 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfri-MCQA: Multimodal Cultural Question Answering for African Languages
Jan 09, 2026Africa is home to over one-third of the world's languages, yet remains underrepresented in AI research. We introduce Afri-MCQA, the first Multilingual Cultural Question-Answering benchmark covering 7.5k Q&A pairs across 15 African languages from 12 countries. The benchmark offers parallel English-African language Q&A pairs across text and speech modalities and was entirely created by native speakers. Benchmarking large language models (LLMs) on Afri-MCQA shows that open-weight models perform poorly across evaluated cultures, with near-zero accuracy on open-ended VQA when queried in native language or speech. To evaluate linguistic competence, we include control experiments meant to assess this specific aspect separate from cultural knowledge, and we observe significant performance gaps between native languages and English for both text and speech. These findings underscore the need for speech-first approaches, culturally grounded pretraining, and cross-lingual cultural transfer. To support more inclusive multimodal AI development in African languages, we release our Afri-MCQA under academic license or CC BY-NC 4.0 on HuggingFace (https://huggingface.co/datasets/Atnafu/Afri-MCQA)
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025
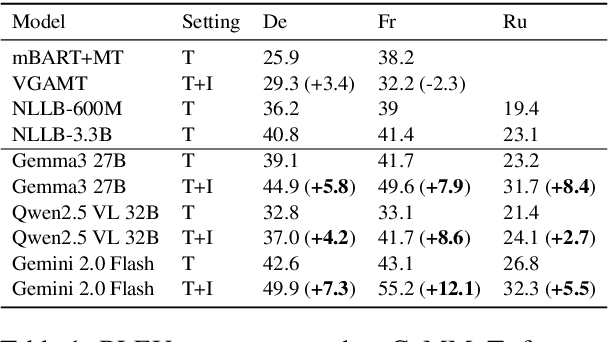

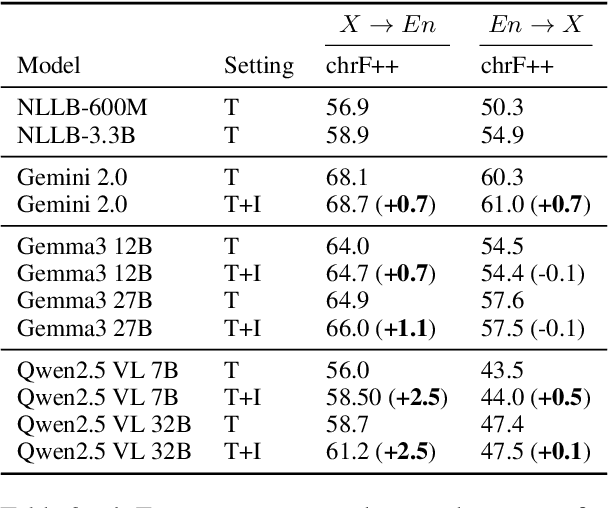
Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
Adapting Pretrained ASR Models to Low-resource Clinical Speech using Epistemic Uncertainty-based Data Selection
Jun 03, 2023While there has been significant progress in ASR, African-accented clinical ASR has been understudied due to a lack of training datasets. Building robust ASR systems in this domain requires large amounts of annotated or labeled data, for a wide variety of linguistically and morphologically rich accents, which are expensive to create. Our study aims to address this problem by reducing annotation expenses through informative uncertainty-based data selection. We show that incorporating epistemic uncertainty into our adaptation rounds outperforms several baseline results, established using state-of-the-art (SOTA) ASR models, while reducing the required amount of labeled data, and hence reducing annotation costs. Our approach also improves out-of-distribution generalization for very low-resource accents, demonstrating the viability of our approach for building generalizable ASR models in the context of accented African clinical ASR, where training datasets are predominantly scarce.