 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifference Vector Equalization for Robust Fine-tuning of Vision-Language Models
Nov 13, 2025



Contrastive pre-trained vision-language models, such as CLIP, demonstrate strong generalization abilities in zero-shot classification by leveraging embeddings extracted from image and text encoders. This paper aims to robustly fine-tune these vision-language models on in-distribution (ID) data without compromising their generalization abilities in out-of-distribution (OOD) and zero-shot settings. Current robust fine-tuning methods tackle this challenge by reusing contrastive learning, which was used in pre-training, for fine-tuning. However, we found that these methods distort the geometric structure of the embeddings, which plays a crucial role in the generalization of vision-language models, resulting in limited OOD and zero-shot performance. To address this, we propose Difference Vector Equalization (DiVE), which preserves the geometric structure during fine-tuning. The idea behind DiVE is to constrain difference vectors, each of which is obtained by subtracting the embeddings extracted from the pre-trained and fine-tuning models for the same data sample. By constraining the difference vectors to be equal across various data samples, we effectively preserve the geometric structure. Therefore, we introduce two losses: average vector loss (AVL) and pairwise vector loss (PVL). AVL preserves the geometric structure globally by constraining difference vectors to be equal to their weighted average. PVL preserves the geometric structure locally by ensuring a consistent multimodal alignment. Our experiments demonstrate that DiVE effectively preserves the geometric structure, achieving strong results across ID, OOD, and zero-shot metrics.
Joint Modeling of Big Five and HEXACO for Multimodal Apparent Personality-trait Recognition
Oct 16, 2025



This paper proposes a joint modeling method of the Big Five, which has long been studied, and HEXACO, which has recently attracted attention in psychology, for automatically recognizing apparent personality traits from multimodal human behavior. Most previous studies have used the Big Five for multimodal apparent personality-trait recognition. However, no study has focused on apparent HEXACO which can evaluate an Honesty-Humility trait related to displaced aggression and vengefulness, social-dominance orientation, etc. In addition, the relationships between the Big Five and HEXACO when modeled by machine learning have not been clarified. We expect awareness of multimodal human behavior to improve by considering these relationships. The key advance of our proposed method is to optimize jointly recognizing the Big Five and HEXACO. Experiments using a self-introduction video dataset demonstrate that the proposed method can effectively recognize the Big Five and HEXACO.
Few-shot Personalization via In-Context Learning for Speech Emotion Recognition based on Speech-Language Model
Sep 10, 2025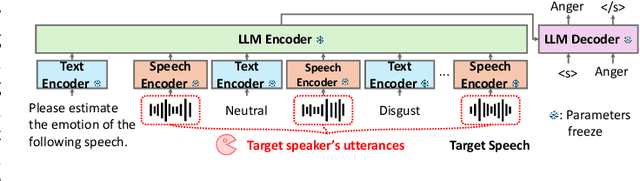
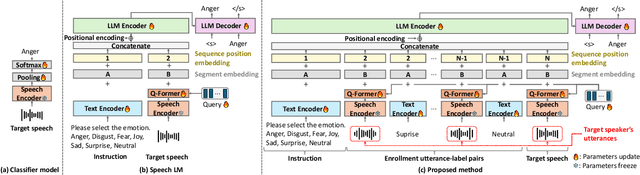
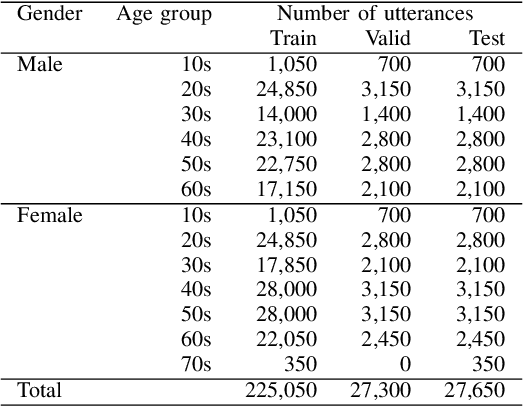
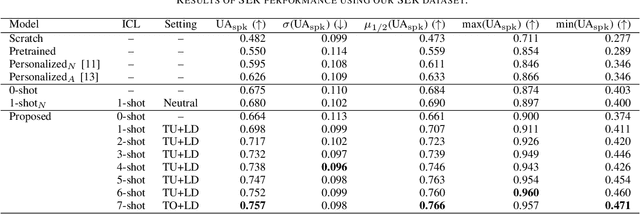
This paper proposes a personalization method for speech emotion recognition (SER) through in-context learning (ICL). Since the expression of emotions varies from person to person, speaker-specific adaptation is crucial for improving the SER performance. Conventional SER methods have been personalized using emotional utterances of a target speaker, but it is often difficult to prepare utterances corresponding to all emotion labels in advance. Our idea to overcome this difficulty is to obtain speaker characteristics by conditioning a few emotional utterances of the target speaker in ICL-based inference. ICL is a method to perform unseen tasks by conditioning a few input-output examples through inference in large language models (LLMs). We meta-train a speech-language model extended from the LLM to learn how to perform personalized SER via ICL. Experimental results using our newly collected SER dataset demonstrate that the proposed method outperforms conventional methods.
Audio Visual Scene-Aware Dialog Generation with Transformer-based Video Representations
Feb 21, 2022
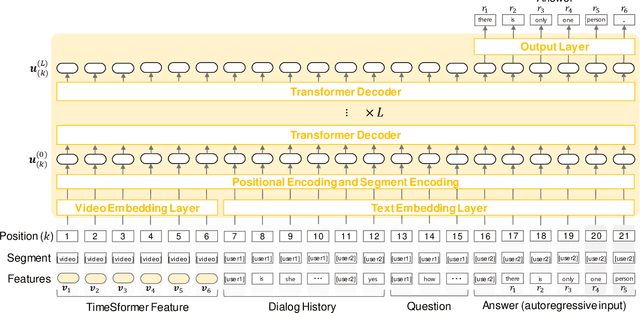
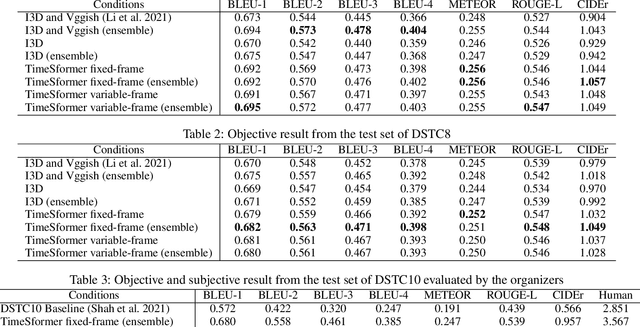
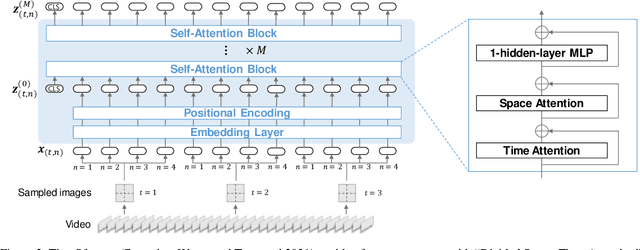
There have been many attempts to build multimodal dialog systems that can respond to a question about given audio-visual information, and the representative task for such systems is the Audio Visual Scene-Aware Dialog (AVSD). Most conventional AVSD models adopt the Convolutional Neural Network (CNN)-based video feature extractor to understand visual information. While a CNN tends to obtain both temporally and spatially local information, global information is also crucial for boosting video understanding because AVSD requires long-term temporal visual dependency and whole visual information. In this study, we apply the Transformer-based video feature that can capture both temporally and spatially global representations more efficiently than the CNN-based feature. Our AVSD model with its Transformer-based feature attains higher objective performance scores for answer generation. In addition, our model achieves a subjective score close to that of human answers in DSTC10. We observed that the Transformer-based visual feature is beneficial for the AVSD task because our model tends to correctly answer the questions that need a temporally and spatially broad range of visual information.
Utilizing Resource-Rich Language Datasets for End-to-End Scene Text Recognition in Resource-Poor Languages
Nov 24, 2021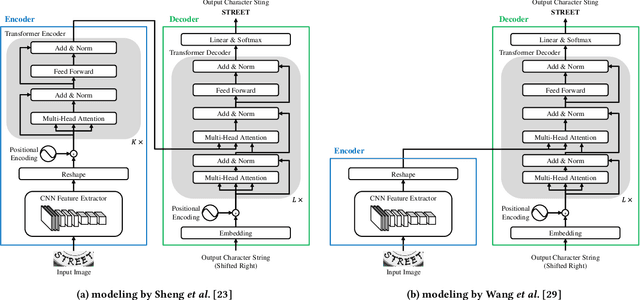
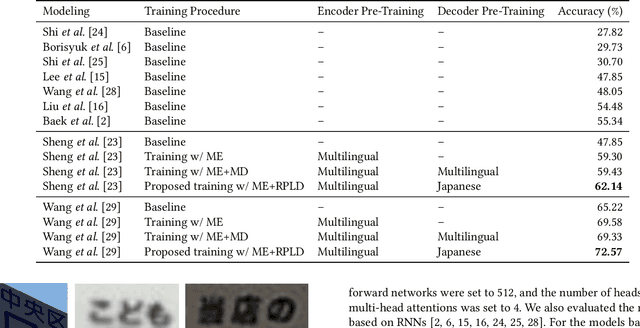
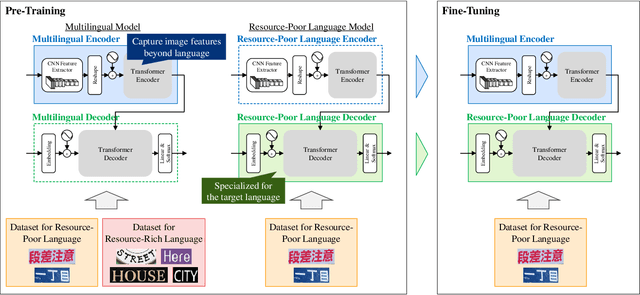
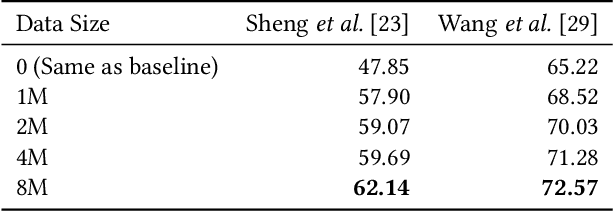
This paper presents a novel training method for end-to-end scene text recognition. End-to-end scene text recognition offers high recognition accuracy, especially when using the encoder-decoder model based on Transformer. To train a highly accurate end-to-end model, we need to prepare a large image-to-text paired dataset for the target language. However, it is difficult to collect this data, especially for resource-poor languages. To overcome this difficulty, our proposed method utilizes well-prepared large datasets in resource-rich languages such as English, to train the resource-poor encoder-decoder model. Our key idea is to build a model in which the encoder reflects knowledge of multiple languages while the decoder specializes in knowledge of just the resource-poor language. To this end, the proposed method pre-trains the encoder by using a multilingual dataset that combines the resource-poor language's dataset and the resource-rich language's dataset to learn language-invariant knowledge for scene text recognition. The proposed method also pre-trains the decoder by using the resource-poor language's dataset to make the decoder better suited to the resource-poor language. Experiments on Japanese scene text recognition using a small, publicly available dataset demonstrate the effectiveness of the proposed method.
Hierarchical Knowledge Distillation for Dialogue Sequence Labeling
Nov 22, 2021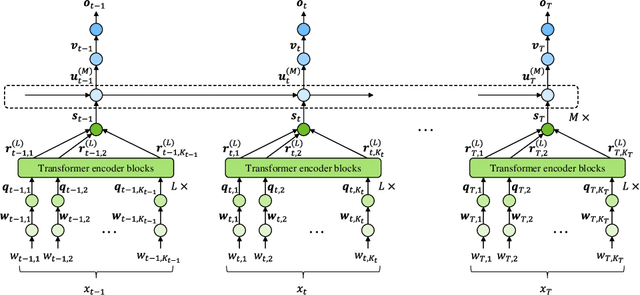
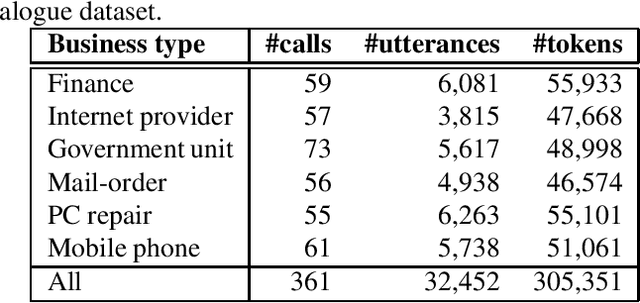
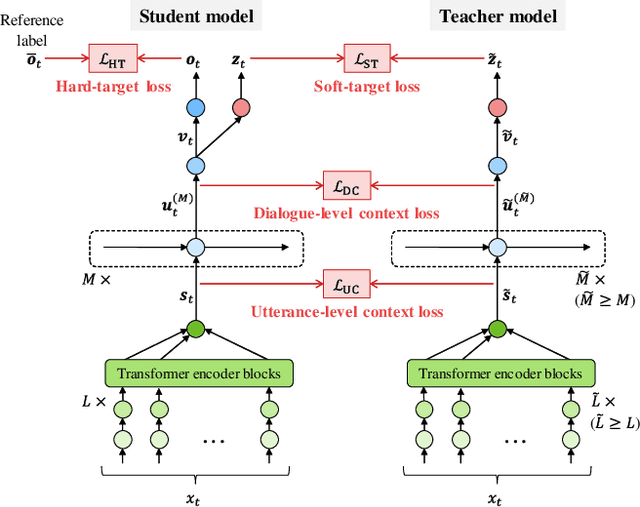
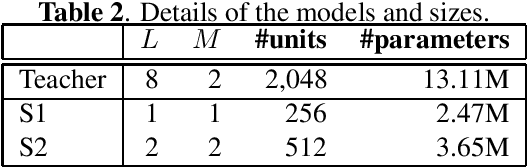
This paper presents a novel knowledge distillation method for dialogue sequence labeling. Dialogue sequence labeling is a supervised learning task that estimates labels for each utterance in the target dialogue document, and is useful for many applications such as dialogue act estimation. Accurate labeling is often realized by a hierarchically-structured large model consisting of utterance-level and dialogue-level networks that capture the contexts within an utterance and between utterances, respectively. However, due to its large model size, such a model cannot be deployed on resource-constrained devices. To overcome this difficulty, we focus on knowledge distillation which trains a small model by distilling the knowledge of a large and high performance teacher model. Our key idea is to distill the knowledge while keeping the complex contexts captured by the teacher model. To this end, the proposed method, hierarchical knowledge distillation, trains the small model by distilling not only the probability distribution of the label classification, but also the knowledge of utterance-level and dialogue-level contexts trained in the teacher model by training the model to mimic the teacher model's output in each level. Experiments on dialogue act estimation and call scene segmentation demonstrate the effectiveness of the proposed method.
End-to-End Rich Transcription-Style Automatic Speech Recognition with Semi-Supervised Learning
Jul 07, 2021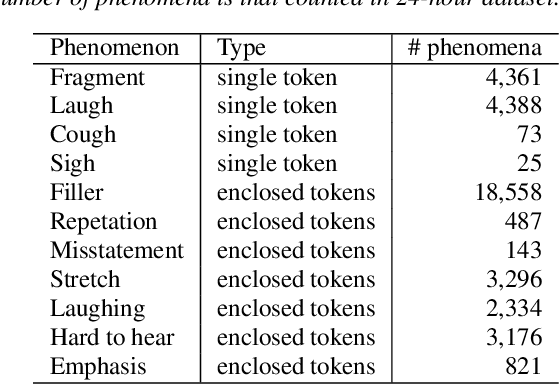
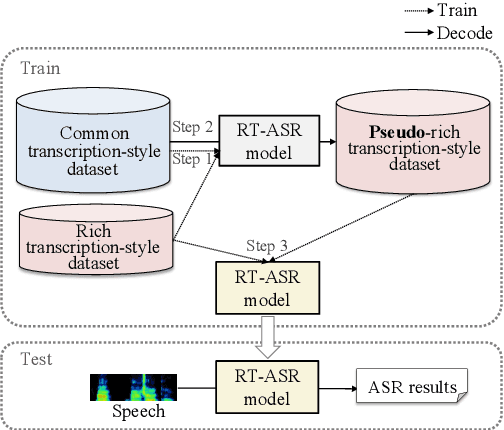
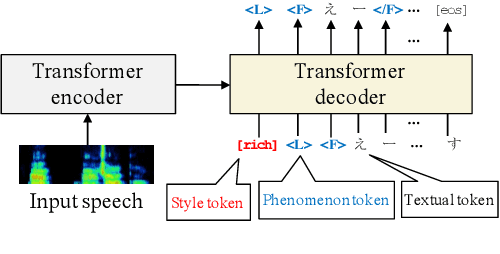
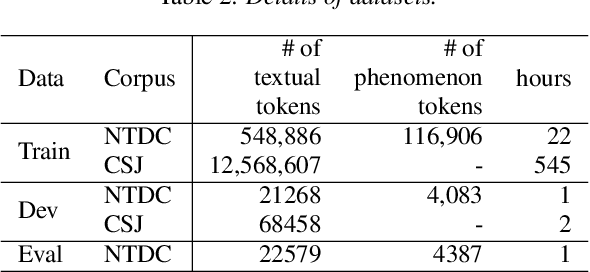
We propose a semi-supervised learning method for building end-to-end rich transcription-style automatic speech recognition (RT-ASR) systems from small-scale rich transcription-style and large-scale common transcription-style datasets. In spontaneous speech tasks, various speech phenomena such as fillers, word fragments, laughter and coughs, etc. are often included. While common transcriptions do not give special awareness to these phenomena, rich transcriptions explicitly convert them into special phenomenon tokens as well as textual tokens. In previous studies, the textual and phenomenon tokens were simultaneously estimated in an end-to-end manner. However, it is difficult to build accurate RT-ASR systems because large-scale rich transcription-style datasets are often unavailable. To solve this problem, our training method uses a limited rich transcription-style dataset and common transcription-style dataset simultaneously. The Key process in our semi-supervised learning is to convert the common transcription-style dataset into a pseudo-rich transcription-style dataset. To this end, we introduce style tokens which control phenomenon tokens are generated or not into transformer-based autoregressive modeling. We use this modeling for generating the pseudo-rich transcription-style datasets and for building RT-ASR system from the pseudo and original datasets. Our experiments on spontaneous ASR tasks showed the effectiveness of the proposed method.
Cross-Modal Transformer-Based Neural Correction Models for Automatic Speech Recognition
Jul 04, 2021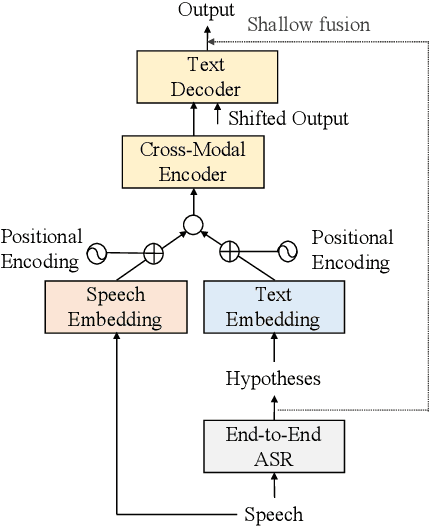
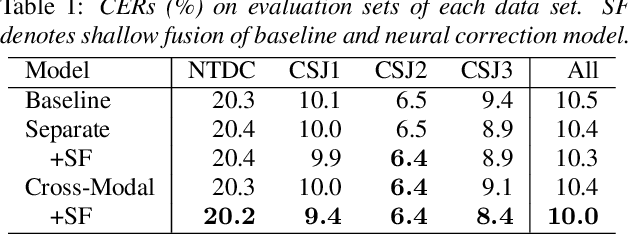
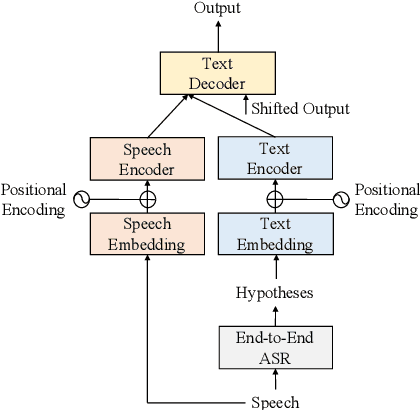
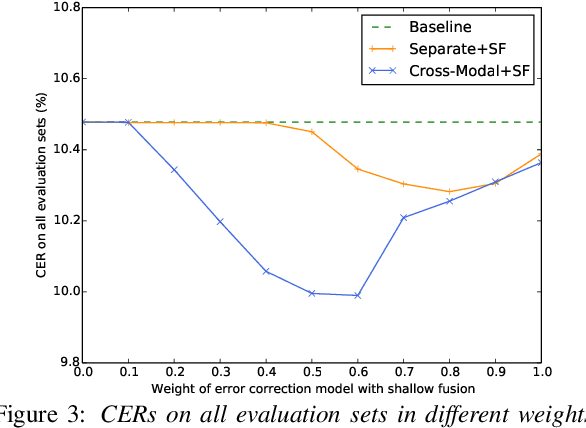
We propose a cross-modal transformer-based neural correction models that refines the output of an automatic speech recognition (ASR) system so as to exclude ASR errors. Generally, neural correction models are composed of encoder-decoder networks, which can directly model sequence-to-sequence mapping problems. The most successful method is to use both input speech and its ASR output text as the input contexts for the encoder-decoder networks. However, the conventional method cannot take into account the relationships between these two different modal inputs because the input contexts are separately encoded for each modal. To effectively leverage the correlated information between the two different modal inputs, our proposed models encode two different contexts jointly on the basis of cross-modal self-attention using a transformer. We expect that cross-modal self-attention can effectively capture the relationships between two different modals for refining ASR hypotheses. We also introduce a shallow fusion technique to efficiently integrate the first-pass ASR model and our proposed neural correction model. Experiments on Japanese natural language ASR tasks demonstrated that our proposed models achieve better ASR performance than conventional neural correction models.
Unified Autoregressive Modeling for Joint End-to-End Multi-Talker Overlapped Speech Recognition and Speaker Attribute Estimation
Jul 04, 2021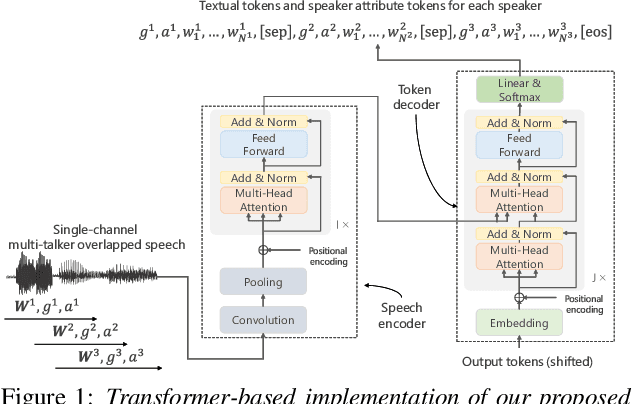
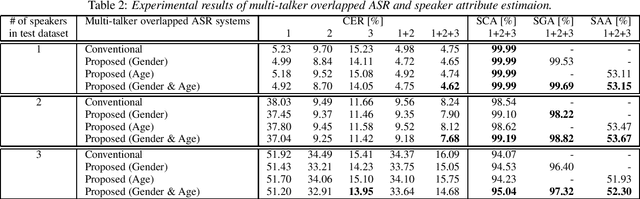
In this paper, we present a novel modeling method for single-channel multi-talker overlapped automatic speech recognition (ASR) systems. Fully neural network based end-to-end models have dramatically improved the performance of multi-taker overlapped ASR tasks. One promising approach for end-to-end modeling is autoregressive modeling with serialized output training in which transcriptions of multiple speakers are recursively generated one after another. This enables us to naturally capture relationships between speakers. However, the conventional modeling method cannot explicitly take into account the speaker attributes of individual utterances such as gender and age information. In fact, the performance deteriorates when each speaker is the same gender or is close in age. To address this problem, we propose unified autoregressive modeling for joint end-to-end multi-talker overlapped ASR and speaker attribute estimation. Our key idea is to handle gender and age estimation tasks within the unified autoregressive modeling. In the proposed method, transformer-based autoregressive model recursively generates not only textual tokens but also attribute tokens of each speaker. This enables us to effectively utilize speaker attributes for improving multi-talker overlapped ASR. Experiments on Japanese multi-talker overlapped ASR tasks demonstrate the effectiveness of the proposed method.
Enrollment-less training for personalized voice activity detection
Jun 23, 2021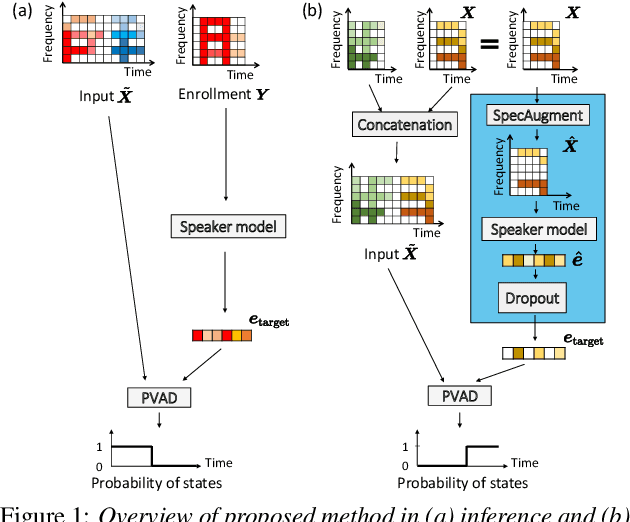
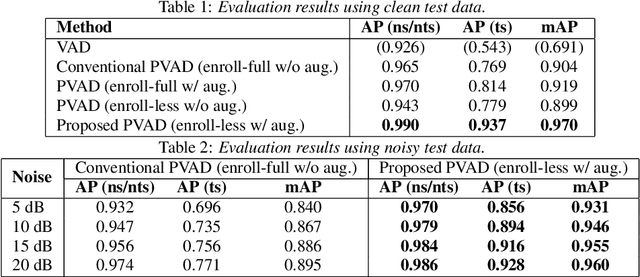
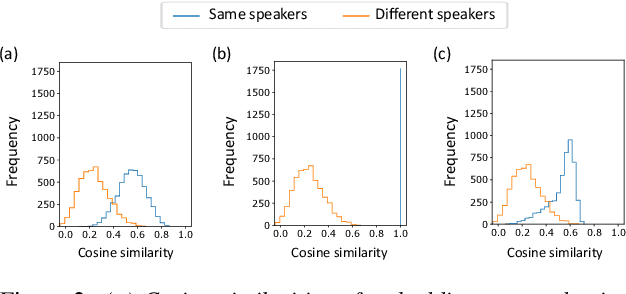
We present a novel personalized voice activity detection (PVAD) learning method that does not require enrollment data during training. PVAD is a task to detect the speech segments of a specific target speaker at the frame level using enrollment speech of the target speaker. Since PVAD must learn speakers' speech variations to clarify the boundary between speakers, studies on PVAD used large-scale datasets that contain many utterances for each speaker. However, the datasets to train a PVAD model are often limited because substantial cost is needed to prepare such a dataset. In addition, we cannot utilize the datasets used to train the standard VAD because they often lack speaker labels. To solve these problems, our key idea is to use one utterance as both a kind of enrollment speech and an input to the PVAD during training, which enables PVAD training without enrollment speech. In our proposed method, called enrollment-less training, we augment one utterance so as to create variability between the input and the enrollment speech while keeping the speaker identity, which avoids the mismatch between training and inference. Our experimental results demonstrate the efficacy of the method.