 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJobResQA: A Benchmark for LLM Machine Reading Comprehension on Multilingual Résumés and JDs
Jan 30, 2026We introduce JobResQA, a multilingual Question Answering benchmark for evaluating Machine Reading Comprehension (MRC) capabilities of LLMs on HR-specific tasks involving résumés and job descriptions. The dataset comprises 581 QA pairs across 105 synthetic résumé-job description pairs in five languages (English, Spanish, Italian, German, and Chinese), with questions spanning three complexity levels from basic factual extraction to complex cross-document reasoning. We propose a data generation pipeline derived from real-world sources through de-identification and data synthesis to ensure both realism and privacy, while controlled demographic and professional attributes (implemented via placeholders) enable systematic bias and fairness studies. We also present a cost-effective, human-in-the-loop translation pipeline based on the TEaR methodology, incorporating MQM error annotations and selective post-editing to ensure an high-quality multi-way parallel benchmark. We provide a baseline evaluations across multiple open-weight LLM families using an LLM-as-judge approach revealing higher performances on English and Spanish but substantial degradation for other languages, highlighting critical gaps in multilingual MRC capabilities for HR applications. JobResQA provides a reproducible benchmark for advancing fair and reliable LLM-based HR systems. The benchmark is publicly available at: https://github.com/Avature/jobresqa-benchmark
Language Modelling for Speaker Diarization in Telephonic Interviews
Jan 28, 2025



The aim of this paper is to investigate the benefit of combining both language and acoustic modelling for speaker diarization. Although conventional systems only use acoustic features, in some scenarios linguistic data contain high discriminative speaker information, even more reliable than the acoustic ones. In this study we analyze how an appropriate fusion of both kind of features is able to obtain good results in these cases. The proposed system is based on an iterative algorithm where a LSTM network is used as a speaker classifier. The network is fed with character-level word embeddings and a GMM based acoustic score created with the output labels from previous iterations. The presented algorithm has been evaluated in a Call-Center database, which is composed of telephone interview audios. The combination of acoustic features and linguistic content shows a 84.29% improvement in terms of a word-level DER as compared to a HMM/VB baseline system. The results of this study confirms that linguistic content can be efficiently used for some speaker recognition tasks.
Pushing the Limits of Zero-shot End-to-End Speech Translation
Feb 16, 2024Data scarcity and the modality gap between the speech and text modalities are two major obstacles of end-to-end Speech Translation (ST) systems, thus hindering their performance. Prior work has attempted to mitigate these challenges by leveraging external MT data and optimizing distance metrics that bring closer the speech-text representations. However, achieving competitive results typically requires some ST data. For this reason, we introduce ZeroSwot, a method for zero-shot ST that bridges the modality gap without any paired ST data. Leveraging a novel CTC compression and Optimal Transport, we train a speech encoder using only ASR data, to align with the representation space of a massively multilingual MT model. The speech encoder seamlessly integrates with the MT model at inference, enabling direct translation from speech to text, across all languages supported by the MT model. Our experiments show that we can effectively close the modality gap without ST data, while our results on MuST-C and CoVoST demonstrate our method's superiority over not only previous zero-shot models, but also supervised ones, achieving state-of-the-art results.
Promoting Generalized Cross-lingual Question Answering in Few-resource Scenarios via Self-knowledge Distillation
Sep 29, 2023



Despite substantial progress in multilingual extractive Question Answering (QA), models with high and uniformly distributed performance across languages remain challenging, especially for languages with limited resources. We study cross-lingual transfer mainly focusing on the Generalized Cross-Lingual Transfer (G-XLT) task, where the question language differs from the context language - a challenge that has received limited attention thus far. Our approach seeks to enhance cross-lingual QA transfer using a high-performing multilingual model trained on a large-scale dataset, complemented by a few thousand aligned QA examples across languages. Our proposed strategy combines cross-lingual sampling and advanced self-distillation training in generations to tackle the previous challenge. Notably, we introduce the novel mAP@k coefficients to fine-tune self-knowledge distillation loss, dynamically regulating the teacher's model knowledge to perform a balanced and effective knowledge transfer. We extensively evaluate our approach to assess XLT and G-XLT capabilities in extractive QA. Results reveal that our self-knowledge distillation approach outperforms standard cross-entropy fine-tuning by a significant margin. Importantly, when compared to a strong baseline that leverages a sizeable volume of machine-translated data, our approach shows competitive results despite the considerable challenge of operating within resource-constrained settings, even in zero-shot scenarios. Beyond performance improvements, we offer valuable insights through comprehensive analyses and an ablation study, further substantiating the benefits and constraints of our approach. In essence, we propose a practical solution to improve cross-lingual QA transfer by leveraging a few data resources in an efficient way.
Speech Translation with Foundation Models and Optimal Transport: UPC at IWSLT23
Jun 02, 2023This paper describes the submission of the UPC Machine Translation group to the IWSLT 2023 Offline Speech Translation task. Our Speech Translation systems utilize foundation models for speech (wav2vec 2.0) and text (mBART50). We incorporate a Siamese pretraining step of the speech and text encoders with CTC and Optimal Transport, to adapt the speech representations to the space of the text model, thus maximizing transfer learning from MT. After this pretraining, we fine-tune our system end-to-end on ST, with Cross Entropy and Knowledge Distillation. Apart from the available ST corpora, we create synthetic data with SegAugment to better adapt our models to the custom segmentations of the IWSLT test sets. Our best single model obtains 31.2 BLEU points on MuST-C tst-COMMON, 29.8 points on IWLST.tst2020 and 33.4 points on the newly released IWSLT.ACLdev2023.
SegAugment: Maximizing the Utility of Speech Translation Data with Segmentation-based Augmentations
Dec 19, 2022



Data scarcity is one of the main issues with the end-to-end approach for Speech Translation, as compared to the cascaded one. Although most data resources for Speech Translation are originally document-level, they offer a sentence-level view, which can be directly used during training. But this sentence-level view is single and static, potentially limiting the utility of the data. Our proposed data augmentation method SegAugment challenges this idea and aims to increase data availability by providing multiple alternative sentence-level views of a dataset. Our method heavily relies on an Audio Segmentation system to re-segment the speech of each document, after which we obtain the target text with alignment methods. The Audio Segmentation system can be parameterized with different length constraints, thus giving us access to multiple and diverse sentence-level views for each document. Experiments in MuST-C show consistent gains across 8 language pairs, with an average increase of 2.2 BLEU points, and up to 4.7 BLEU for lower-resource scenarios in mTEDx. Additionally, we find that SegAugment is also applicable to purely sentence-level data, as in CoVoST, and that it enables Speech Translation models to completely close the gap between the gold and automatic segmentation at inference time.
Efficient Speech Translation with Dynamic Latent Perceivers
Oct 28, 2022Transformers have been the dominant architecture for Speech Translation in recent years, achieving significant improvements in translation quality. Since speech signals are longer than their textual counterparts, and due to the quadratic complexity of the Transformer, a down-sampling step is essential for its adoption in Speech Translation. Instead, in this research, we propose to ease the complexity by using a Perceiver encoder to map the speech inputs to a fixed-length latent representation. Furthermore, we introduce a novel way of training Perceivers, with Dynamic Latent Access (DLA), unlocking larger latent spaces without any additional computational overhead. Speech-to-Text Perceivers with DLA can match the performance of a Transformer baseline across three language pairs in MuST-C. Finally, a DLA-trained model is easily adaptable to DLA at inference, and can be flexibly deployed with various computational budgets, without significant drops in translation quality.
SHAS: Approaching optimal Segmentation for End-to-End Speech Translation
Feb 09, 2022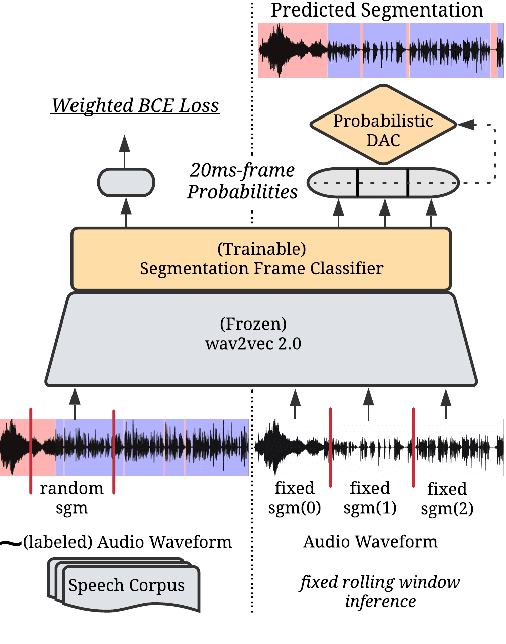
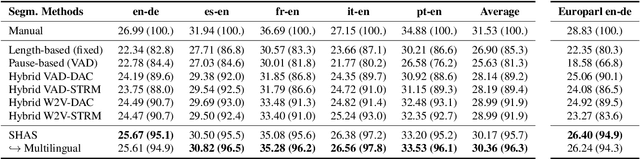
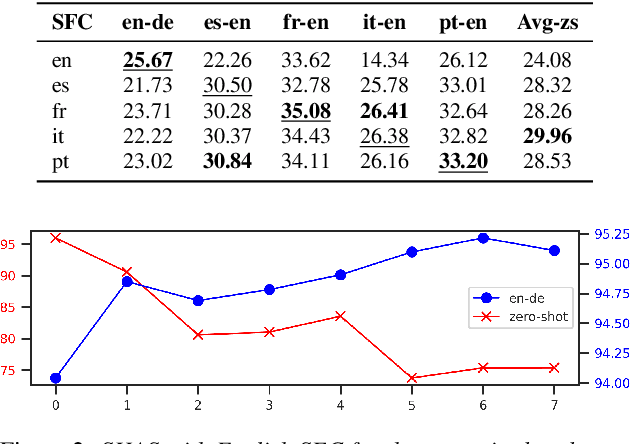
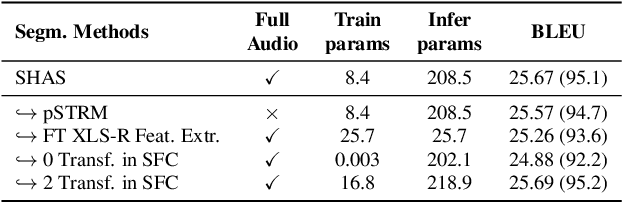
Speech translation models are unable to directly process long audios, like TED talks, which have to be split into shorter segments. Speech translation datasets provide manual segmentations of the audios, which are not available in real-world scenarios, and existing segmentation methods usually significantly reduce translation quality at inference time. To bridge the gap between the manual segmentation of training and the automatic one at inference, we propose Supervised Hybrid Audio Segmentation (SHAS), a method that can effectively learn the optimal segmentation from any manually segmented speech corpus. First, we train a classifier to identify the included frames in a segmentation, using speech representations from a pre-trained wav2vec 2.0. The optimal splitting points are then found by a probabilistic Divide-and-Conquer algorithm that progressively splits at the frame of lowest probability until all segments are below a pre-specified length. Experiments on MuST-C and mTEDx show that the translation of the segments produced by our method approaches the quality of the manual segmentation on 5 languages pairs. Namely, SHAS retains 95-98% of the manual segmentation's BLEU score, compared to the 87-93% of the best existing methods. Our method is additionally generalizable to different domains and achieves high zero-shot performance in unseen languages.
UPC's Speech Translation System for IWSLT 2021
May 10, 2021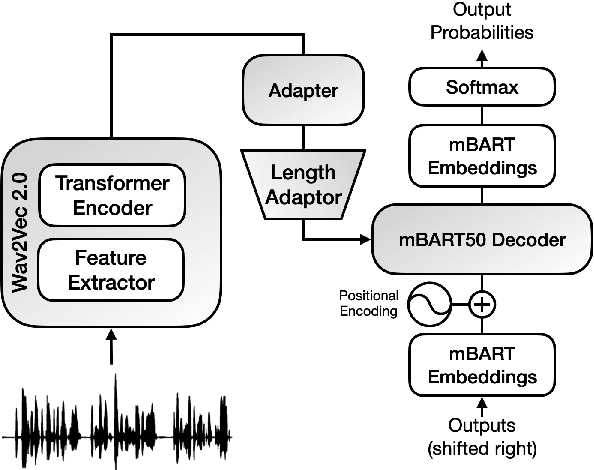

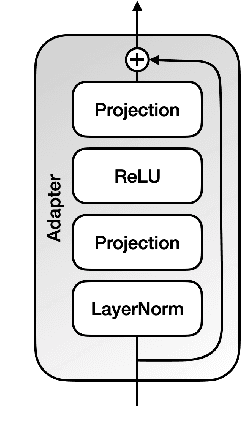
This paper describes the submission to the IWSLT 2021 offline speech translation task by the UPC Machine Translation group. The task consists of building a system capable of translating English audio recordings extracted from TED talks into German text. Submitted systems can be either cascade or end-to-end and use a custom or given segmentation. Our submission is an end-to-end speech translation system, which combines pre-trained models (Wav2Vec 2.0 and mBART) with coupling modules between the encoder and decoder, and uses an efficient fine-tuning technique, which trains only 20% of its total parameters. We show that adding an Adapter to the system and pre-training it, can increase the convergence speed and the final result, with which we achieve a BLEU score of 27.3 on the MuST-C test set. Our final model is an ensemble that obtains 28.22 BLEU score on the same set. Our submission also uses a custom segmentation algorithm that employs pre-trained Wav2Vec 2.0 for identifying periods of untranscribable text and can bring improvements of 2.5 to 3 BLEU score on the IWSLT 2019 test set, as compared to the result with the given segmentation.
Enabling Zero-shot Multilingual Spoken Language Translation with Language-Specific Encoders and Decoders
Nov 02, 2020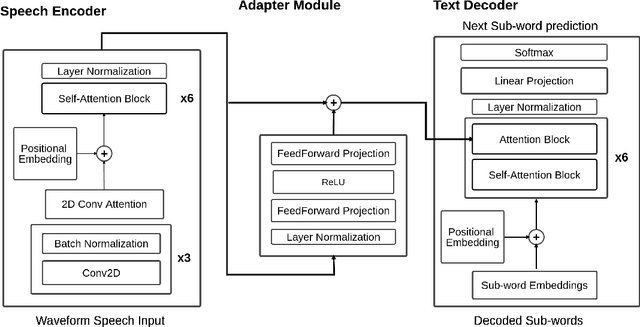
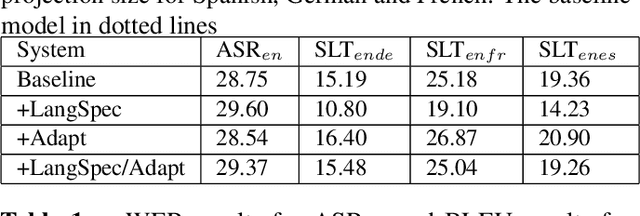
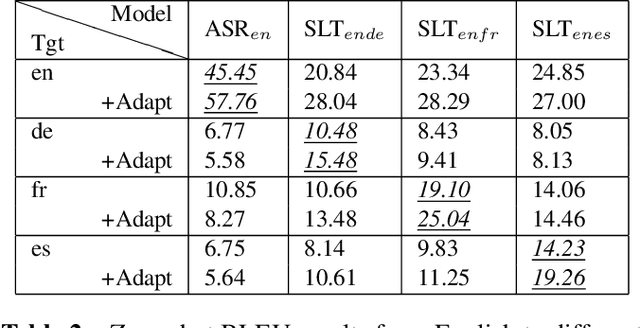
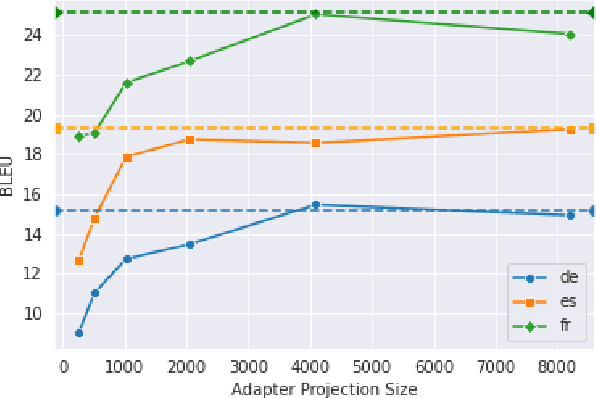
Current end-to-end approaches to Spoken Language Translation (SLT) rely on limited training resources, especially for multilingual settings. On the other hand, Multilingual Neural Machine Translation (MultiNMT) approaches rely on higher quality and more massive data sets. Our proposed method extends a MultiNMT architecture based on language-specific encoders-decoders to the task of Multilingual SLT (MultiSLT) Our experiments on four different languages show that coupling the speech encoder to the MultiNMT architecture produces similar quality translations compared to a bilingual baseline ($\pm 0.2$ BLEU) while effectively allowing for zero-shot MultiSLT. Additionally, we propose using Adapter networks for SLT that produce consistent improvements of +1 BLEU points in all tested languages.