 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Joint Target and Non-Target Speakers ASR
Jun 04, 2023


This paper proposes a novel automatic speech recognition (ASR) system that can transcribe individual speaker's speech while identifying whether they are target or non-target speakers from multi-talker overlapped speech. Target-speaker ASR systems are a promising way to only transcribe a target speaker's speech by enrolling the target speaker's information. However, in conversational ASR applications, transcribing both the target speaker's speech and non-target speakers' ones is often required to understand interactive information. To naturally consider both target and non-target speakers in a single ASR model, our idea is to extend autoregressive modeling-based multi-talker ASR systems to utilize the enrollment speech of the target speaker. Our proposed ASR is performed by recursively generating both textual tokens and tokens that represent target or non-target speakers. Our experiments demonstrate the effectiveness of our proposed method.
On the Use of Modality-Specific Large-Scale Pre-Trained Encoders for Multimodal Sentiment Analysis
Oct 28, 2022



This paper investigates the effectiveness and implementation of modality-specific large-scale pre-trained encoders for multimodal sentiment analysis~(MSA). Although the effectiveness of pre-trained encoders in various fields has been reported, conventional MSA methods employ them for only linguistic modality, and their application has not been investigated. This paper compares the features yielded by large-scale pre-trained encoders with conventional heuristic features. One each of the largest pre-trained encoders publicly available for each modality are used; CLIP-ViT, WavLM, and BERT for visual, acoustic, and linguistic modalities, respectively. Experiments on two datasets reveal that methods with domain-specific pre-trained encoders attain better performance than those with conventional features in both unimodal and multimodal scenarios. We also find it better to use the outputs of the intermediate layers of the encoders than those of the output layer. The codes are available at https://github.com/ando-hub/MSA_Pretrain.
Audio Visual Scene-Aware Dialog Generation with Transformer-based Video Representations
Feb 21, 2022
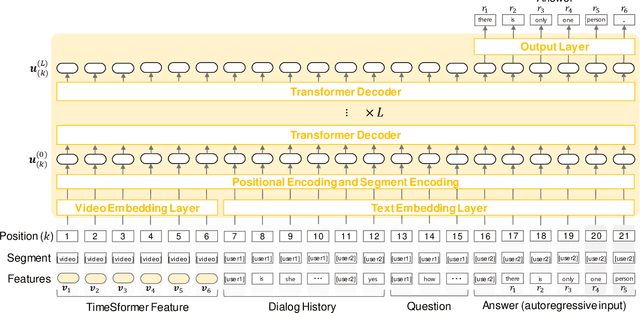
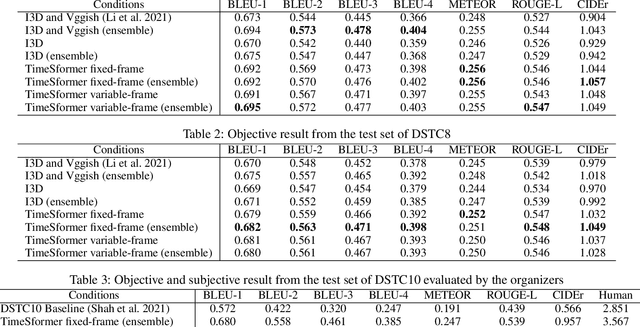
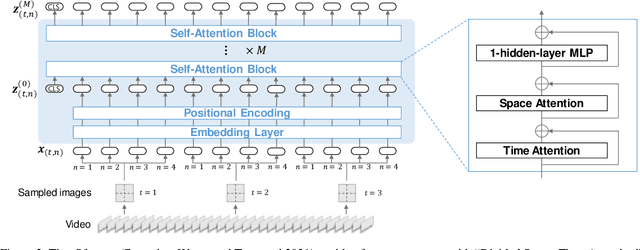
There have been many attempts to build multimodal dialog systems that can respond to a question about given audio-visual information, and the representative task for such systems is the Audio Visual Scene-Aware Dialog (AVSD). Most conventional AVSD models adopt the Convolutional Neural Network (CNN)-based video feature extractor to understand visual information. While a CNN tends to obtain both temporally and spatially local information, global information is also crucial for boosting video understanding because AVSD requires long-term temporal visual dependency and whole visual information. In this study, we apply the Transformer-based video feature that can capture both temporally and spatially global representations more efficiently than the CNN-based feature. Our AVSD model with its Transformer-based feature attains higher objective performance scores for answer generation. In addition, our model achieves a subjective score close to that of human answers in DSTC10. We observed that the Transformer-based visual feature is beneficial for the AVSD task because our model tends to correctly answer the questions that need a temporally and spatially broad range of visual information.
Utilizing Resource-Rich Language Datasets for End-to-End Scene Text Recognition in Resource-Poor Languages
Nov 24, 2021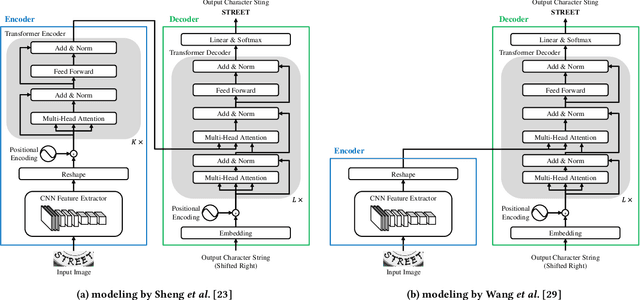
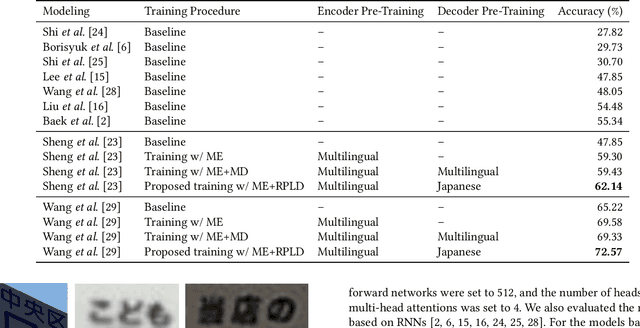
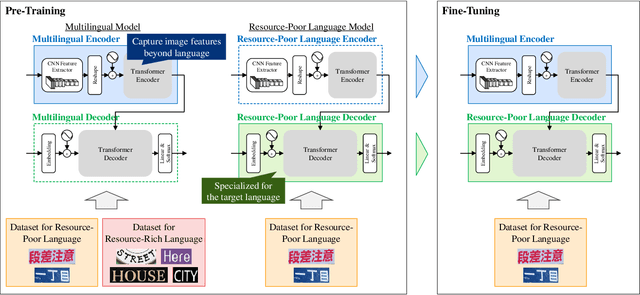
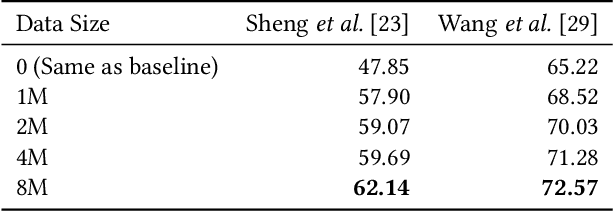
This paper presents a novel training method for end-to-end scene text recognition. End-to-end scene text recognition offers high recognition accuracy, especially when using the encoder-decoder model based on Transformer. To train a highly accurate end-to-end model, we need to prepare a large image-to-text paired dataset for the target language. However, it is difficult to collect this data, especially for resource-poor languages. To overcome this difficulty, our proposed method utilizes well-prepared large datasets in resource-rich languages such as English, to train the resource-poor encoder-decoder model. Our key idea is to build a model in which the encoder reflects knowledge of multiple languages while the decoder specializes in knowledge of just the resource-poor language. To this end, the proposed method pre-trains the encoder by using a multilingual dataset that combines the resource-poor language's dataset and the resource-rich language's dataset to learn language-invariant knowledge for scene text recognition. The proposed method also pre-trains the decoder by using the resource-poor language's dataset to make the decoder better suited to the resource-poor language. Experiments on Japanese scene text recognition using a small, publicly available dataset demonstrate the effectiveness of the proposed method.
Hierarchical Knowledge Distillation for Dialogue Sequence Labeling
Nov 22, 2021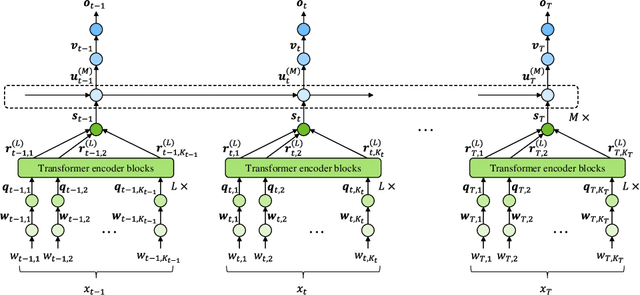
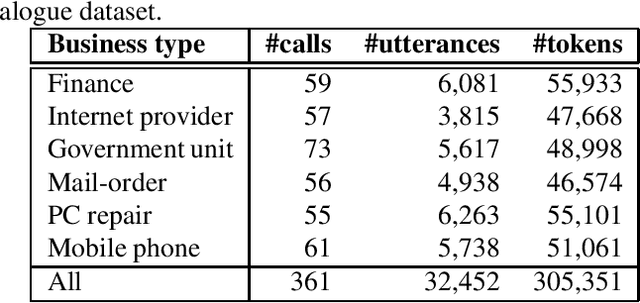
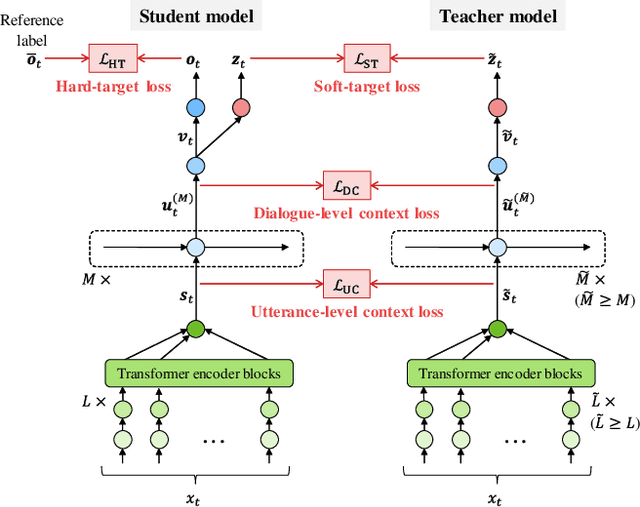
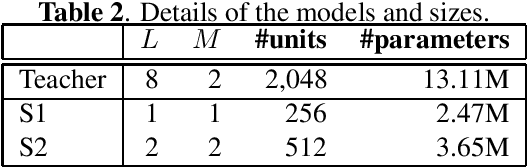
This paper presents a novel knowledge distillation method for dialogue sequence labeling. Dialogue sequence labeling is a supervised learning task that estimates labels for each utterance in the target dialogue document, and is useful for many applications such as dialogue act estimation. Accurate labeling is often realized by a hierarchically-structured large model consisting of utterance-level and dialogue-level networks that capture the contexts within an utterance and between utterances, respectively. However, due to its large model size, such a model cannot be deployed on resource-constrained devices. To overcome this difficulty, we focus on knowledge distillation which trains a small model by distilling the knowledge of a large and high performance teacher model. Our key idea is to distill the knowledge while keeping the complex contexts captured by the teacher model. To this end, the proposed method, hierarchical knowledge distillation, trains the small model by distilling not only the probability distribution of the label classification, but also the knowledge of utterance-level and dialogue-level contexts trained in the teacher model by training the model to mimic the teacher model's output in each level. Experiments on dialogue act estimation and call scene segmentation demonstrate the effectiveness of the proposed method.
End-to-End Rich Transcription-Style Automatic Speech Recognition with Semi-Supervised Learning
Jul 07, 2021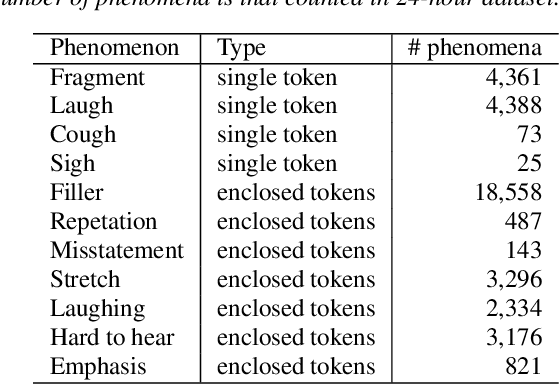
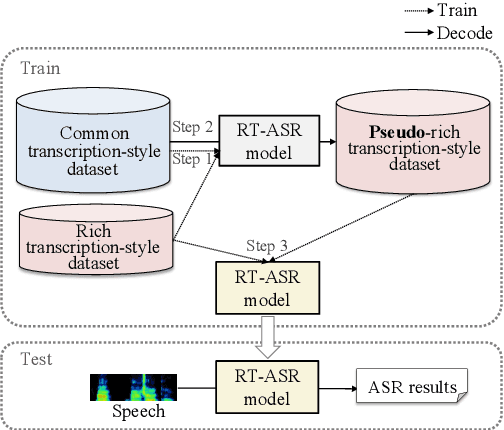
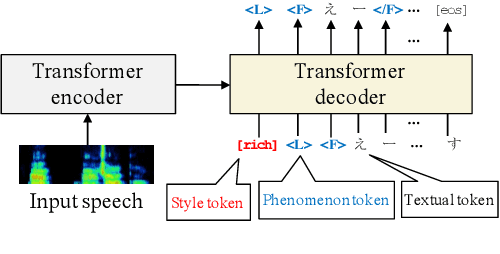
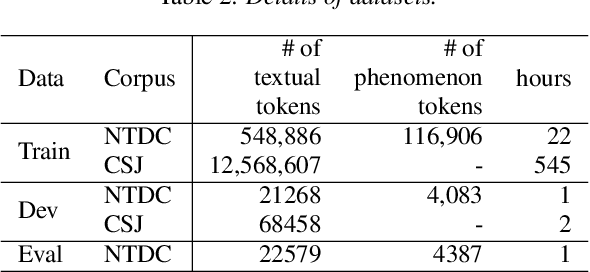
We propose a semi-supervised learning method for building end-to-end rich transcription-style automatic speech recognition (RT-ASR) systems from small-scale rich transcription-style and large-scale common transcription-style datasets. In spontaneous speech tasks, various speech phenomena such as fillers, word fragments, laughter and coughs, etc. are often included. While common transcriptions do not give special awareness to these phenomena, rich transcriptions explicitly convert them into special phenomenon tokens as well as textual tokens. In previous studies, the textual and phenomenon tokens were simultaneously estimated in an end-to-end manner. However, it is difficult to build accurate RT-ASR systems because large-scale rich transcription-style datasets are often unavailable. To solve this problem, our training method uses a limited rich transcription-style dataset and common transcription-style dataset simultaneously. The Key process in our semi-supervised learning is to convert the common transcription-style dataset into a pseudo-rich transcription-style dataset. To this end, we introduce style tokens which control phenomenon tokens are generated or not into transformer-based autoregressive modeling. We use this modeling for generating the pseudo-rich transcription-style datasets and for building RT-ASR system from the pseudo and original datasets. Our experiments on spontaneous ASR tasks showed the effectiveness of the proposed method.
Cross-Modal Transformer-Based Neural Correction Models for Automatic Speech Recognition
Jul 04, 2021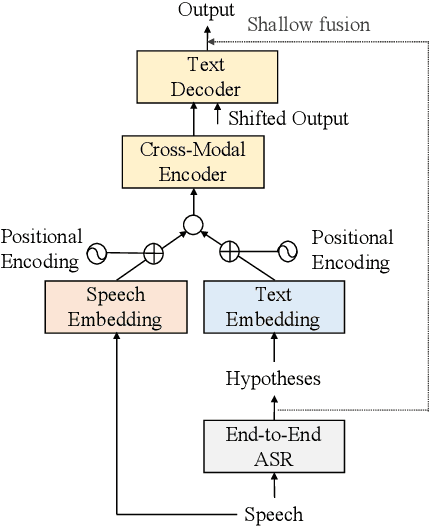
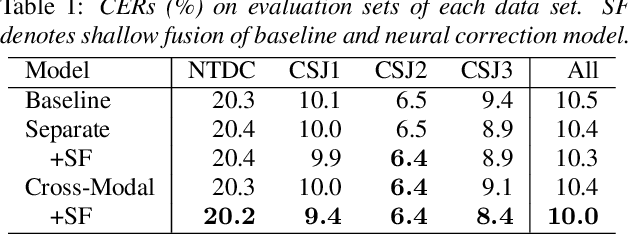
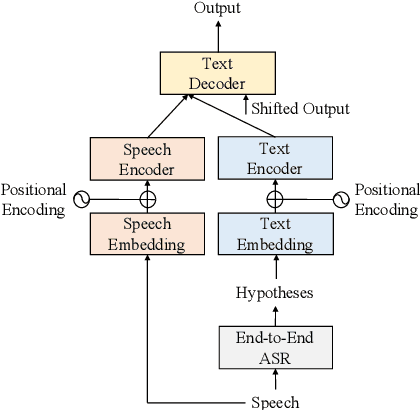
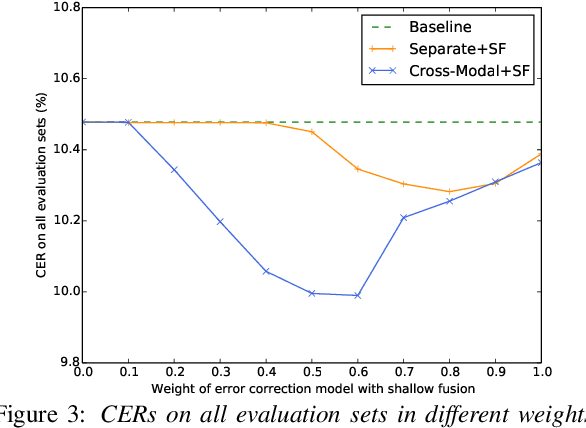
We propose a cross-modal transformer-based neural correction models that refines the output of an automatic speech recognition (ASR) system so as to exclude ASR errors. Generally, neural correction models are composed of encoder-decoder networks, which can directly model sequence-to-sequence mapping problems. The most successful method is to use both input speech and its ASR output text as the input contexts for the encoder-decoder networks. However, the conventional method cannot take into account the relationships between these two different modal inputs because the input contexts are separately encoded for each modal. To effectively leverage the correlated information between the two different modal inputs, our proposed models encode two different contexts jointly on the basis of cross-modal self-attention using a transformer. We expect that cross-modal self-attention can effectively capture the relationships between two different modals for refining ASR hypotheses. We also introduce a shallow fusion technique to efficiently integrate the first-pass ASR model and our proposed neural correction model. Experiments on Japanese natural language ASR tasks demonstrated that our proposed models achieve better ASR performance than conventional neural correction models.
Unified Autoregressive Modeling for Joint End-to-End Multi-Talker Overlapped Speech Recognition and Speaker Attribute Estimation
Jul 04, 2021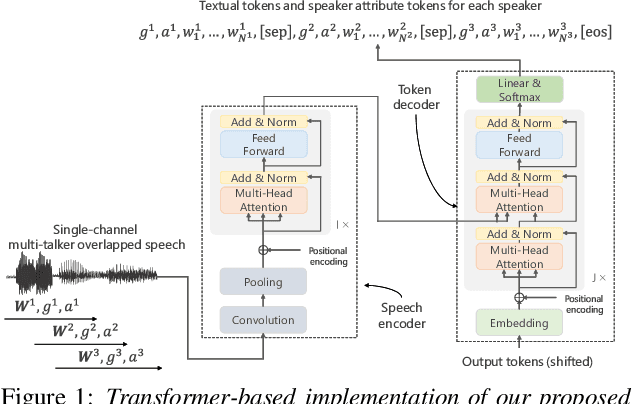
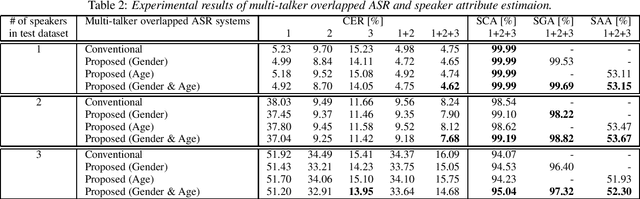
In this paper, we present a novel modeling method for single-channel multi-talker overlapped automatic speech recognition (ASR) systems. Fully neural network based end-to-end models have dramatically improved the performance of multi-taker overlapped ASR tasks. One promising approach for end-to-end modeling is autoregressive modeling with serialized output training in which transcriptions of multiple speakers are recursively generated one after another. This enables us to naturally capture relationships between speakers. However, the conventional modeling method cannot explicitly take into account the speaker attributes of individual utterances such as gender and age information. In fact, the performance deteriorates when each speaker is the same gender or is close in age. To address this problem, we propose unified autoregressive modeling for joint end-to-end multi-talker overlapped ASR and speaker attribute estimation. Our key idea is to handle gender and age estimation tasks within the unified autoregressive modeling. In the proposed method, transformer-based autoregressive model recursively generates not only textual tokens but also attribute tokens of each speaker. This enables us to effectively utilize speaker attributes for improving multi-talker overlapped ASR. Experiments on Japanese multi-talker overlapped ASR tasks demonstrate the effectiveness of the proposed method.
Enrollment-less training for personalized voice activity detection
Jun 23, 2021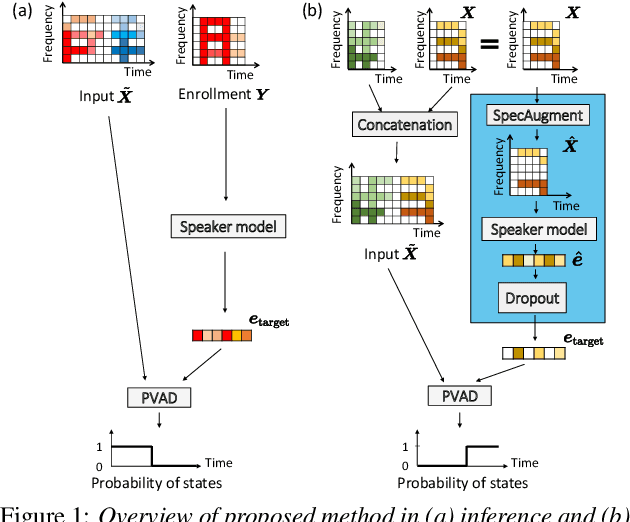
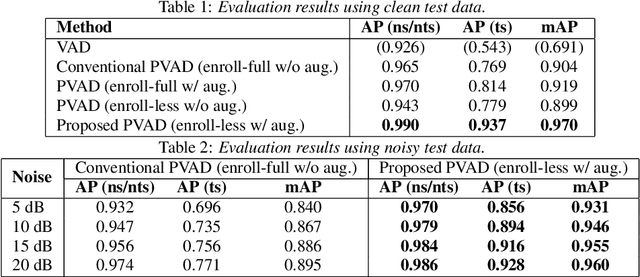
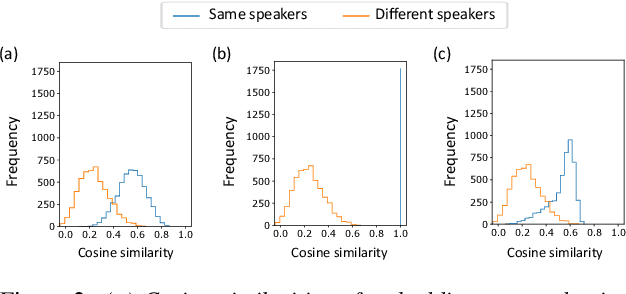
We present a novel personalized voice activity detection (PVAD) learning method that does not require enrollment data during training. PVAD is a task to detect the speech segments of a specific target speaker at the frame level using enrollment speech of the target speaker. Since PVAD must learn speakers' speech variations to clarify the boundary between speakers, studies on PVAD used large-scale datasets that contain many utterances for each speaker. However, the datasets to train a PVAD model are often limited because substantial cost is needed to prepare such a dataset. In addition, we cannot utilize the datasets used to train the standard VAD because they often lack speaker labels. To solve these problems, our key idea is to use one utterance as both a kind of enrollment speech and an input to the PVAD during training, which enables PVAD training without enrollment speech. In our proposed method, called enrollment-less training, we augment one utterance so as to create variability between the input and the enrollment speech while keeping the speaker identity, which avoids the mismatch between training and inference. Our experimental results demonstrate the efficacy of the method.
Zero-Shot Joint Modeling of Multiple Spoken-Text-Style Conversion Tasks using Switching Tokens
Jun 23, 2021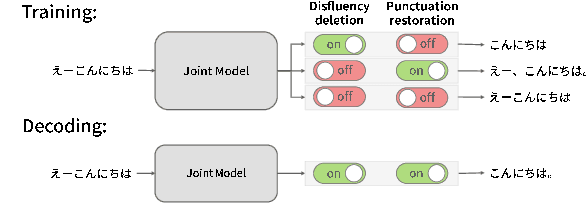
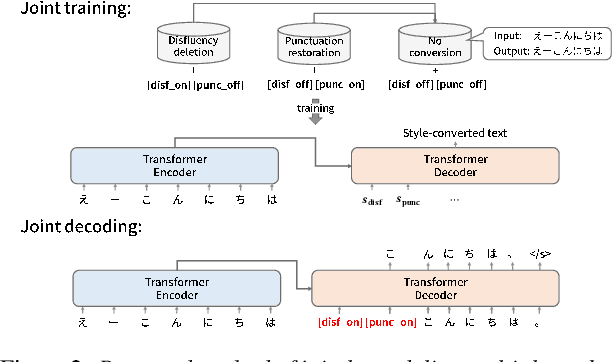
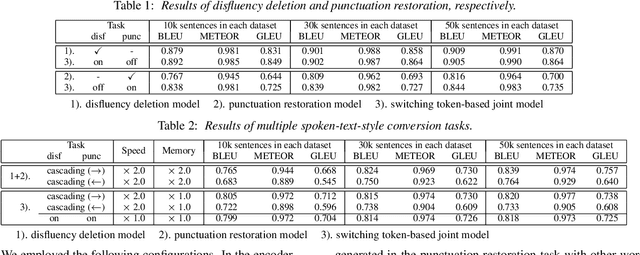
In this paper, we propose a novel spoken-text-style conversion method that can simultaneously execute multiple style conversion modules such as punctuation restoration and disfluency deletion without preparing matched datasets. In practice, transcriptions generated by automatic speech recognition systems are not highly readable because they often include many disfluencies and do not include punctuation marks. To improve their readability, multiple spoken-text-style conversion modules that individually model a single conversion task are cascaded because matched datasets that simultaneously handle multiple conversion tasks are often unavailable. However, the cascading is unstable against the order of tasks because of the chain of conversion errors. Besides, the computation cost of the cascading must be higher than the single conversion. To execute multiple conversion tasks simultaneously without preparing matched datasets, our key idea is to distinguish individual conversion tasks using the on-off switch. In our proposed zero-shot joint modeling, we switch the individual tasks using multiple switching tokens, enabling us to utilize a zero-shot learning approach to executing simultaneous conversions. Our experiments on joint modeling of disfluency deletion and punctuation restoration demonstrate the effectiveness of our method.