 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechCLIP+: Self-supervised multi-task representation learning for speech via CLIP and speech-image data
Feb 10, 2024The recently proposed visually grounded speech model SpeechCLIP is an innovative framework that bridges speech and text through images via CLIP without relying on text transcription. On this basis, this paper introduces two extensions to SpeechCLIP. First, we apply the Continuous Integrate-and-Fire (CIF) module to replace a fixed number of CLS tokens in the cascaded architecture. Second, we propose a new hybrid architecture that merges the cascaded and parallel architectures of SpeechCLIP into a multi-task learning framework. Our experimental evaluation is performed on the Flickr8k and SpokenCOCO datasets. The results show that in the speech keyword extraction task, the CIF-based cascaded SpeechCLIP model outperforms the previous cascaded SpeechCLIP model using a fixed number of CLS tokens. Furthermore, through our hybrid architecture, cascaded task learning boosts the performance of the parallel branch in image-speech retrieval tasks.
Integrating Self-supervised Speech Model with Pseudo Word-level Targets from Visually-grounded Speech Model
Feb 08, 2024Recent advances in self-supervised speech models have shown significant improvement in many downstream tasks. However, these models predominantly centered on frame-level training objectives, which can fall short in spoken language understanding tasks that require semantic comprehension. Existing works often rely on additional speech-text data as intermediate targets, which is costly in the real-world setting. To address this challenge, we propose Pseudo-Word HuBERT (PW-HuBERT), a framework that integrates pseudo word-level targets into the training process, where the targets are derived from a visually-ground speech model, notably eliminating the need for speech-text paired data. Our experimental results on four spoken language understanding (SLU) benchmarks suggest the superiority of our model in capturing semantic information.
M-SpeechCLIP: Leveraging Large-Scale, Pre-Trained Models for Multilingual Speech to Image Retrieval
Nov 02, 2022



This work investigates the use of large-scale, pre-trained models (CLIP and HuBERT) for multilingual speech-image retrieval. For non-English speech-image retrieval, we outperform the current state-of-the-art performance by a wide margin when training separate models for each language, and show that a single model which processes speech in all three languages still achieves retrieval scores comparable with the prior state-of-the-art. We identify key differences in model behavior and performance between English and non-English settings, presumably attributable to the English-only pre-training of CLIP and HuBERT. Finally, we show that our models can be used for mono- and cross-lingual speech-text retrieval and cross-lingual speech-speech retrieval, despite never having seen any parallel speech-text or speech-speech data during training.
SpeechCLIP: Integrating Speech with Pre-Trained Vision and Language Model
Oct 03, 2022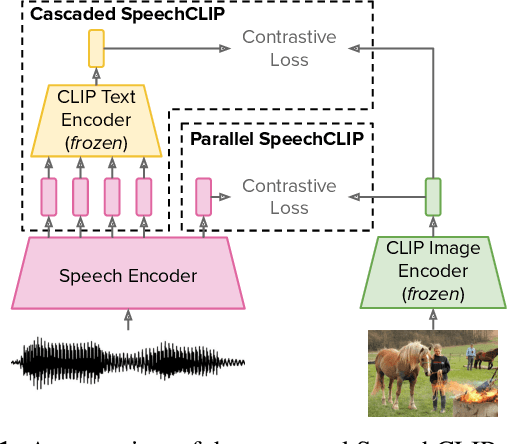

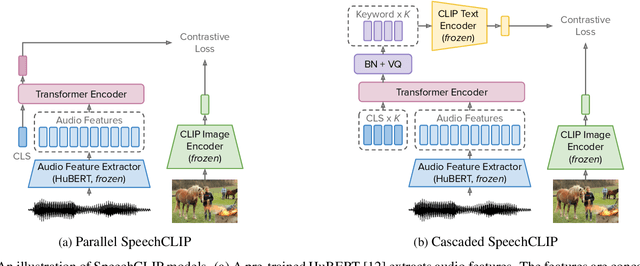
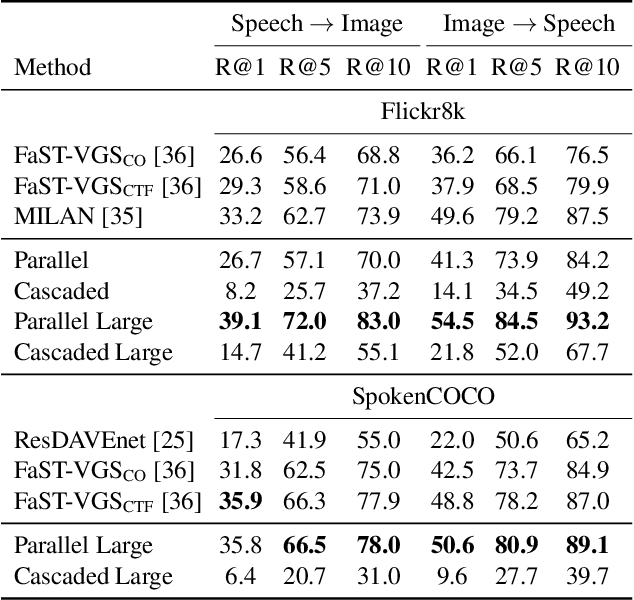
Data-driven speech processing models usually perform well with a large amount of text supervision, but collecting transcribed speech data is costly. Therefore, we propose SpeechCLIP, a novel framework bridging speech and text through images to enhance speech models without transcriptions. We leverage state-of-the-art pre-trained HuBERT and CLIP, aligning them via paired images and spoken captions with minimal fine-tuning. SpeechCLIP outperforms prior state-of-the-art on image-speech retrieval and performs zero-shot speech-text retrieval without direct supervision from transcriptions. Moreover, SpeechCLIP can directly retrieve semantically related keywords from speech.