 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Single-Factor Physical Video-to-Audio Generation
May 28, 2026Generative video-to-audio (V2A) models produce highly plausible soundtracks, but it remains unclear whether they capture the underlying physical processes. Existing evaluations emphasize perceptual realism and overlook physical correctness under controlled interventions. In this paper, we introduce FlatSounds, a benchmark that audits the physical reasoning of V2A models through: 1) controlled counterfactual pairs in which a single physical factor is varied, and 2) single-video pattern tests that probe internal consistency and directional trends. These settings test whether the generated audio correctly reflects specific physical properties and timings. Our evaluation of state-of-the-art models reveals a consistent trade-off: models rely more on text captions than the visual stream to infer physics and semantics. Captions generally improve physical and semantic accuracy, but paradoxically degrade temporal alignment. Our results highlight the need to move beyond audio quality toward learning physical processes directly from pixels. Finally, we find that our physics-based metrics correlate strongly with human preference tests on our own data. Project webpage: https://research.nvidia.com/labs/cosmos-lab/flatsounds/
Audio Flamingo Next: Next-Generation Open Audio-Language Models for Speech, Sound, and Music
Apr 13, 2026We present Audio Flamingo Next (AF-Next), the next-generation and most capable large audio-language model in the Audio Flamingo series, designed to advance understanding and reasoning over speech, environmental sounds and music. Compared to Audio Flamingo 3, AF-Next introduces: (i) a stronger foundational audio-language model that significantly improves accuracy across diverse audio understanding tasks; (ii) scalable strategies for constructing large-scale audio understanding and reasoning data beyond existing academic benchmarks; (iii) support for long and complex audio inputs up to 30 minutes; and (iv) Temporal Audio Chain-of-Thought, a new reasoning paradigm that explicitly grounds intermediate reasoning steps to timestamps in long audio, enabling fine-grained temporal alignment and improved interpretability. To enable these capabilities, we first conduct a systematic analysis of Audio Flamingo 3 to identify key gaps in audio understanding and reasoning. We then curate and scale new large-scale datasets totaling over 1 million hours to address these limitations and expand the existing AudioSkills-XL, LongAudio-XL, AF-Think and AF-Chat datasets. AF-Next is trained using a curriculum-based strategy spanning pre-training, mid-training and post-training stages. Extensive experiments across 20 audio understanding and reasoning benchmarks, including challenging long-audio tasks, show that AF-Next outperforms similarly sized open models by large margins and remains highly competitive with and sometimes surpasses, much larger open-weight and closed models. Beyond benchmark performance, AF-Next exhibits strong real-world utility and transfers well to unseen tasks, highlighting its robustness and generalization ability. In addition to all data, code and methods, we open-source 3 variants of AF-Next, including AF-Next-Instruct, AF-Next-Think and AF-Next-Captioner.
MMOU: A Massive Multi-Task Omni Understanding and Reasoning Benchmark for Long and Complex Real-World Videos
Mar 14, 2026Multimodal Large Language Models (MLLMs) have shown strong performance in visual and audio understanding when evaluated in isolation. However, their ability to jointly reason over omni-modal (visual, audio, and textual) signals in long and complex videos remains largely unexplored. We introduce MMOU, a new benchmark designed to systematically evaluate multimodal understanding and reasoning under these challenging, real-world conditions. MMOU consists of 15,000 carefully curated questions paired with 9038 web-collected videos of varying length, spanning diverse domains and exhibiting rich, tightly coupled audio-visual content. The benchmark covers 13 fundamental skill categories, all of which require integrating evidence across modalities and time. All questions are manually annotated across multiple turns by professional annotators, ensuring high quality and reasoning fidelity. We evaluate 20+ state-of-the-art open-source and proprietary multimodal models on MMOU. The results expose substantial performance gaps: the best closed-source model achieves only 64.2% accuracy, while the strongest open-source model reaches just 46.8%. Our results highlight the challenges of long-form omni-modal understanding, revealing that current models frequently fail to apply even fundamental skills in long videos. Through detailed analysis, we further identify systematic failure modes and provide insights into where and why current models break.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models
Nov 11, 2024We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates. Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360 HDR panorama generation, and finetuning for image customization.
Symbolic Music Generation with Non-Differentiable Rule Guided Diffusion
Feb 23, 2024



We study the problem of symbolic music generation (e.g., generating piano rolls), with a technical focus on non-differentiable rule guidance. Musical rules are often expressed in symbolic form on note characteristics, such as note density or chord progression, many of which are non-differentiable which pose a challenge when using them for guided diffusion. We propose Stochastic Control Guidance (SCG), a novel guidance method that only requires forward evaluation of rule functions that can work with pre-trained diffusion models in a plug-and-play way, thus achieving training-free guidance for non-differentiable rules for the first time. Additionally, we introduce a latent diffusion architecture for symbolic music generation with high time resolution, which can be composed with SCG in a plug-and-play fashion. Compared to standard strong baselines in symbolic music generation, this framework demonstrates marked advancements in music quality and rule-based controllability, outperforming current state-of-the-art generators in a variety of settings. For detailed demonstrations, code and model checkpoints, please visit our project website: https://scg-rule-guided-music.github.io/.
Multilingual Multiaccented Multispeaker TTS with RADTTS
Jan 24, 2023



We work to create a multilingual speech synthesis system which can generate speech with the proper accent while retaining the characteristics of an individual voice. This is challenging to do because it is expensive to obtain bilingual training data in multiple languages, and the lack of such data results in strong correlations that entangle speaker, language, and accent, resulting in poor transfer capabilities. To overcome this, we present a multilingual, multiaccented, multispeaker speech synthesis model based on RADTTS with explicit control over accent, language, speaker and fine-grained $F_0$ and energy features. Our proposed model does not rely on bilingual training data. We demonstrate an ability to control synthesized accent for any speaker in an open-source dataset comprising of 7 accents. Human subjective evaluation demonstrates that our model can better retain a speaker's voice and accent quality than controlled baselines while synthesizing fluent speech in all target languages and accents in our dataset.
SPACE: Speech-driven Portrait Animation with Controllable Expression
Dec 07, 2022



Animating portraits using speech has received growing attention in recent years, with various creative and practical use cases. An ideal generated video should have good lip sync with the audio, natural facial expressions and head motions, and high frame quality. In this work, we present SPACE, which uses speech and a single image to generate high-resolution, and expressive videos with realistic head pose, without requiring a driving video. It uses a multi-stage approach, combining the controllability of facial landmarks with the high-quality synthesis power of a pretrained face generator. SPACE also allows for the control of emotions and their intensities. Our method outperforms prior methods in objective metrics for image quality and facial motions and is strongly preferred by users in pair-wise comparisons. The project website is available at https://deepimagination.cc/SPACE/
Anomalous behaviour in loss-gradient based interpretability methods
Jul 15, 2022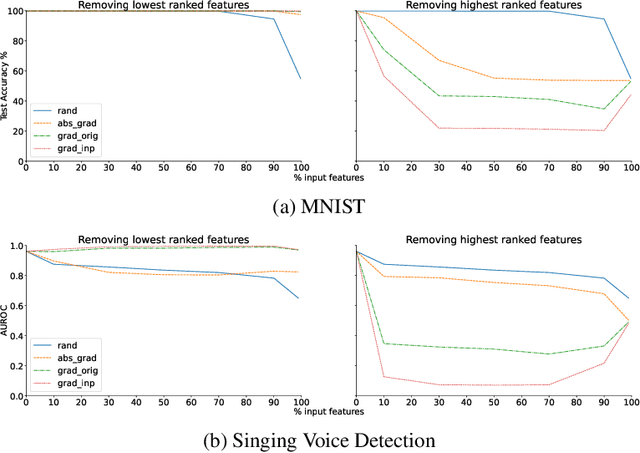
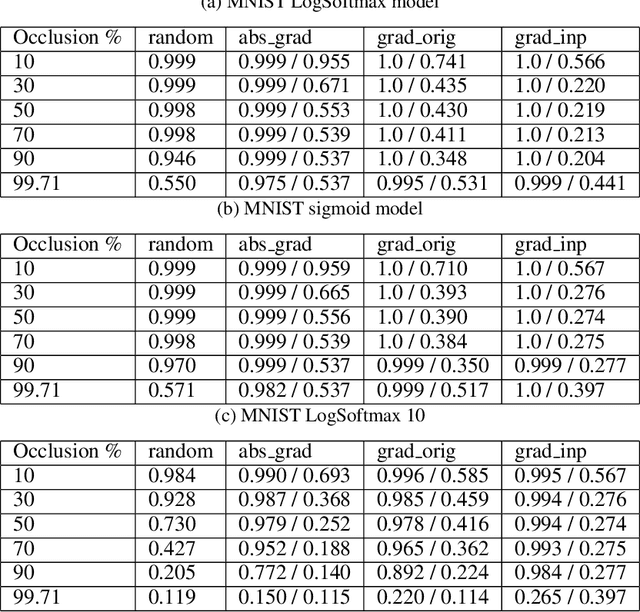

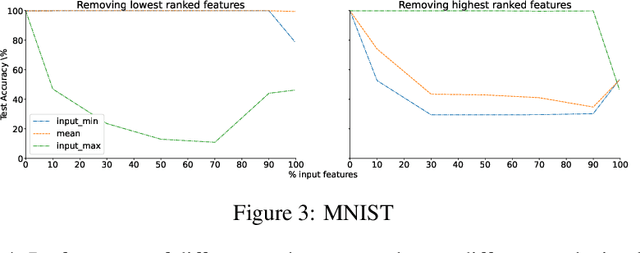
Loss-gradients are used to interpret the decision making process of deep learning models. In this work, we evaluate loss-gradient based attribution methods by occluding parts of the input and comparing the performance of the occluded input to the original input. We observe that the occluded input has better performance than the original across the test dataset under certain conditions. Similar behaviour is observed in sound and image recognition tasks. We explore different loss-gradient attribution methods, occlusion levels and replacement values to explain the phenomenon of performance improvement under occlusion.