 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D Reconstruction from Sparse Dynamic Cameras
Jun 03, 2026Although dynamic 3D (i.e., 4D) reconstruction from a monocular dynamic camera has recently advanced, it remains fundamentally limited by depth ambiguity. In this paper, we focus on an alternative practical way, i.e., sparse dynamic camera setup, where a handful of independently moving cameras capture the same subjects. While keeping capture costs low, this setup introduces multi-view constraints and remains practical for real-world video production such as sports, concerts, and TV shows. Despite its potential, our experiments show that naive extensions of existing monocular or dense-fixed camera-based methods are insufficient since they fail to resolve the complex spatiotemporal inconsistencies across views and time. To fill this gap, we propose a simple yet effective 3D track initialization method designed to ensure spatiotemporal consistency by integrating inter-camera feature matching with intra-camera point tracking. Additionally, we incorporate a noise-robust depth-ordering regularization loss and a spatiotemporally diverse batch sampling strategy to enhance optimization stability and cross-view generalization. Furthermore, to address the lack of standardized benchmarks for this task, we introduce LetCamsGo, a new real-world video dataset with 5 sequences across 4 diverse environments, recorded by three independently moving cameras and one fixed camera. Comprehensive benchmarking on LetCamsGo demonstrated that our proposed framework improves 4D reconstruction quality in dynamic regions compared with baselines, paving the way for a low-cost 4D reconstruction paradigm in the wild.
HumanGif: Single-View Human Diffusion with Generative Prior
Feb 17, 2025



While previous single-view-based 3D human reconstruction methods made significant progress in novel view synthesis, it remains a challenge to synthesize both view-consistent and pose-consistent results for animatable human avatars from a single image input. Motivated by the success of 2D character animation, we propose <strong>HumanGif</strong>, a single-view human diffusion model with generative prior. Specifically, we formulate the single-view-based 3D human novel view and pose synthesis as a single-view-conditioned human diffusion process, utilizing generative priors from foundational diffusion models. To ensure fine-grained and consistent novel view and pose synthesis, we introduce a Human NeRF module in HumanGif to learn spatially aligned features from the input image, implicitly capturing the relative camera and human pose transformation. Furthermore, we introduce an image-level loss during optimization to bridge the gap between latent and image spaces in diffusion models. Extensive experiments on RenderPeople and DNA-Rendering datasets demonstrate that HumanGif achieves the best perceptual performance, with better generalizability for novel view and pose synthesis.
Hearing Anything Anywhere
Jun 11, 2024



Recent years have seen immense progress in 3D computer vision and computer graphics, with emerging tools that can virtualize real-world 3D environments for numerous Mixed Reality (XR) applications. However, alongside immersive visual experiences, immersive auditory experiences are equally vital to our holistic perception of an environment. In this paper, we aim to reconstruct the spatial acoustic characteristics of an arbitrary environment given only a sparse set of (roughly 12) room impulse response (RIR) recordings and a planar reconstruction of the scene, a setup that is easily achievable by ordinary users. To this end, we introduce DiffRIR, a differentiable RIR rendering framework with interpretable parametric models of salient acoustic features of the scene, including sound source directivity and surface reflectivity. This allows us to synthesize novel auditory experiences through the space with any source audio. To evaluate our method, we collect a dataset of RIR recordings and music in four diverse, real environments. We show that our model outperforms state-ofthe-art baselines on rendering monaural and binaural RIRs and music at unseen locations, and learns physically interpretable parameters characterizing acoustic properties of the sound source and surfaces in the scene.
The Whole Is Greater than the Sum of Its Parts: Improving DNN-based Music Source Separation
May 13, 2023This paper presents the crossing scheme (X-scheme) for improving the performance of deep neural network (DNN)-based music source separation (MSS) without increasing calculation cost. It consists of three components: (i) multi-domain loss (MDL), (ii) bridging operation, which couples the individual instrument networks, and (iii) combination loss (CL). MDL enables the taking advantage of the frequency- and time-domain representations of audio signals. We modify the target network, i.e., the network architecture of the original DNN-based MSS, by adding bridging paths for each output instrument to share their information. MDL is then applied to the combinations of the output sources as well as each independent source, hence we called it CL. MDL and CL can easily be applied to many DNN-based separation methods as they are merely loss functions that are only used during training and do not affect the inference step. Bridging operation does not increase the number of learnable parameters in the network. Experimental results showed that the validity of Open-Unmix (UMX) and densely connected dilated DenseNet (D3Net) extended with our X-scheme, respectively called X-UMX and X-D3Net, by comparing them with their original versions. We also verified the effectiveness of X-scheme in a large-scale data regime, showing its generality with respect to data size. X-UMX Large (X-UMXL), which was trained on large-scale internal data and used in our experiments, is newly available at https://github.com/asteroid-team/asteroid/tree/master/egs/musdb18/X-UMX.
A Versatile Diffusion-based Generative Refiner for Speech Enhancement
Oct 27, 2022


Although deep neural network (DNN)-based speech enhancement (SE) methods outperform the previous non-DNN-based ones, they often degrade the perceptual quality of generated outputs. To tackle this problem, We introduce a DNN-based generative refiner aiming to improve perceptual speech quality pre-processed by an SE method. As the refiner, we train a diffusion-based generative model by utilizing a dataset consisting of clean speech only. Then, the model replaces the degraded and distorted parts caused by a preceding SE method with newly generated clean parts by denoising diffusion restoration. Once our refiner is trained on a set of clean speech, it can be applied to various SE methods without additional training specialized for each SE module. Therefore, our refiner can be a versatile post-processing module w.r.t. SE methods and has high potential in terms of modularity. Experimental results show that our method improved perceptual speech quality regardless of the preceding SE methods used.
DiffRoll: Diffusion-based Generative Music Transcription with Unsupervised Pretraining Capability
Oct 11, 2022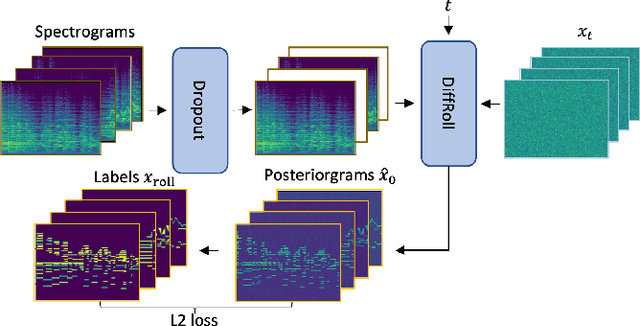
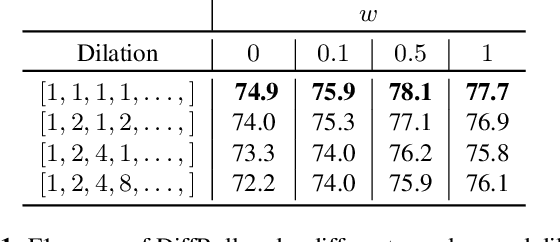
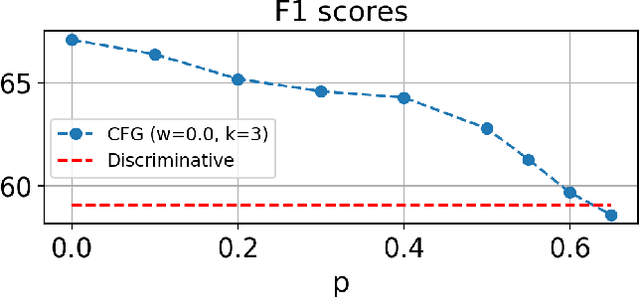

In this paper we propose a novel generative approach, DiffRoll, to tackle automatic music transcription (AMT). Instead of treating AMT as a discriminative task in which the model is trained to convert spectrograms into piano rolls, we think of it as a conditional generative task where we train our model to generate realistic looking piano rolls from pure Gaussian noise conditioned on spectrograms. This new AMT formulation enables DiffRoll to transcribe, generate and even inpaint music. Due to the classifier-free nature, DiffRoll is also able to be trained on unpaired datasets where only piano rolls are available. Our experiments show that DiffRoll outperforms its discriminative counterpart by 17.9 percentage points (ppt.) and our ablation studies also indicate that it outperforms similar existing methods by 3.70 ppt.
Improving Character Error Rate Is Not Equal to Having Clean Speech: Speech Enhancement for ASR Systems with Black-box Acoustic Models
Oct 12, 2021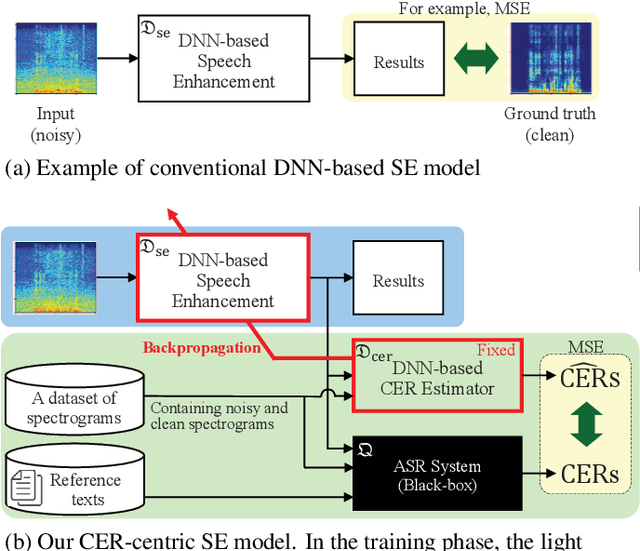
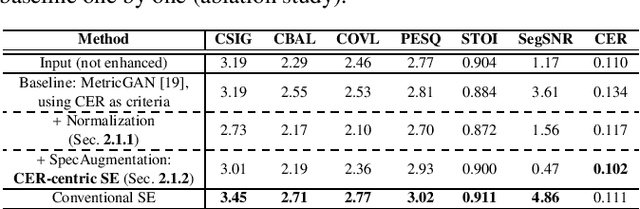
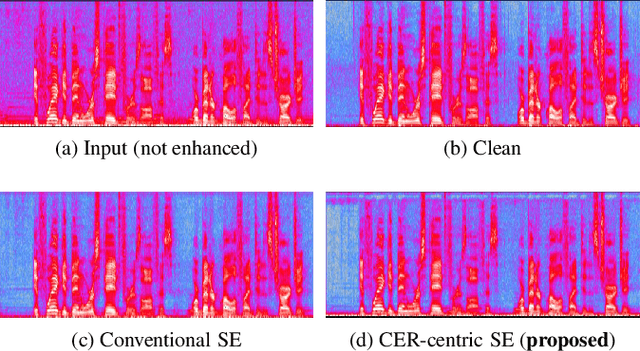
A deep neural network (DNN)-based speech enhancement (SE) aiming to maximize the performance of an automatic speech recognition (ASR) system is proposed in this paper. In order to optimize the DNN-based SE model in terms of the character error rate (CER), which is one of the metric to evaluate the ASR system and generally non-differentiable, our method uses two DNNs: one for speech processing and one for mimicking the output CERs derived through an acoustic model (AM). Then both of DNNs are alternately optimized in the training phase. Even if the AM is a black-box, e.g., like one provided by a third-party, the proposed method enables the DNN-based SE model to be optimized in terms of the CER since the DNN mimicking the AM is differentiable. Consequently, it becomes feasible to build CER-centric SE model that has no negative effect, e.g., additional calculation cost and changing network architecture, on the inference phase since our method is merely a training scheme for the existing DNN-based methods. Experimental results show that our method improved CER by 7.3% relative derived through a black-box AM although certain noise levels are kept.
Manifold-Aware Deep Clustering: Maximizing Angles between Embedding Vectors Based on Regular Simplex
Jun 16, 2021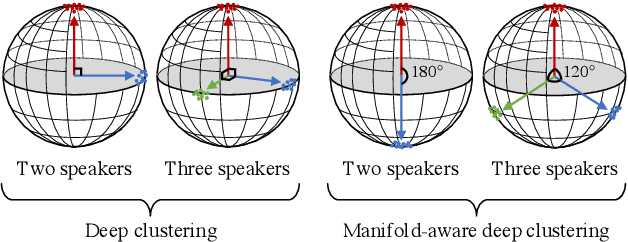
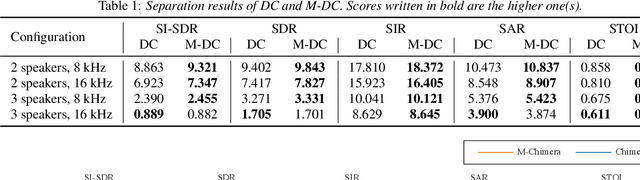
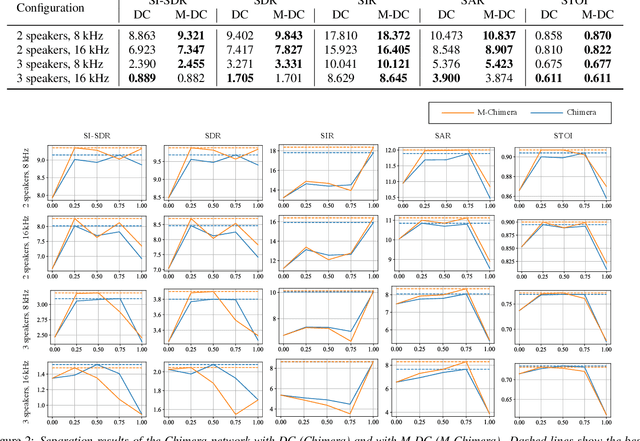
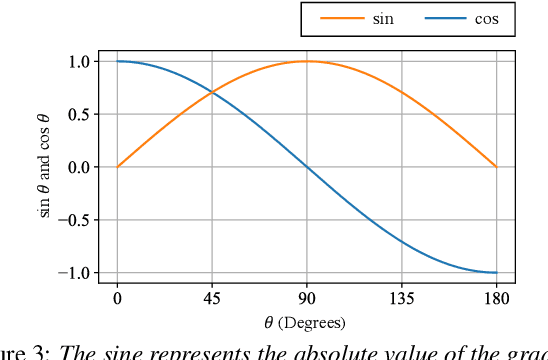
This paper presents a new deep clustering (DC) method called manifold-aware DC (M-DC) that can enhance hyperspace utilization more effectively than the original DC. The original DC has a limitation in that a pair of two speakers has to be embedded having an orthogonal relationship due to its use of the one-hot vector-based loss function, while our method derives a unique loss function aimed at maximizing the target angle in the hyperspace based on the nature of a regular simplex. Our proposed loss imposes a higher penalty than the original DC when the speaker is assigned incorrectly. The change from DC to M-DC can be easily achieved by rewriting just one term in the loss function of DC, without any other modifications to the network architecture or model parameters. As such, our method has high practicability because it does not affect the original inference part. The experimental results show that the proposed method improves the performances of the original DC and its expansion method.