 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Survey on Generative Diffusion Model
Sep 12, 2022
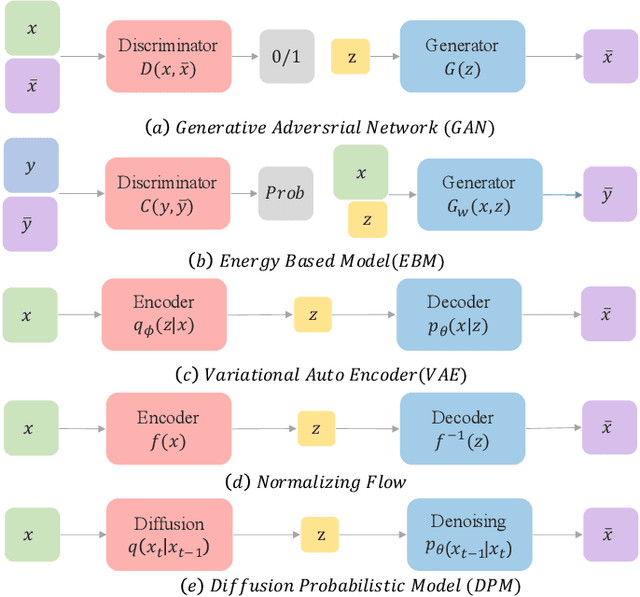
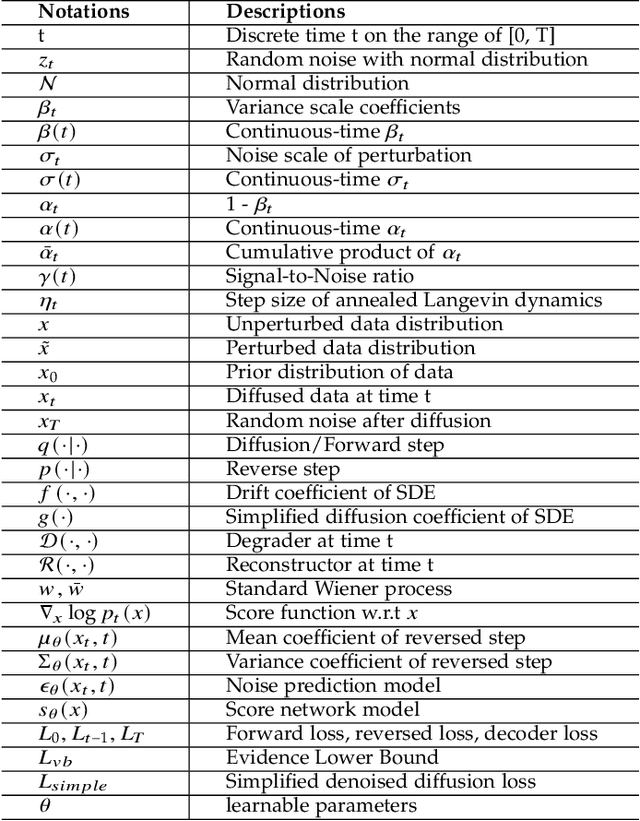
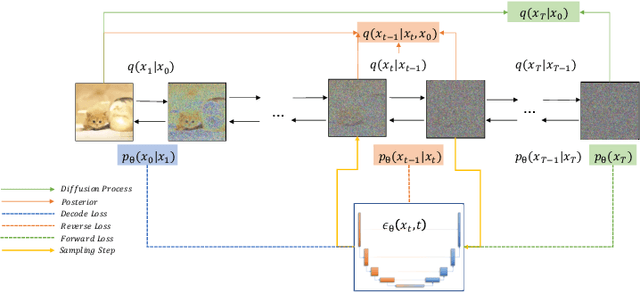
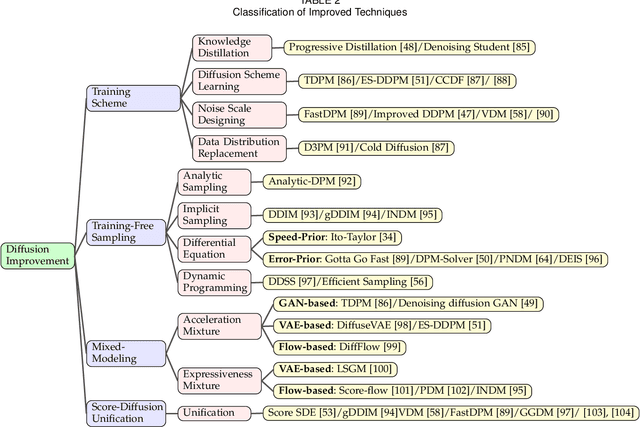
Deep learning shows great potential in generation tasks thanks to deep latent representation. Generative models are classes of models that can generate observations randomly with respect to certain implied parameters. Recently, the diffusion Model becomes a raising class of generative models by virtue of its power-generating ability. Nowadays, great achievements have been reached. More applications except for computer vision, speech generation, bioinformatics, and natural language processing are to be explored in this field. However, the diffusion model has its natural drawback of a slow generation process, leading to many enhanced works. This survey makes a summary of the field of the diffusion model. We firstly state the main problem with two landmark works - DDPM and DSM. Then, we present a diverse range of advanced techniques to speed up the diffusion models - training schedule, training-free sampling, mixed-modeling, and score & diffusion unification. Regarding existing models, we also provide a benchmark of FID score, IS, and NLL according to specific NFE. Moreover, applications with diffusion models are introduced including computer vision, sequence modeling, audio, and AI for science. Finally, there is a summarization of this field together with limitations & further directions.
A Language Agnostic Multilingual Streaming On-Device ASR System
Aug 29, 2022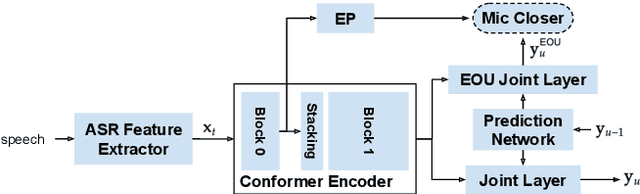
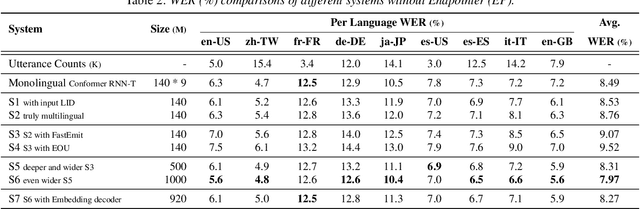
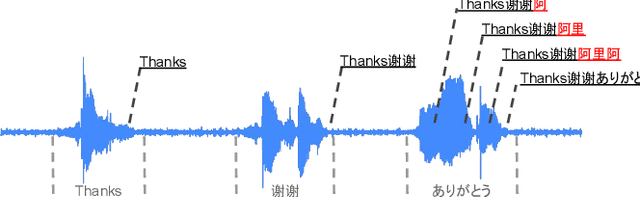
On-device end-to-end (E2E) models have shown improvements over a conventional model on English Voice Search tasks in both quality and latency. E2E models have also shown promising results for multilingual automatic speech recognition (ASR). In this paper, we extend our previous capacity solution to streaming applications and present a streaming multilingual E2E ASR system that runs fully on device with comparable quality and latency to individual monolingual models. To achieve that, we propose an Encoder Endpointer model and an End-of-Utterance (EOU) Joint Layer for a better quality and latency trade-off. Our system is built in a language agnostic manner allowing it to natively support intersentential code switching in real time. To address the feasibility concerns on large models, we conducted on-device profiling and replaced the time consuming LSTM decoder with the recently developed Embedding decoder. With these changes, we managed to run such a system on a mobile device in less than real time.
Convolutive Prediction for Reverberant Speech Separation
Aug 16, 2021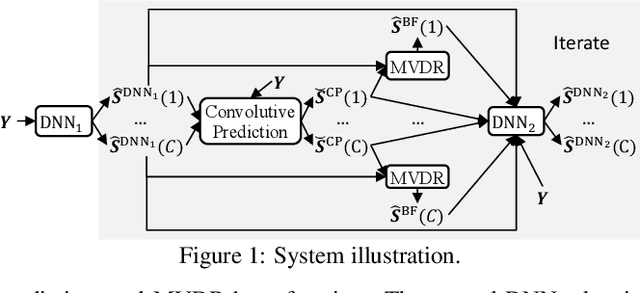
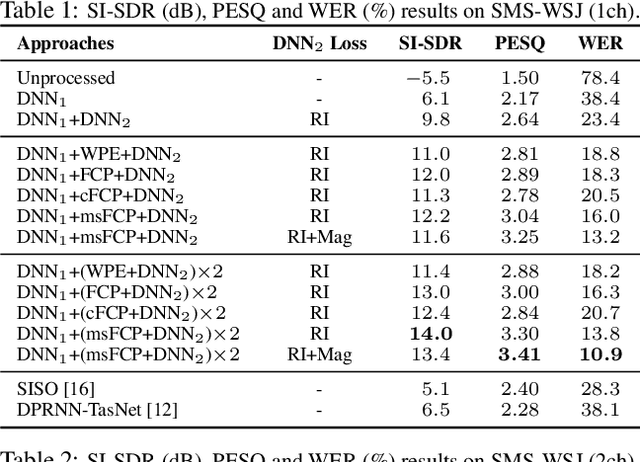
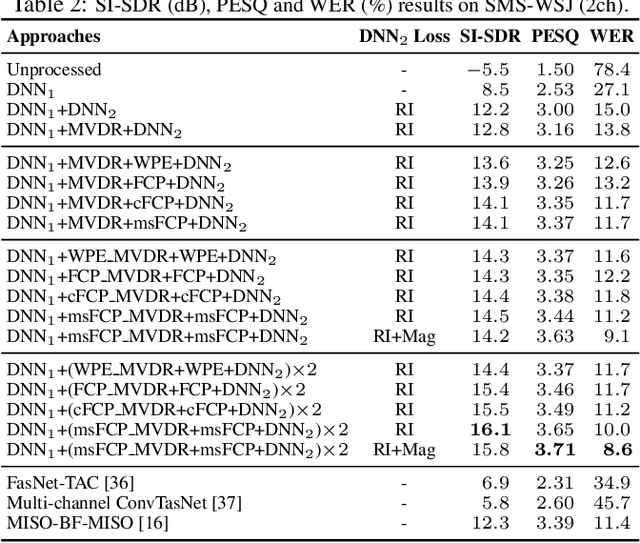
We investigate the effectiveness of convolutive prediction, a novel formulation of linear prediction for speech dereverberation, for speaker separation in reverberant conditions. The key idea is to first use a deep neural network (DNN) to estimate the direct-path signal of each speaker, and then identify delayed and decayed copies of the estimated direct-path signal. Such copies are likely due to reverberation, and can be directly removed for dereverberation or used as extra features for another DNN to perform better dereverberation and separation. To identify such copies, we solve a linear regression problem per frequency efficiently in the time-frequency (T-F) domain to estimate the underlying room impulse response (RIR). In the multi-channel extension, we perform minimum variance distortionless response (MVDR) beamforming on the outputs of convolutive prediction. The beamforming and dereverberation results are used as extra features for a second DNN to perform better separation and dereverberation. State-of-the-art results are obtained on the SMS-WSJ corpus.
TMGAN-PLC: Audio Packet Loss Concealment using Temporal Memory Generative Adversarial Network
Jul 04, 2022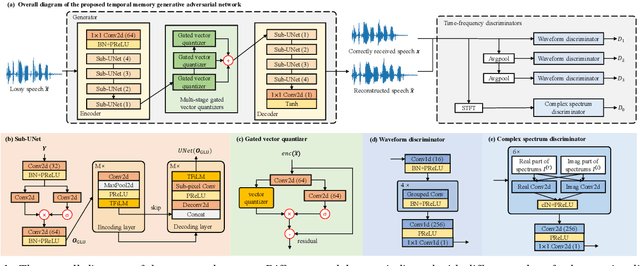
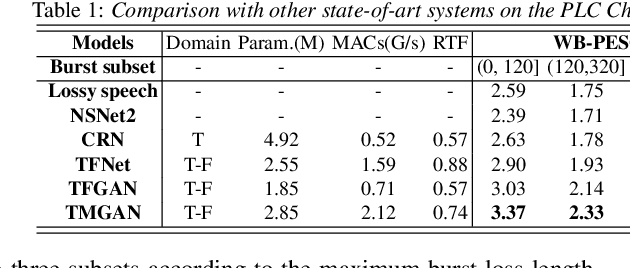
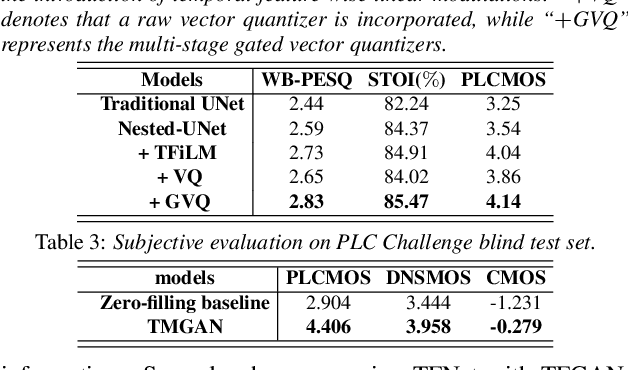
Real-time communications in packet-switched networks have become widely used in daily communication, while they inevitably suffer from network delays and data losses in constrained real-time conditions. To solve these problems, audio packet loss concealment (PLC) algorithms have been developed to mitigate voice transmission failures by reconstructing the lost information. Limited by the transmission latency and device memory, it is still intractable for PLC to accomplish high-quality voice reconstruction using a relatively small packet buffer. In this paper, we propose a temporal memory generative adversarial network for audio PLC, dubbed TMGAN-PLC, which is comprised of a novel nested-UNet generator and the time-domain/frequency-domain discriminators. Specifically, a combination of the nested-UNet and temporal feature-wise linear modulation is elaborately devised in the generator to finely adjust the intra-frame information and establish inter-frame temporal dependencies. To complement the missing speech content caused by longer loss bursts, we employ multi-stage gated vector quantizers to capture the correct content and reconstruct the near-real smooth audio. Extensive experiments on the PLC Challenge dataset demonstrate that the proposed method yields promising performance in terms of speech quality, intelligibility, and PLCMOS.
Distilling the Knowledge of BERT for CTC-based ASR
Sep 05, 2022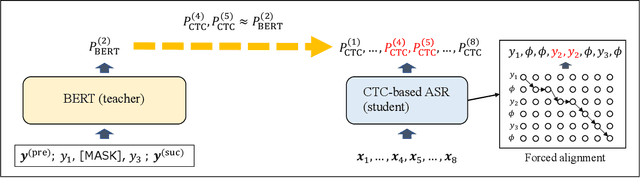
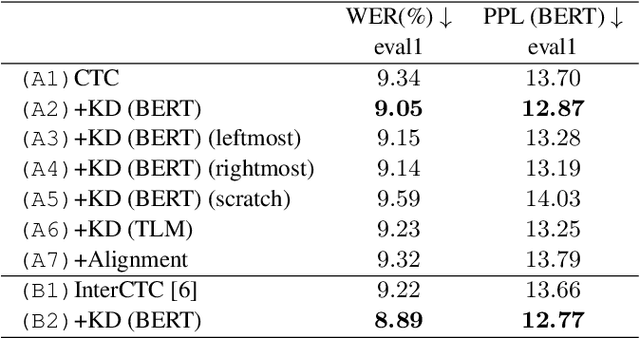
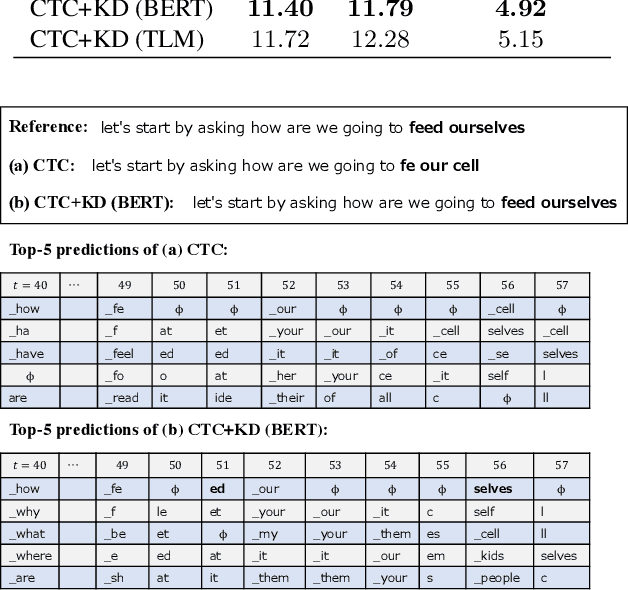
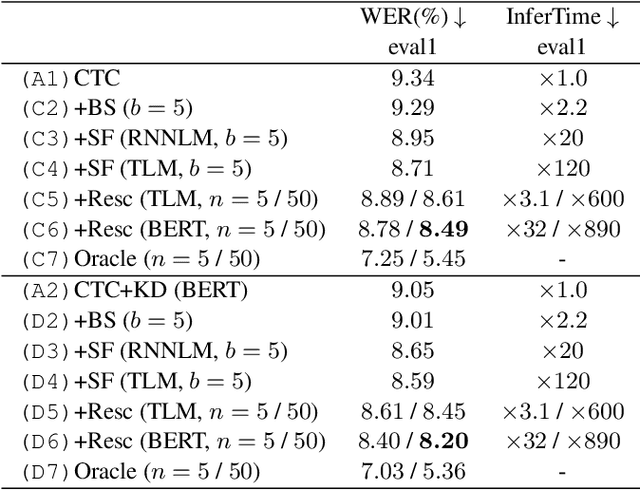
Connectionist temporal classification (CTC) -based models are attractive because of their fast inference in automatic speech recognition (ASR). Language model (LM) integration approaches such as shallow fusion and rescoring can improve the recognition accuracy of CTC-based ASR by taking advantage of the knowledge in text corpora. However, they significantly slow down the inference of CTC. In this study, we propose to distill the knowledge of BERT for CTC-based ASR, extending our previous study for attention-based ASR. CTC-based ASR learns the knowledge of BERT during training and does not use BERT during testing, which maintains the fast inference of CTC. Different from attention-based models, CTC-based models make frame-level predictions, so they need to be aligned with token-level predictions of BERT for distillation. We propose to obtain alignments by calculating the most plausible CTC paths. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 show that our method improves the performance of CTC-based ASR without the cost of inference speed.
Deep Residual Echo Suppression and Noise Reduction: A Multi-Input FCRN Approach in a Hybrid Speech Enhancement System
Aug 06, 2021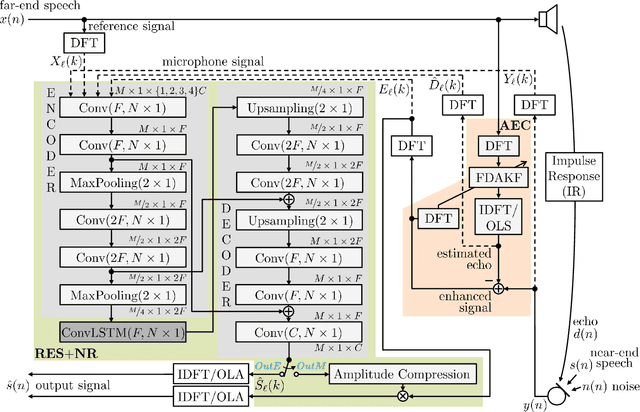
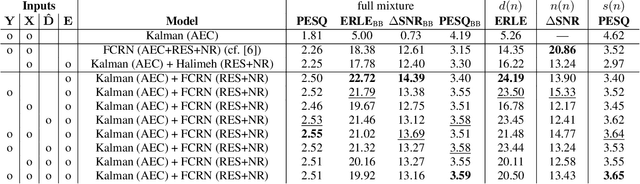
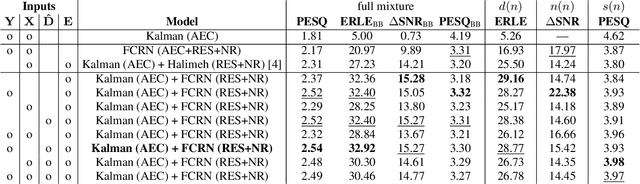
Deep neural network (DNN)-based approaches to acoustic echo cancellation (AEC) and hybrid speech enhancement systems have gained increasing attention recently, introducing significant performance improvements to this research field. Using the fully convolutional recurrent network (FCRN) architecture that is among state of the art topologies for noise reduction, we present a novel deep residual echo suppression and noise reduction with up to four input signals as part of a hybrid speech enhancement system with a linear frequency domain adaptive Kalman filter AEC. In an extensive ablation study, we reveal trade-offs with regard to echo suppression, noise reduction, and near-end speech quality, and provide surprising insights to the choice of the FCRN inputs: In contrast to often seen input combinations for this task, we propose not to use the loudspeaker reference signal, but the enhanced signal after AEC, the microphone signal, and the echo estimate, yielding improvements over previous approaches by more than 0.2 PESQ points.
End-to-End Rich Transcription-Style Automatic Speech Recognition with Semi-Supervised Learning
Jul 07, 2021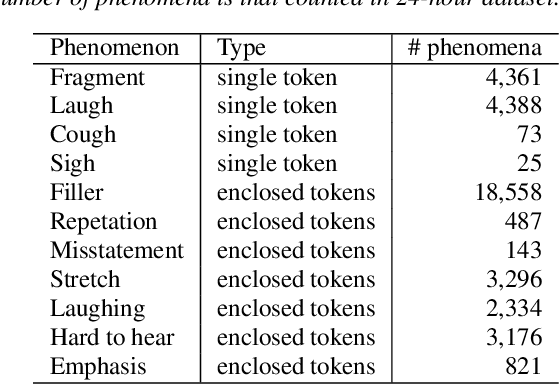
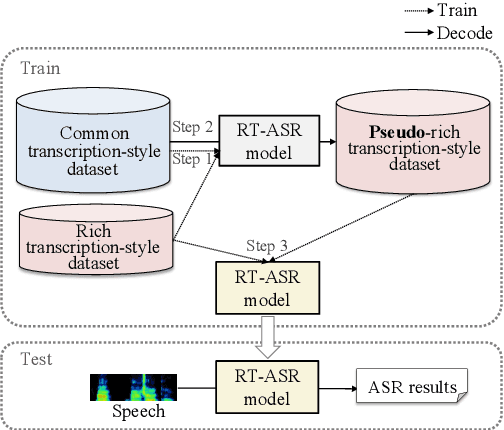
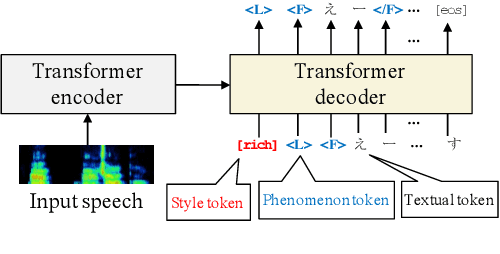
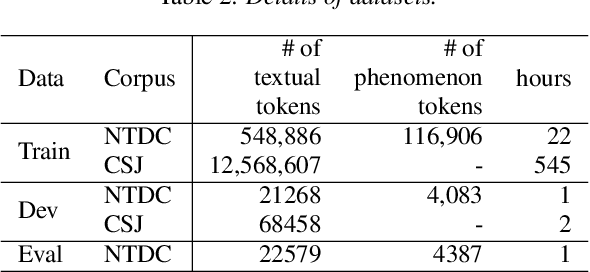
We propose a semi-supervised learning method for building end-to-end rich transcription-style automatic speech recognition (RT-ASR) systems from small-scale rich transcription-style and large-scale common transcription-style datasets. In spontaneous speech tasks, various speech phenomena such as fillers, word fragments, laughter and coughs, etc. are often included. While common transcriptions do not give special awareness to these phenomena, rich transcriptions explicitly convert them into special phenomenon tokens as well as textual tokens. In previous studies, the textual and phenomenon tokens were simultaneously estimated in an end-to-end manner. However, it is difficult to build accurate RT-ASR systems because large-scale rich transcription-style datasets are often unavailable. To solve this problem, our training method uses a limited rich transcription-style dataset and common transcription-style dataset simultaneously. The Key process in our semi-supervised learning is to convert the common transcription-style dataset into a pseudo-rich transcription-style dataset. To this end, we introduce style tokens which control phenomenon tokens are generated or not into transformer-based autoregressive modeling. We use this modeling for generating the pseudo-rich transcription-style datasets and for building RT-ASR system from the pseudo and original datasets. Our experiments on spontaneous ASR tasks showed the effectiveness of the proposed method.
Speaker Identification Experiments Under Gender De-Identification
Mar 09, 2022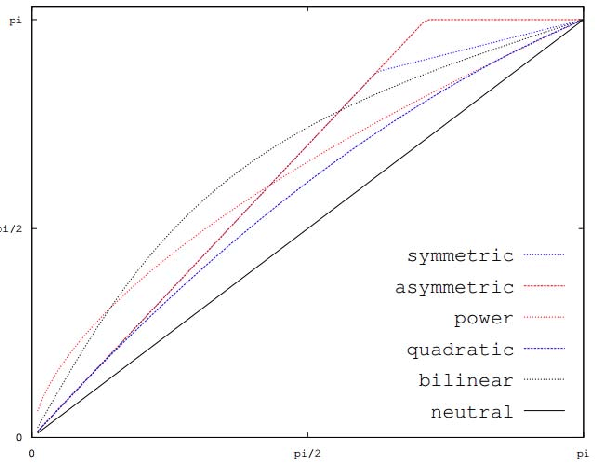
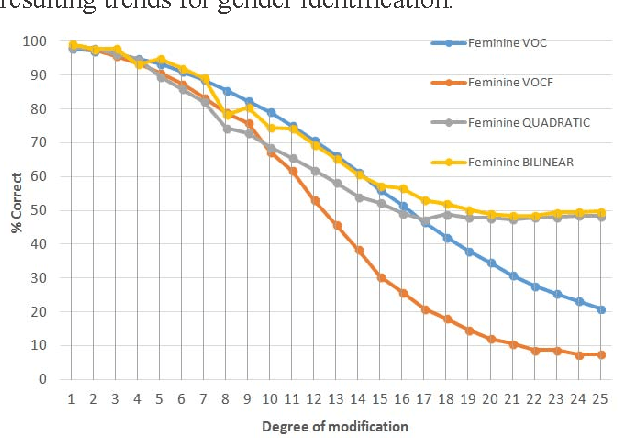
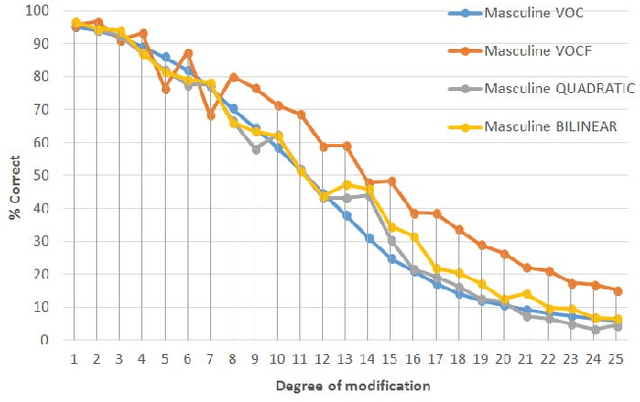
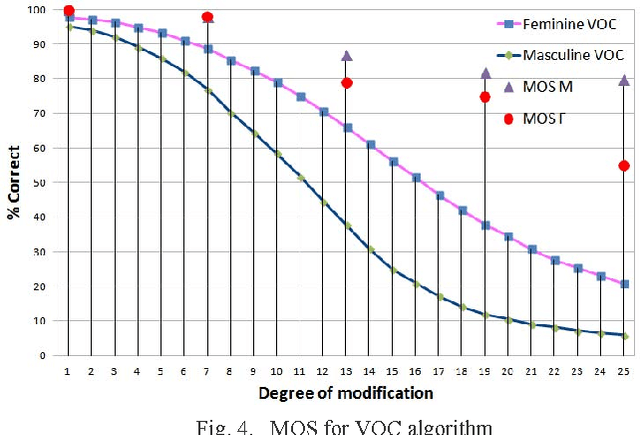
The present work is based on the COST Action IC1206 for De-identification in multimedia content. It was performed to test four algorithms of voice modifications on a speech gender recognizer to find the degree of modification of pitch when the speech recognizer have the probability of success equal to the probability of failure. The purpose of this analysis is to assess the intensity of the speech tone modification, the quality, the reversibility and not-reversibility of the changes made. Keywords DeIdentification; Speech Algorithms
* 5 pages
UPC's Speech Translation System for IWSLT 2021
May 10, 2021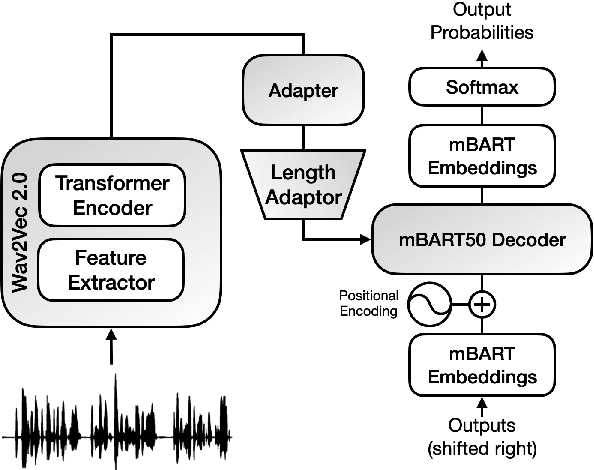

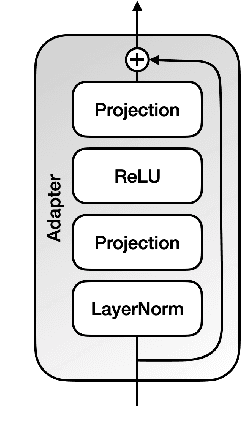
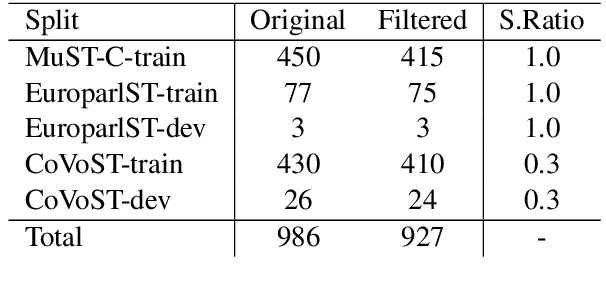
This paper describes the submission to the IWSLT 2021 offline speech translation task by the UPC Machine Translation group. The task consists of building a system capable of translating English audio recordings extracted from TED talks into German text. Submitted systems can be either cascade or end-to-end and use a custom or given segmentation. Our submission is an end-to-end speech translation system, which combines pre-trained models (Wav2Vec 2.0 and mBART) with coupling modules between the encoder and decoder, and uses an efficient fine-tuning technique, which trains only 20% of its total parameters. We show that adding an Adapter to the system and pre-training it, can increase the convergence speed and the final result, with which we achieve a BLEU score of 27.3 on the MuST-C test set. Our final model is an ensemble that obtains 28.22 BLEU score on the same set. Our submission also uses a custom segmentation algorithm that employs pre-trained Wav2Vec 2.0 for identifying periods of untranscribable text and can bring improvements of 2.5 to 3 BLEU score on the IWSLT 2019 test set, as compared to the result with the given segmentation.
Domain Adversarial Neural Networks for Dysarthric Speech Recognition
Oct 07, 2020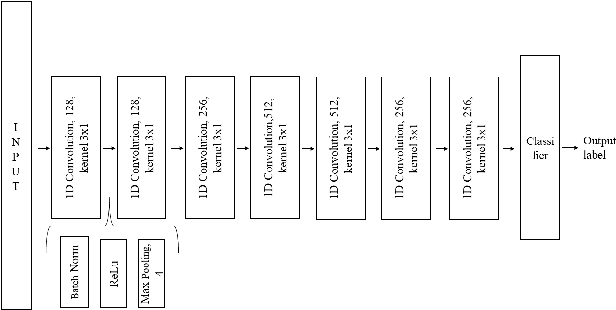
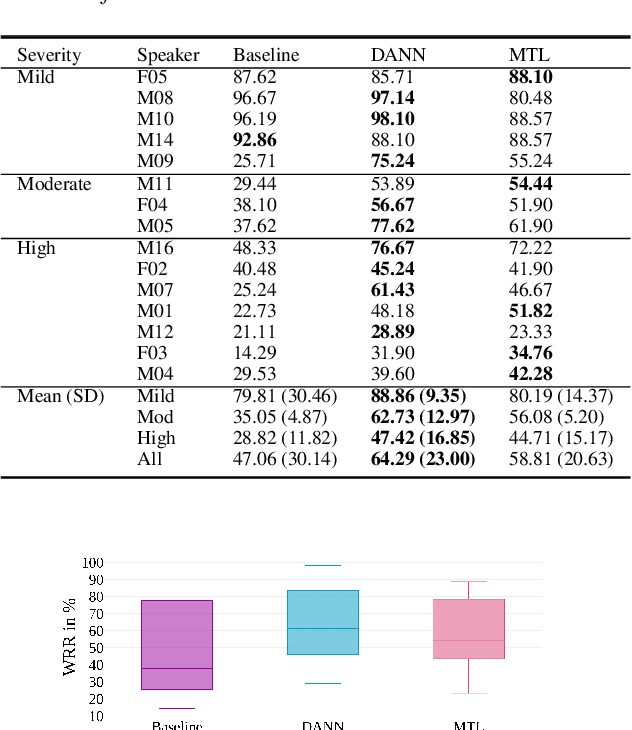
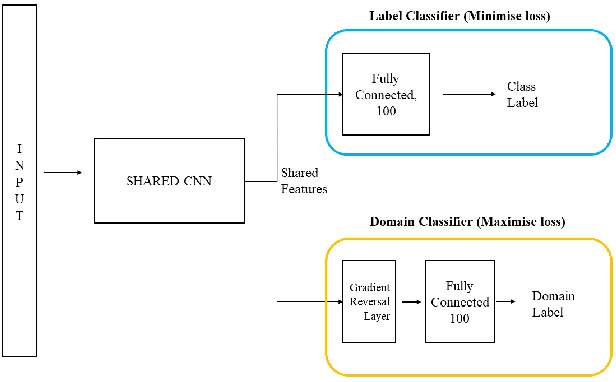
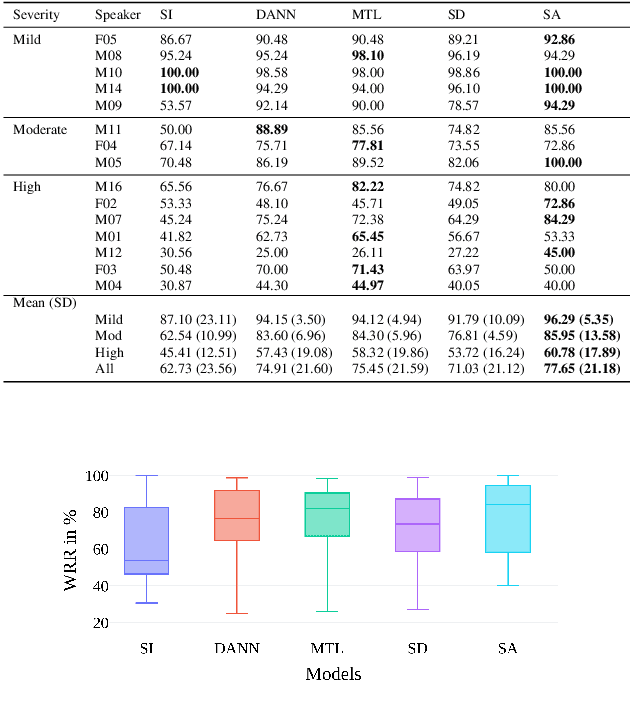
Speech recognition systems have improved dramatically over the last few years, however, their performance is significantly degraded for the cases of accented or impaired speech. This work explores domain adversarial neural networks (DANN) for speaker-independent speech recognition on the UAS dataset of dysarthric speech. The classification task on 10 spoken digits is performed using an end-to-end CNN taking raw audio as input. The results are compared to a speaker-adaptive (SA) model as well as speaker-dependent (SD) and multi-task learning models (MTL). The experiments conducted in this paper show that DANN achieves an absolute recognition rate of 74.91% and outperforms the baseline by 12.18%. Additionally, the DANN model achieves comparable results to the SA model's recognition rate of 77.65%. We also observe that when labelled dysarthric speech data is available DANN and MTL perform similarly, but when they are not DANN performs better than MTL.