control. We conduct a real-world study with 36 participants who walked through the hallway, and an online study with 233 participants who were shown simulated videos of the same scenarios. Our results suggest that the preferred gaze behavior is scenario-dependent. Person-oriented gaze behaviors which acknowledge the presence of the human are generally preferred when the robot and human cross paths. However, this benefit is diminished in scenarios that involve less implicit interaction between the robot and the human.
A Benchmark for Cycling Close Pass Near Miss Event Detection from Video Streams
Apr 24, 2023



Cycling is a healthy and sustainable mode of transport. However, interactions with motor vehicles remain a key barrier to increased cycling participation. The ability to detect potentially dangerous interactions from on-bike sensing could provide important information to riders and policy makers. Thus, automated detection of conflict between cyclists and drivers has attracted researchers from both computer vision and road safety communities. In this paper, we introduce a novel benchmark, called Cyc-CP, towards cycling close pass near miss event detection from video streams. We first divide this task into scene-level and instance-level problems. Scene-level detection asks an algorithm to predict whether there is a close pass near miss event in the input video clip. Instance-level detection aims to detect which vehicle in the scene gives rise to a close pass near miss. We propose two benchmark models based on deep learning techniques for these two problems. For training and testing those models, we construct a synthetic dataset and also collect a real-world dataset. Our models can achieve 88.13% and 84.60% accuracy on the real-world dataset, respectively. We envision this benchmark as a test-bed to accelerate cycling close pass near miss detection and facilitate interaction between the fields of road safety, intelligent transportation systems and artificial intelligence. Both the benchmark datasets and detection models will be available at https://github.com/SustainableMobility/cyc-cp to facilitate experimental reproducibility and encourage more in-depth research in the field.
Rotating Objects via In-Hand Pivoting using Vision, Force and Touch
Mar 21, 2023



We propose a robotic manipulation system that can pivot objects on a surface using vision, wrist force and tactile sensing. We aim to control the rotation of an object around the grip point of a parallel gripper by allowing rotational slip, while maintaining a desired wrist force profile. Our approach runs an end-effector position controller and a gripper width controller concurrently in a closed loop. The position controller maintains a desired force using vision and wrist force. The gripper controller uses tactile sensing to keep the grip firm enough to prevent translational slip, but loose enough to induce rotational slip. Our sensor-based control approach relies on matching a desired force profile derived from object dimensions and weight and vision-based monitoring of the object pose. The gripper controller uses tactile sensors to detect and prevent translational slip by tightening the grip when needed. Experimental results where the robot was tasked with rotating cuboid objects 90 degrees show that the multi-modal pivoting approach was able to rotate the objects without causing lift or slip, and was more energy-efficient compared to using a single sensor modality and to pick-and-place. While our work demonstrated the benefit of multi-modal sensing for the pivoting task, further work is needed to generalize our approach to any given object.
Crafting with a Robot Assistant: Use Social Cues to Inform Adaptive Handovers in Human-Robot Collaboration
Jan 07, 2023



We study human-robot handovers in a naturalistic collaboration scenario, where a mobile manipulator robot assists a person during a crafting session by providing and retrieving objects used for wooden piece assembly (functional activities) and painting (creative activities). We collect quantitative and qualitative data from 20 participants in a Wizard-of-Oz study, generating the Functional And Creative Tasks Human-Robot Collaboration dataset (the FACT HRC dataset), available to the research community. This work illustrates how social cues and task context inform the temporal-spatial coordination in human-robot handovers, and how human-robot collaboration is shaped by and in turn influences people's functional and creative activities.
Comparing Subjective Perceptions of Robot-to-Human Handover Trajectories
Nov 16, 2022



Robots must move legibly around people for safety reasons, especially for tasks where physical contact is possible. One such task is handovers, which requires implicit communication on where and when physical contact (object transfer) occurs. In this work, we study whether the trajectory model used by a robot during the reaching phase affects the subjective perceptions of receivers for robot-to-human handovers. We conducted a user study where 32 participants were handed over three objects with four trajectory models: three were versions of a minimum jerk trajectory, and one was an ellipse-fitting-based trajectory. The start position of the handover was fixed for all trajectories, and the end position was allowed to vary randomly around a fixed position by $\pm$3 cm in all axis. The user study found no significant differences among the handover trajectories in survey questions relating to safety, predictability, naturalness, and other subjective metrics. While these results seemingly reject the hypothesis that the trajectory affects human perceptions of a handover, it prompts future research to investigate the effect of other variables, such as robot speed, object transfer position, object orientation at the transfer point, and explicit communication signals such as gaze and speech.
In-Hand Gravitational Pivoting Using Tactile Sensing
Oct 11, 2022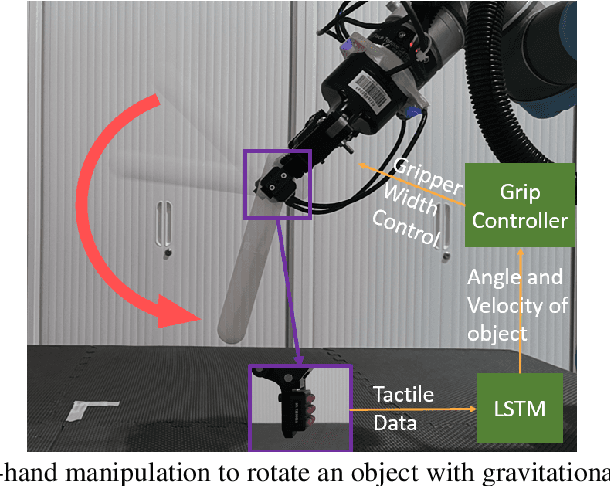
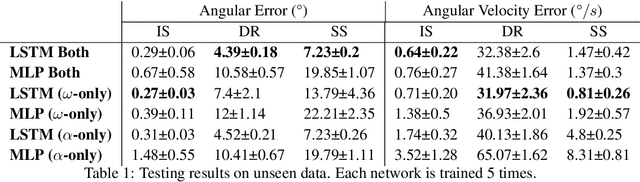
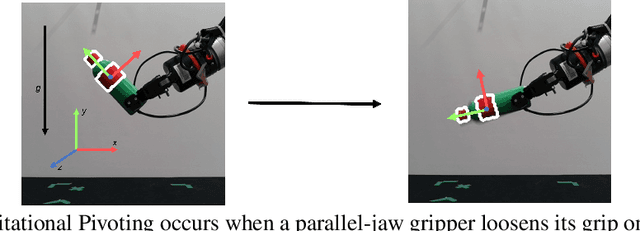
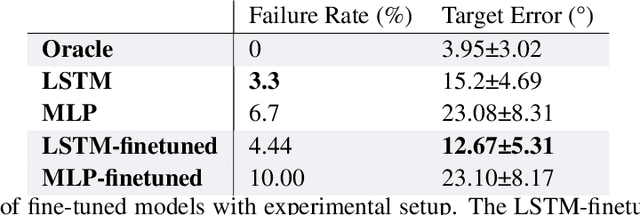
We study gravitational pivoting, a constrained version of in-hand manipulation, where we aim to control the rotation of an object around the grip point of a parallel gripper. To achieve this, instead of controlling the gripper to avoid slip, we embrace slip to allow the object to rotate in-hand. We collect two real-world datasets, a static tracking dataset and a controller-in-the loop dataset, both annotated with object angle and angular velocity labels. Both datasets contain force-based tactile information on ten different household objects. We train an LSTM model to predict the angular position and velocity of the held object from purely tactile data. We integrate this model with a controller that opens and closes the gripper allowing the object to rotate to desired relative angles. We conduct real-world experiments where the robot is tasked to achieve a relative target angle. We show that our approach outperforms a sliding-window based MLP in a zero-shot generalization setting with unseen objects. Furthermore, we show a 16.6% improvement in performance when the LSTM model is fine-tuned on a small set of data collected with both the LSTM model and the controller in-the-loop. Code and videos are available at https://rhys-newbury.github.io/projects/pivoting/
Deep Learning Approaches to Grasp Synthesis: A Review
Jul 06, 2022


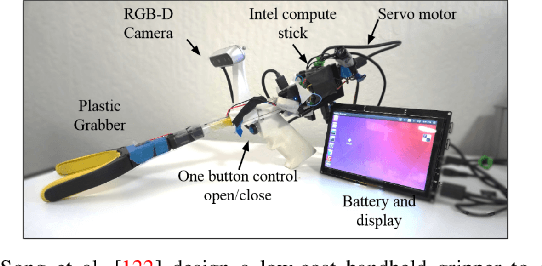
Grasping is the process of picking an object by applying forces and torques at a set of contacts. Recent advances in deep-learning methods have allowed rapid progress in robotic object grasping. We systematically surveyed the publications over the last decade, with a particular interest in grasping an object using all 6 degrees of freedom of the end-effector pose. Our review found four common methodologies for robotic grasping: sampling-based approaches, direct regression, reinforcement learning, and exemplar approaches. Furthermore, we found two 'supporting methods' around grasping that use deep-learning to support the grasping process, shape approximation, and affordances. We have distilled the publications found in this systematic review (85 papers) into ten key takeaways we consider crucial for future robotic grasping and manipulation research. An online version of the survey is available at https://rhys-newbury.github.io/projects/6dof/
Integrating High-Resolution Tactile Sensing into Grasp Stability Prediction
Jun 12, 2022

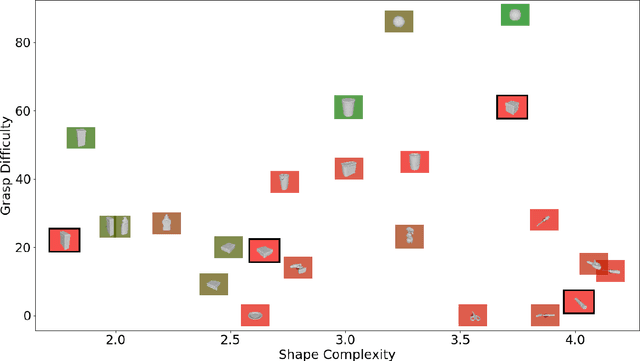
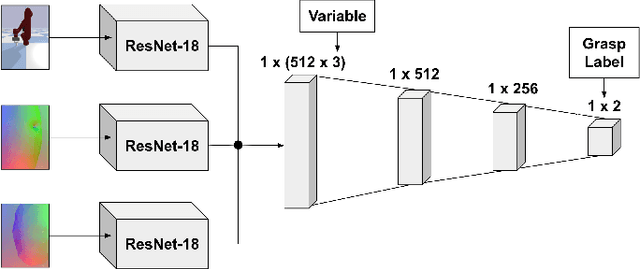
We investigate how high-resolution tactile sensors can be utilized in combination with vision and depth sensing, to improve grasp stability prediction. Recent advances in simulating high-resolution tactile sensing, in particular the TACTO simulator, enabled us to evaluate how neural networks can be trained with a combination of sensing modalities. With the large amounts of data needed to train large neural networks, robotic simulators provide a fast way to automate the data collection process. We expand on the existing work through an ablation study and an increased set of objects taken from the YCB benchmark set. Our results indicate that while the combination of vision, depth, and tactile sensing provides the best prediction results on known objects, the network fails to generalize to unknown objects. Our work also addresses existing issues with robotic grasping in tactile simulation and how to overcome them.