 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
MooseNet: A trainable metric for synthesized speech with plda backend
Jan 17, 2023
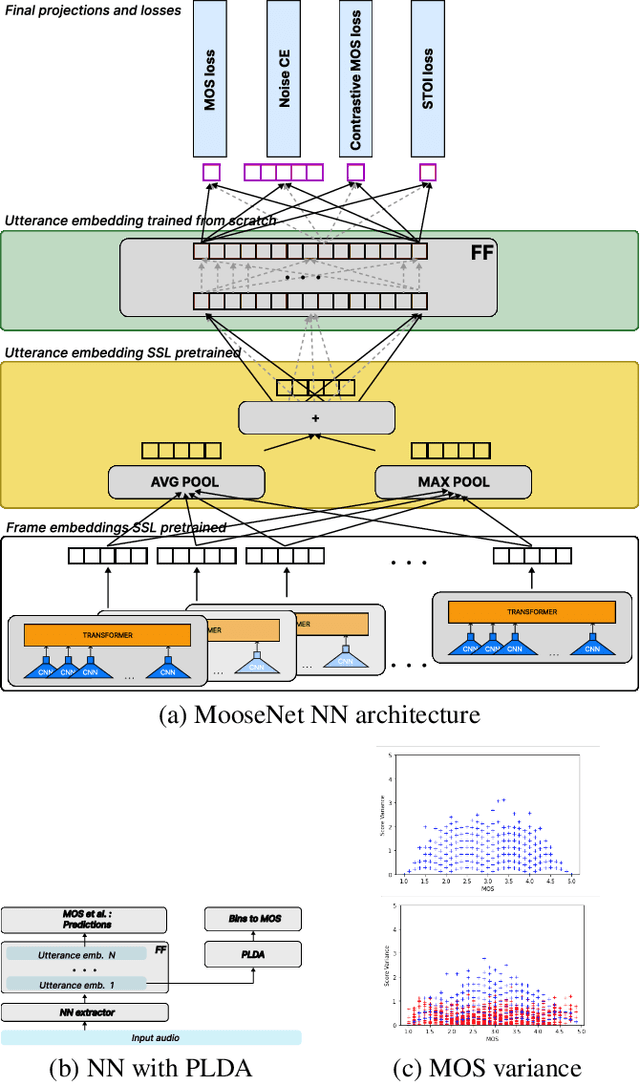
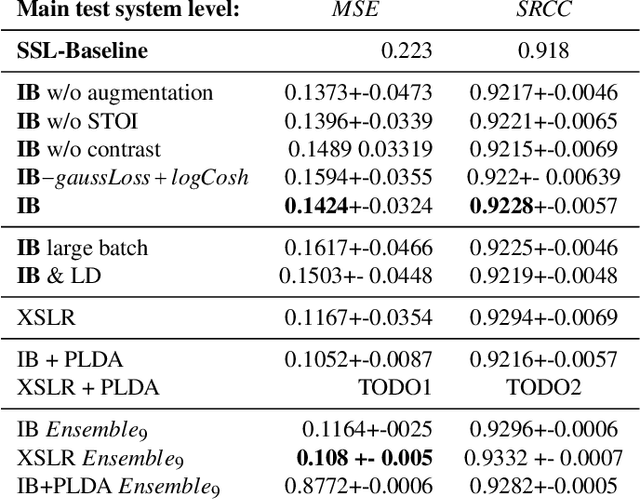
We present MooseNet, a trainable speech metric that predicts listeners' Mean Opinion Score (MOS). We report improvements to the challenge baselines using easy-to-use modeling techniques, which also scales for larger self-supervised learning (SSL) model. We present two models. The first model is a Neural Network (NN). As a second model, we propose a PLDA generative model on the top layers of the first NN model, which improves the pure NN model. Ensembles from our two models achieve the top 3 or 4 VoiceMOS leaderboard places on all system and utterance level metrics.
Adapting Pretrained ASR Models to Low-resource Clinical Speech using Epistemic Uncertainty-based Data Selection
Jun 03, 2023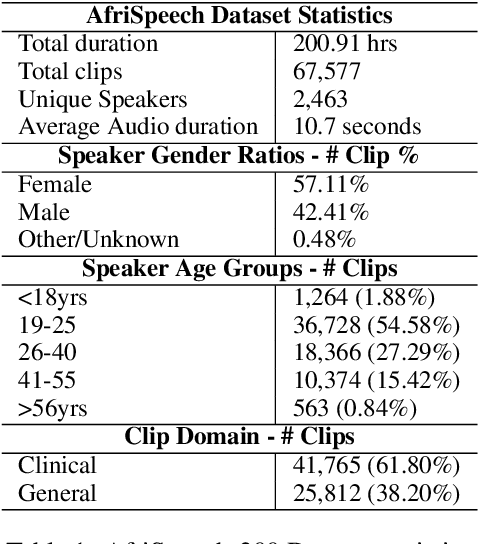
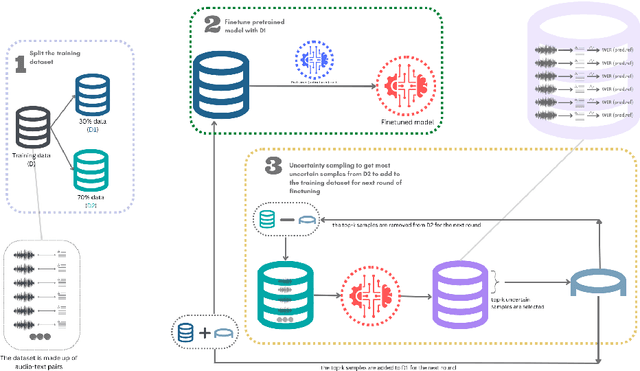
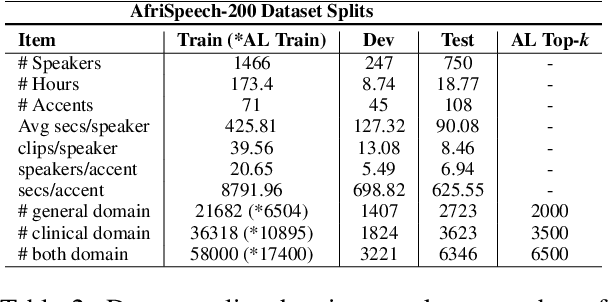
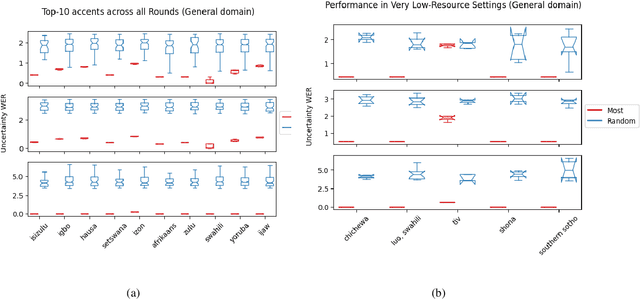
While there has been significant progress in ASR, African-accented clinical ASR has been understudied due to a lack of training datasets. Building robust ASR systems in this domain requires large amounts of annotated or labeled data, for a wide variety of linguistically and morphologically rich accents, which are expensive to create. Our study aims to address this problem by reducing annotation expenses through informative uncertainty-based data selection. We show that incorporating epistemic uncertainty into our adaptation rounds outperforms several baseline results, established using state-of-the-art (SOTA) ASR models, while reducing the required amount of labeled data, and hence reducing annotation costs. Our approach also improves out-of-distribution generalization for very low-resource accents, demonstrating the viability of our approach for building generalizable ASR models in the context of accented African clinical ASR, where training datasets are predominantly scarce.
JoeyS2T: Minimalistic Speech-to-Text Modeling with JoeyNMT
Oct 05, 2022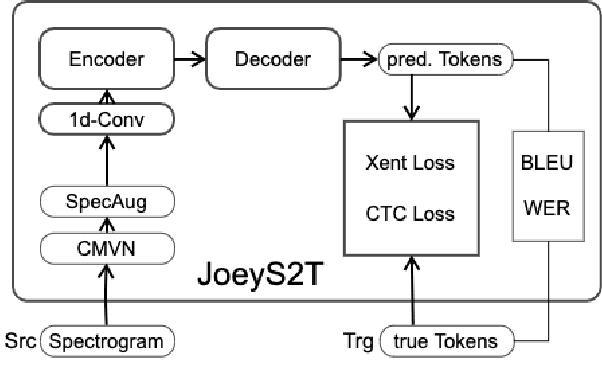
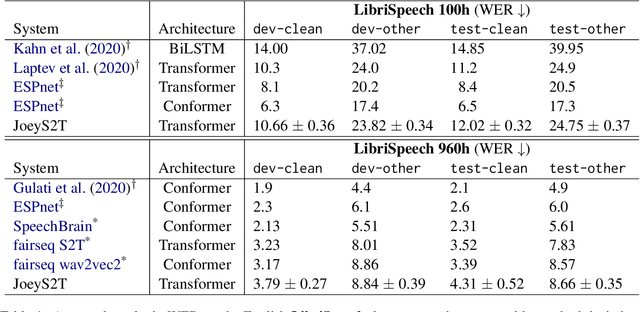
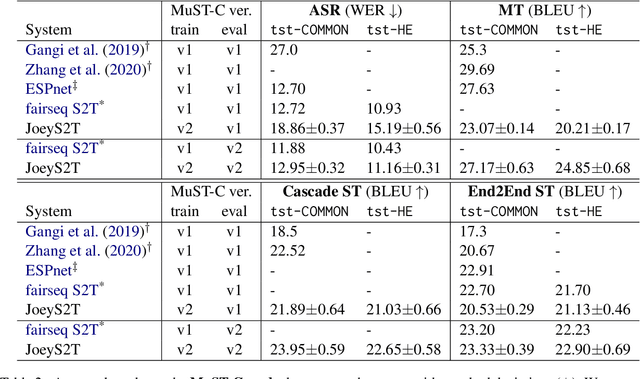
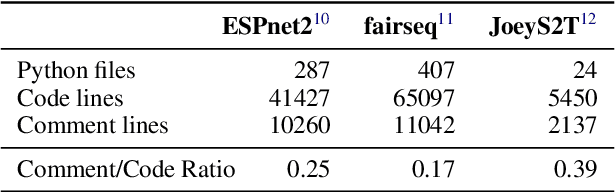
JoeyS2T is a JoeyNMT extension for speech-to-text tasks such as automatic speech recognition and end-to-end speech translation. It inherits the core philosophy of JoeyNMT, a minimalist NMT toolkit built on PyTorch, seeking simplicity and accessibility. JoeyS2T's workflow is self-contained, starting from data pre-processing, over model training and prediction to evaluation, and is seamlessly integrated into JoeyNMT's compact and simple code base. On top of JoeyNMT's state-of-the-art Transformer-based encoder-decoder architecture, JoeyS2T provides speech-oriented components such as convolutional layers, SpecAugment, CTC-loss, and WER evaluation. Despite its simplicity compared to prior implementations, JoeyS2T performs competitively on English speech recognition and English-to-German speech translation benchmarks. The implementation is accompanied by a walk-through tutorial and available on https://github.com/may-/joeys2t.
Can We Trust Explainable AI Methods on ASR? An Evaluation on Phoneme Recognition
May 29, 2023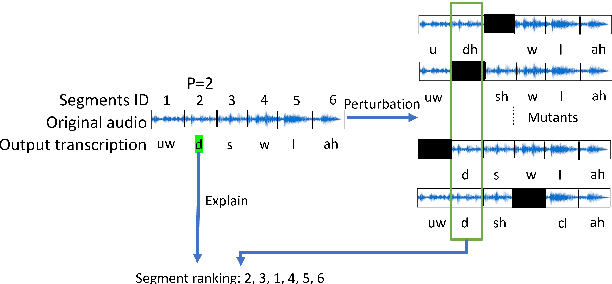



Explainable AI (XAI) techniques have been widely used to help explain and understand the output of deep learning models in fields such as image classification and Natural Language Processing. Interest in using XAI techniques to explain deep learning-based automatic speech recognition (ASR) is emerging. but there is not enough evidence on whether these explanations can be trusted. To address this, we adapt a state-of-the-art XAI technique from the image classification domain, Local Interpretable Model-Agnostic Explanations (LIME), to a model trained for a TIMIT-based phoneme recognition task. This simple task provides a controlled setting for evaluation while also providing expert annotated ground truth to assess the quality of explanations. We find a variant of LIME based on time partitioned audio segments, that we propose in this paper, produces the most reliable explanations, containing the ground truth 96% of the time in its top three audio segments.
Improved Self-Supervised Multilingual Speech Representation Learning Combined with Auxiliary Language Information
Dec 07, 2022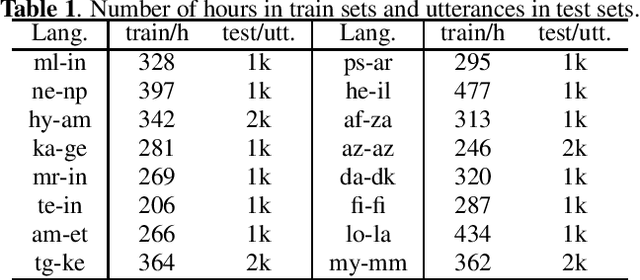
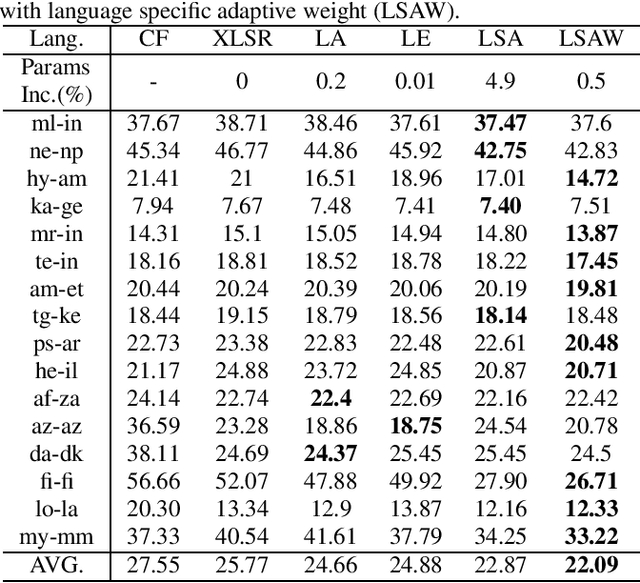
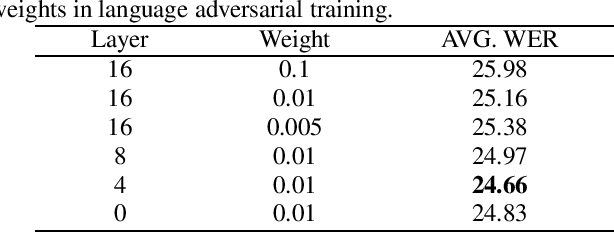

Multilingual end-to-end models have shown great improvement over monolingual systems. With the development of pre-training methods on speech, self-supervised multilingual speech representation learning like XLSR has shown success in improving the performance of multilingual automatic speech recognition (ASR). However, similar to the supervised learning, multilingual pre-training may also suffer from language interference and further affect the application of multilingual system. In this paper, we introduce several techniques for improving self-supervised multilingual pre-training by leveraging auxiliary language information, including the language adversarial training, language embedding and language adaptive training during the pre-training stage. We conduct experiments on a multilingual ASR task consisting of 16 languages. Our experimental results demonstrate 14.3% relative gain over the standard XLSR model, and 19.8% relative gain over the no pre-training multilingual model.
SPACE: Speech-driven Portrait Animation with Controllable Expression
Dec 07, 2022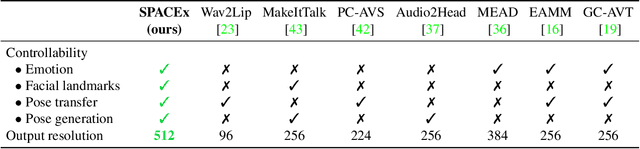
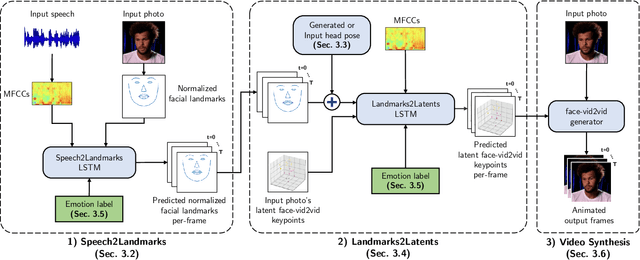
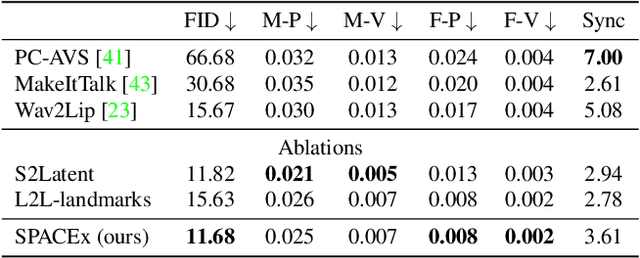
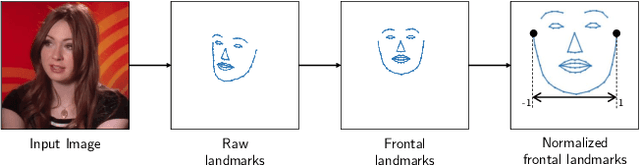
Animating portraits using speech has received growing attention in recent years, with various creative and practical use cases. An ideal generated video should have good lip sync with the audio, natural facial expressions and head motions, and high frame quality. In this work, we present SPACE, which uses speech and a single image to generate high-resolution, and expressive videos with realistic head pose, without requiring a driving video. It uses a multi-stage approach, combining the controllability of facial landmarks with the high-quality synthesis power of a pretrained face generator. SPACE also allows for the control of emotions and their intensities. Our method outperforms prior methods in objective metrics for image quality and facial motions and is strongly preferred by users in pair-wise comparisons. The project website is available at https://deepimagination.cc/SPACE/
A Versatile Diffusion-based Generative Refiner for Speech Enhancement
Oct 27, 2022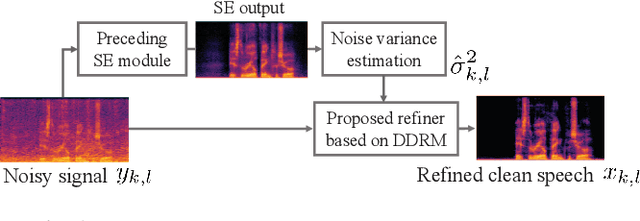
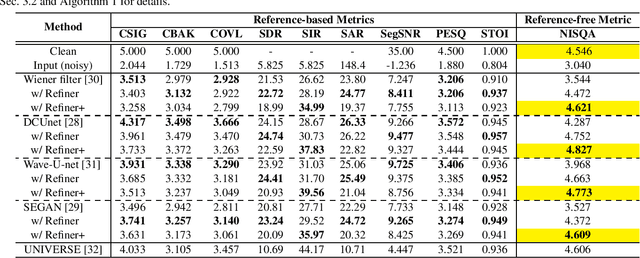
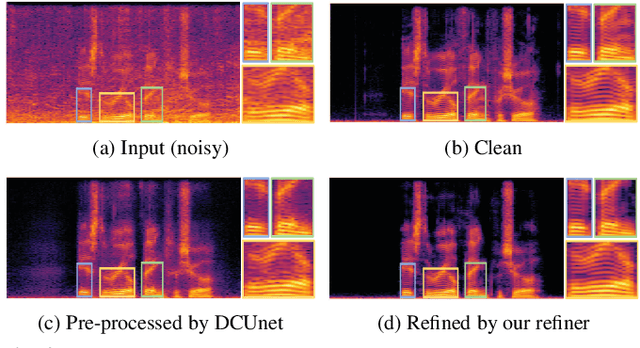
Although deep neural network (DNN)-based speech enhancement (SE) methods outperform the previous non-DNN-based ones, they often degrade the perceptual quality of generated outputs. To tackle this problem, We introduce a DNN-based generative refiner aiming to improve perceptual speech quality pre-processed by an SE method. As the refiner, we train a diffusion-based generative model by utilizing a dataset consisting of clean speech only. Then, the model replaces the degraded and distorted parts caused by a preceding SE method with newly generated clean parts by denoising diffusion restoration. Once our refiner is trained on a set of clean speech, it can be applied to various SE methods without additional training specialized for each SE module. Therefore, our refiner can be a versatile post-processing module w.r.t. SE methods and has high potential in terms of modularity. Experimental results show that our method improved perceptual speech quality regardless of the preceding SE methods used.
Modulation spectral features for speech emotion recognition using deep neural networks
Jan 14, 2023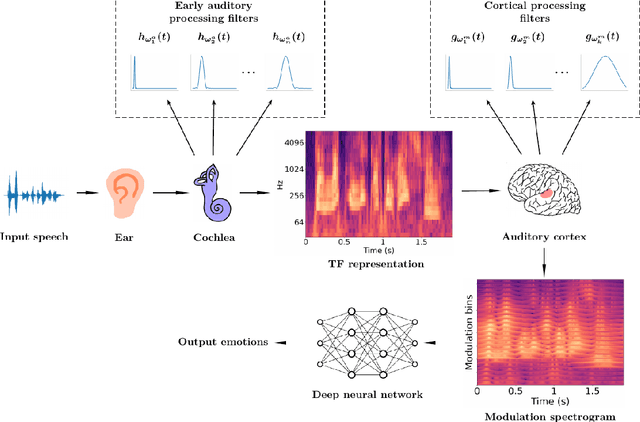
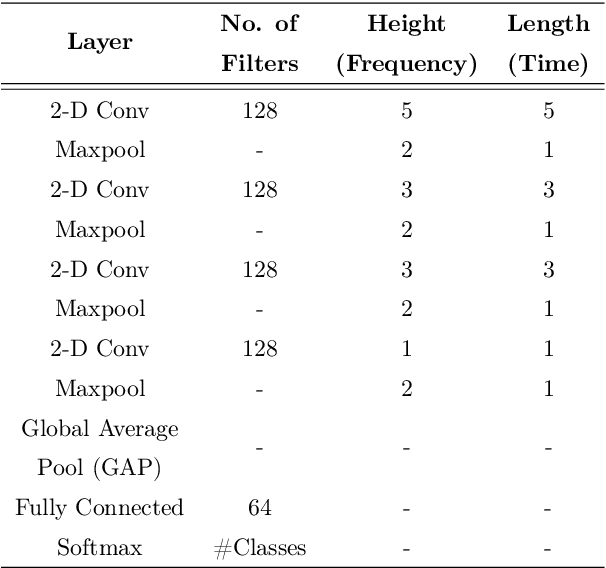


This work explores the use of constant-Q transform based modulation spectral features (CQT-MSF) for speech emotion recognition (SER). The human perception and analysis of sound comprise of two important cognitive parts: early auditory analysis and cortex-based processing. The early auditory analysis considers spectrogram-based representation whereas cortex-based analysis includes extraction of temporal modulations from the spectrogram. This temporal modulation representation of spectrogram is called modulation spectral feature (MSF). As the constant-Q transform (CQT) provides higher resolution at emotion salient low-frequency regions of speech, we find that CQT-based spectrogram, together with its temporal modulations, provides a representation enriched with emotion-specific information. We argue that CQT-MSF when used with a 2-dimensional convolutional network can provide a time-shift invariant and deformation insensitive representation for SER. Our results show that CQT-MSF outperforms standard mel-scale based spectrogram and its modulation features on two popular SER databases, Berlin EmoDB and RAVDESS. We also show that our proposed feature outperforms the shift and deformation invariant scattering transform coefficients, hence, showing the importance of joint hand-crafted and self-learned feature extraction instead of reliance on complete hand-crafted features. Finally, we perform Grad-CAM analysis to visually inspect the contribution of constant-Q modulation features over SER.
* Accepted for publication in Elsevier's Speech Communication Journal
M-SpeechCLIP: Leveraging Large-Scale, Pre-Trained Models for Multilingual Speech to Image Retrieval
Nov 02, 2022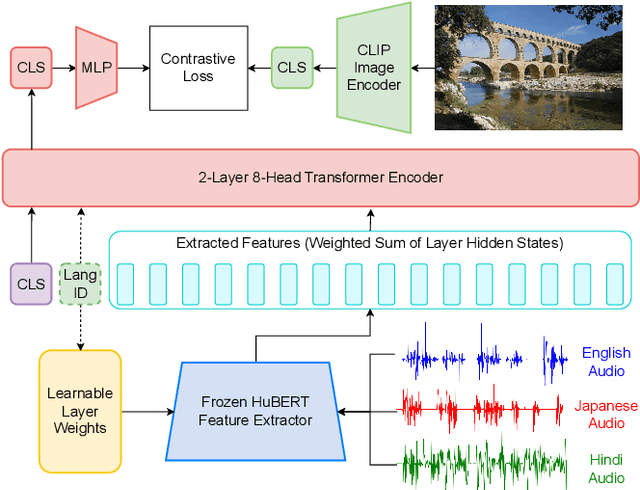
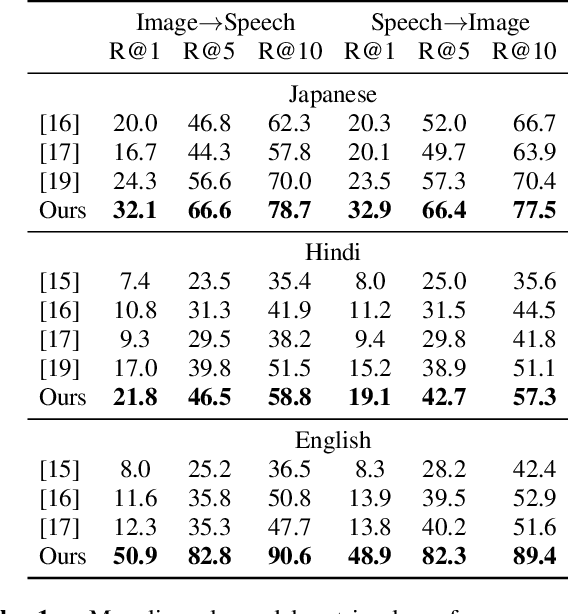
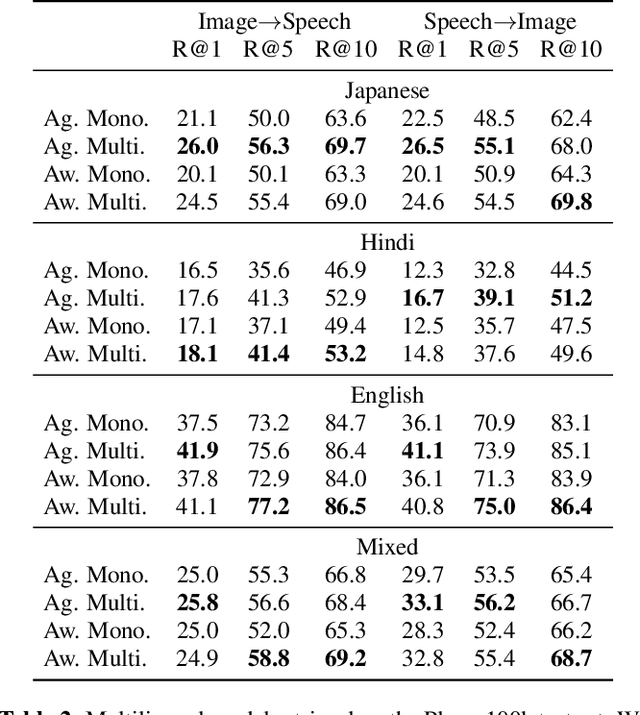
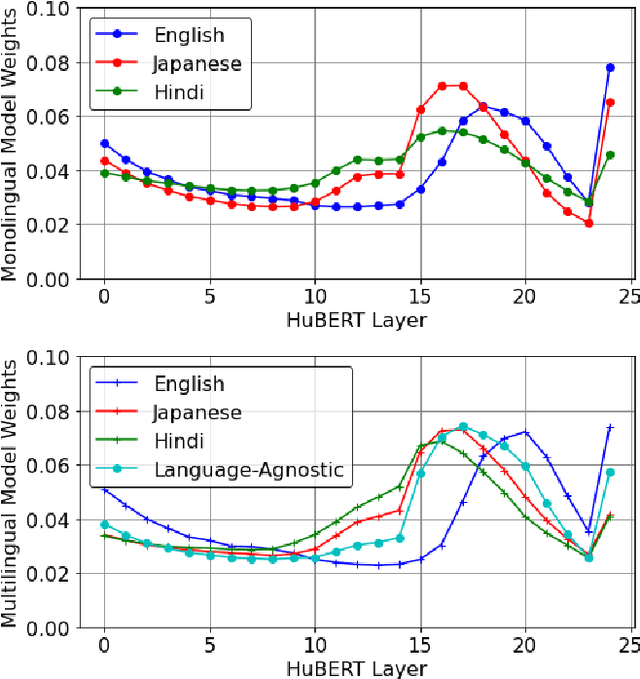
This work investigates the use of large-scale, pre-trained models (CLIP and HuBERT) for multilingual speech-image retrieval. For non-English speech-image retrieval, we outperform the current state-of-the-art performance by a wide margin when training separate models for each language, and show that a single model which processes speech in all three languages still achieves retrieval scores comparable with the prior state-of-the-art. We identify key differences in model behavior and performance between English and non-English settings, presumably attributable to the English-only pre-training of CLIP and HuBERT. Finally, we show that our models can be used for mono- and cross-lingual speech-text retrieval and cross-lingual speech-speech retrieval, despite never having seen any parallel speech-text or speech-speech data during training.
AfroDigits: A Community-Driven Spoken Digit Dataset for African Languages
Mar 22, 2023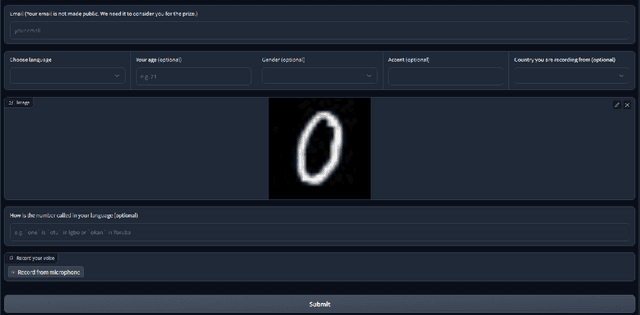
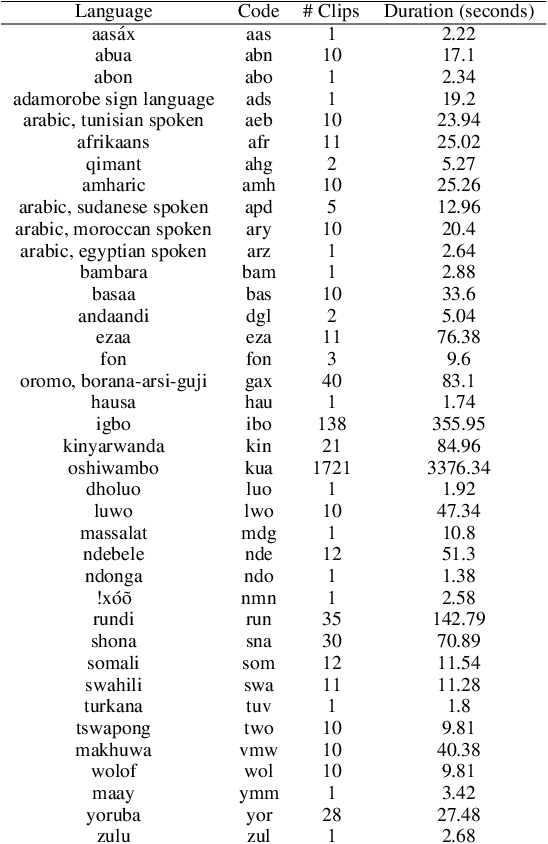
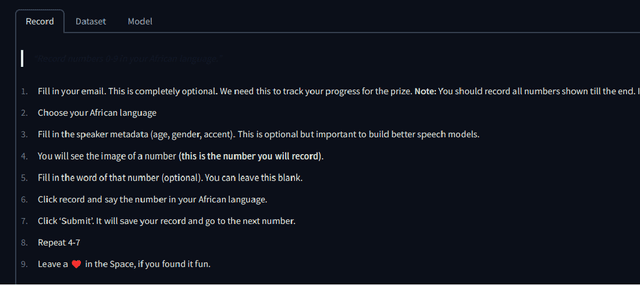
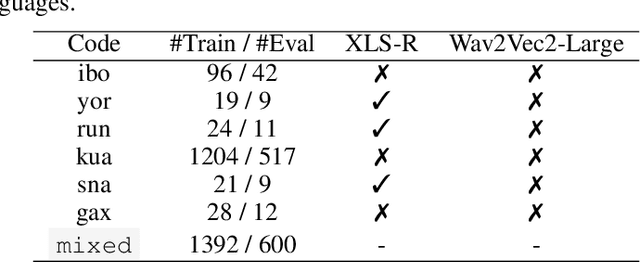
The advancement of speech technologies has been remarkable, yet its integration with African languages remains limited due to the scarcity of African speech corpora. To address this issue, we present AfroDigits, a minimalist, community-driven dataset of spoken digits for African languages, currently covering 38 African languages. As a demonstration of the practical applications of AfroDigits, we conduct audio digit classification experiments on six African languages [Igbo (ibo), Yoruba (yor), Rundi (run), Oshiwambo (kua), Shona (sna), and Oromo (gax)] using the Wav2Vec2.0-Large and XLS-R models. Our experiments reveal a useful insight on the effect of mixing African speech corpora during finetuning. AfroDigits is the first published audio digit dataset for African languages and we believe it will, among other things, pave the way for Afro-centric speech applications such as the recognition of telephone numbers, and street numbers. We release the dataset and platform publicly at https://huggingface.co/datasets/chrisjay/crowd-speech-africa and https://huggingface.co/spaces/chrisjay/afro-speech respectively.