 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Alignment Objectives for Aligner-Encoder based ASR
Jun 23, 2026Aligner-Encoders are recently proposed seq2seq end-to-end ASR models that replace decoder attention by predicting the uth token directly from the u-th encoder position, so the encoder must learn the alignment internally without cross-attention or a transducer lattice. In practice, this alignment often forms abruptly in the upper layers, making training sensitive and brittle on long utterances. We propose InterAligner, which adds an intermediate Aligner objective so alignment can form progressively across depth, together with an intermediate CTC loss (InterCTC) to stabilize optimization. On LibriSpeech with a 17-layer Conformer, a final-only Aligner reaches 5.0/7.8 WER (test-clean/other). InterCTC improves to 3.4/6.0, and InterAligner further reduces WER to 3.1/5.6 with the largest gains on long utterances.
Decoder-only Conformer with Modality-aware Sparse Mixtures of Experts for ASR
Feb 13, 2026We present a decoder-only Conformer for automatic speech recognition (ASR) that processes speech and text in a single stack without external speech encoders or pretrained large language models (LLM). The model uses a modality-aware sparse mixture of experts (MoE): disjoint expert pools for speech and text with hard routing and top-1 selection, embedded in hybrid-causality Conformer blocks (bidirectional for speech, causal for text). Training combines CTC on speech positions with label-smoothed cross-entropy for text generation. Our 113M-parameter model consistently improves WER over a 139M AED baseline on Librispeech (2.8% vs. 3.2% test-clean; 5.6% vs. 6.0% test-other). On Common Voice 16.1 with a single multilingual model across five languages, our approach reduces average WER from 12.2% to 10.6%. To our knowledge, this is the first randomly initialized decoder-only ASR that surpasses strong AED baselines via modality-aware routing and sparse MoE, achieving better accuracy with fewer active parameters and without alignment/adaptation modules.
All-in-One ASR: Unifying Encoder-Decoder Models of CTC, Attention, and Transducer in Dual-Mode ASR
Dec 12, 2025This paper proposes a unified framework, All-in-One ASR, that allows a single model to support multiple automatic speech recognition (ASR) paradigms, including connectionist temporal classification (CTC), attention-based encoder-decoder (AED), and Transducer, in both offline and streaming modes. While each ASR architecture offers distinct advantages and trade-offs depending on the application, maintaining separate models for each scenario incurs substantial development and deployment costs. To address this issue, we introduce a multi-mode joiner that enables seamless integration of various ASR modes within a single unified model. Experiments show that All-in-One ASR significantly reduces the total model footprint while matching or even surpassing the recognition performance of individually optimized ASR models. Furthermore, joint decoding leverages the complementary strengths of different ASR modes, yielding additional improvements in recognition accuracy.
Boosting Hybrid Autoregressive Transducer-based ASR with Internal Acoustic Model Training and Dual Blank Thresholding
Sep 30, 2024



A hybrid autoregressive transducer (HAT) is a variant of neural transducer that models blank and non-blank posterior distributions separately. In this paper, we propose a novel internal acoustic model (IAM) training strategy to enhance HAT-based speech recognition. IAM consists of encoder and joint networks, which are fully shared and jointly trained with HAT. This joint training not only enhances the HAT training efficiency but also encourages IAM and HAT to emit blanks synchronously which skips the more expensive non-blank computation, resulting in more effective blank thresholding for faster decoding. Experiments demonstrate that the relative error reductions of the HAT with IAM compared to the vanilla HAT are statistically significant. Moreover, we introduce dual blank thresholding, which combines both HAT- and IAM-blank thresholding and a compatible decoding algorithm. This results in a 42-75% decoding speed-up with no major performance degradation.
Alignment-Free Training for Transducer-based Multi-Talker ASR
Sep 30, 2024



Extending the RNN Transducer (RNNT) to recognize multi-talker speech is essential for wider automatic speech recognition (ASR) applications. Multi-talker RNNT (MT-RNNT) aims to achieve recognition without relying on costly front-end source separation. MT-RNNT is conventionally implemented using architectures with multiple encoders or decoders, or by serializing all speakers' transcriptions into a single output stream. The first approach is computationally expensive, particularly due to the need for multiple encoder processing. In contrast, the second approach involves a complex label generation process, requiring accurate timestamps of all words spoken by all speakers in the mixture, obtained from an external ASR system. In this paper, we propose a novel alignment-free training scheme for the MT-RNNT (MT-RNNT-AFT) that adopts the standard RNNT architecture. The target labels are created by appending a prompt token corresponding to each speaker at the beginning of the transcription, reflecting the order of each speaker's appearance in the mixtures. Thus, MT-RNNT-AFT can be trained without relying on accurate alignments, and it can recognize all speakers' speech with just one round of encoder processing. Experiments show that MT-RNNT-AFT achieves performance comparable to that of the state-of-the-art alternatives, while greatly simplifying the training process.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024



We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Sentence-wise Speech Summarization: Task, Datasets, and End-to-End Modeling with LM Knowledge Distillation
Aug 01, 2024



This paper introduces a novel approach called sentence-wise speech summarization (Sen-SSum), which generates text summaries from a spoken document in a sentence-by-sentence manner. Sen-SSum combines the real-time processing of automatic speech recognition (ASR) with the conciseness of speech summarization. To explore this approach, we present two datasets for Sen-SSum: Mega-SSum and CSJ-SSum. Using these datasets, our study evaluates two types of Transformer-based models: 1) cascade models that combine ASR and strong text summarization models, and 2) end-to-end (E2E) models that directly convert speech into a text summary. While E2E models are appealing to develop compute-efficient models, they perform worse than cascade models. Therefore, we propose knowledge distillation for E2E models using pseudo-summaries generated by the cascade models. Our experiments show that this proposed knowledge distillation effectively improves the performance of the E2E model on both datasets.
SpeakerBeam-SS: Real-time Target Speaker Extraction with Lightweight Conv-TasNet and State Space Modeling
Jul 01, 2024


Real-time target speaker extraction (TSE) is intended to extract the desired speaker's voice from the observed mixture of multiple speakers in a streaming manner. Implementing real-time TSE is challenging as the computational complexity must be reduced to provide real-time operation. This work introduces to Conv-TasNet-based TSE a new architecture based on state space modeling (SSM) that has been shown to model long-term dependency effectively. Owing to SSM, fewer dilated convolutional layers are required to capture temporal dependency in Conv-TasNet, resulting in the reduction of model complexity. We also enlarge the window length and shift of the convolutional (TasNet) frontend encoder to reduce the computational cost further; the performance decline is compensated by over-parameterization of the frontend encoder. The proposed method reduces the real-time factor by 78% from the conventional causal Conv-TasNet-based TSE while matching its performance.
Time-domain Speech Enhancement Assisted by Multi-resolution Frequency Encoder and Decoder
Mar 26, 2023



Time-domain speech enhancement (SE) has recently been intensively investigated. Among recent works, DEMUCS introduces multi-resolution STFT loss to enhance performance. However, some resolutions used for STFT contain non-stationary signals, and it is challenging to learn multi-resolution frequency losses simultaneously with only one output. For better use of multi-resolution frequency information, we supplement multiple spectrograms in different frame lengths into the time-domain encoders. They extract stationary frequency information in both narrowband and wideband. We also adopt multiple decoder outputs, each of which computes its corresponding resolution frequency loss. Experimental results show that (1) it is more effective to fuse stationary frequency features than non-stationary features in the encoder, and (2) the multiple outputs consistent with the frequency loss improve performance. Experiments on the Voice-Bank dataset show that the proposed method obtained a 0.14 PESQ improvement.
Non-autoregressive Error Correction for CTC-based ASR with Phone-conditioned Masked LM
Sep 08, 2022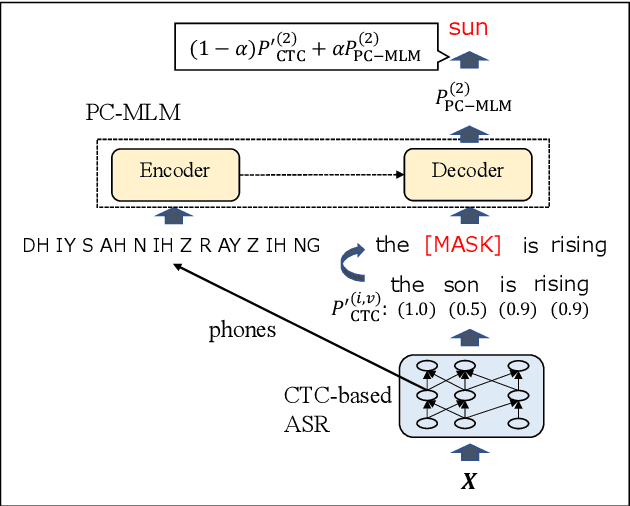
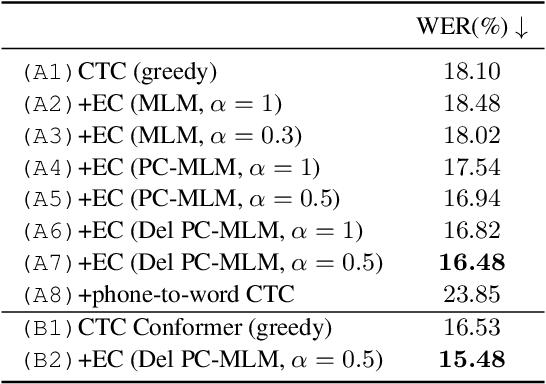
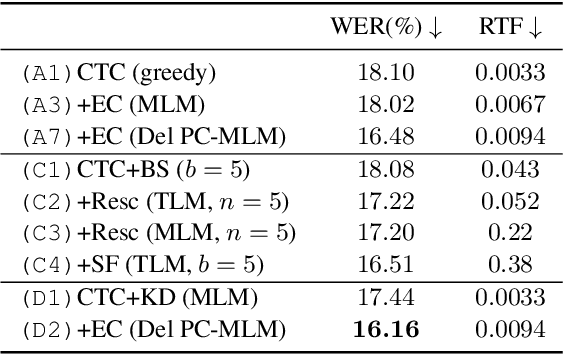
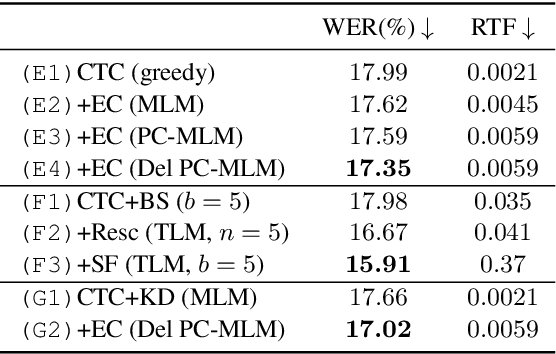
Connectionist temporal classification (CTC) -based models are attractive in automatic speech recognition (ASR) because of their non-autoregressive nature. To take advantage of text-only data, language model (LM) integration approaches such as rescoring and shallow fusion have been widely used for CTC. However, they lose CTC's non-autoregressive nature because of the need for beam search, which slows down the inference speed. In this study, we propose an error correction method with phone-conditioned masked LM (PC-MLM). In the proposed method, less confident word tokens in a greedy decoded output from CTC are masked. PC-MLM then predicts these masked word tokens given unmasked words and phones supplementally predicted from CTC. We further extend it to Deletable PC-MLM in order to address insertion errors. Since both CTC and PC-MLM are non-autoregressive models, the method enables fast LM integration. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 in domain adaptation setting shows that our proposed method outperformed rescoring and shallow fusion in terms of inference speed, and also in terms of recognition accuracy on CSJ.