 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ICASSP 2023 Deep Speech Enhancement Challenge
Mar 21, 2023
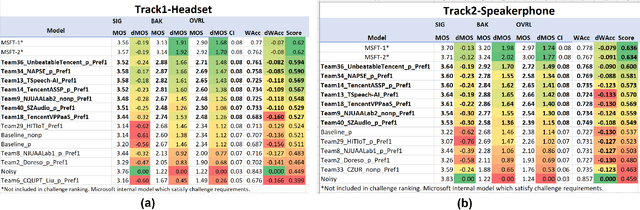
Deep Speech Enhancement Challenge is the 5th edition of deep noise suppression (DNS) challenges organized at ICASSP 2023 Signal Processing Grand Challenges. DNS challenges were organized during 2019-2023 to stimulate research in deep speech enhancement (DSE). Previous DNS challenges were organized at INTERSPEECH 2020, ICASSP 2021, INTERSPEECH 2021, and ICASSP 2022. From prior editions, we learnt that improving signal quality (SIG) is challenging particularly in presence of simultaneously active interfering talkers and noise. This challenge aims to develop models for joint denosing, dereverberation and suppression of interfering talkers. When primary talker wears a headphone, certain acoustic properties of their speech such as direct-to-reverberation (DRR), signal to noise ratio (SNR) etc. make it possible to suppress neighboring talkers even without enrollment data for primary talker. This motivated us to create two tracks for this challenge: (i) Track-1 Headset; (ii) Track-2 Speakerphone. Both tracks has fullband (48kHz) training data and testset, and each testclips has a corresponding enrollment data (10-30s duration) for primary talker. Each track invited submissions of personalized and non-personalized models all of which are evaluated through same subjective evaluation. Most models submitted to challenge were personalized models, same team is winner in both tracks where the best models has improvement of 0.145 and 0.141 in challenge's Score as compared to noisy blind testset.
A Preliminary Study on Augmenting Speech Emotion Recognition using a Diffusion Model
May 19, 2023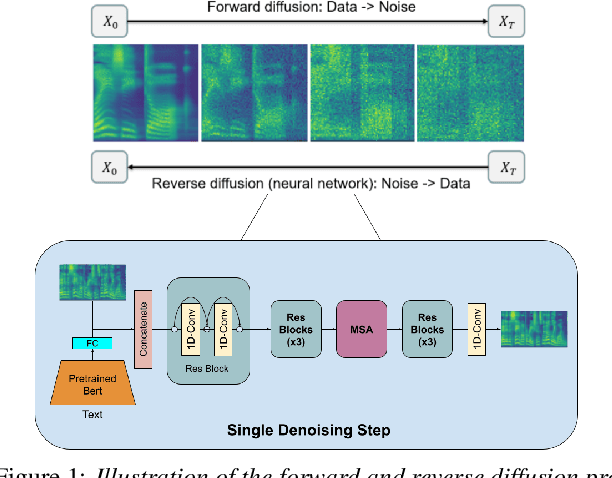
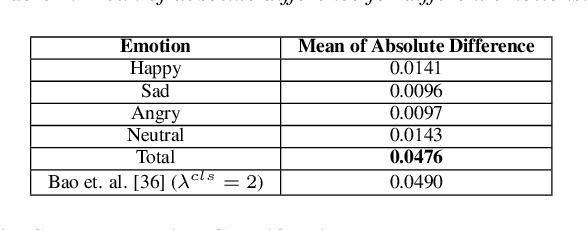


In this paper, we propose to utilise diffusion models for data augmentation in speech emotion recognition (SER). In particular, we present an effective approach to utilise improved denoising diffusion probabilistic models (IDDPM) to generate synthetic emotional data. We condition the IDDPM with the textual embedding from bidirectional encoder representations from transformers (BERT) to generate high-quality synthetic emotional samples in different speakers' voices\footnote{synthetic samples URL: \url{https://emulationai.com/research/diffusion-ser.}}. We implement a series of experiments and show that better quality synthetic data helps improve SER performance. We compare results with generative adversarial networks (GANs) and show that the proposed model generates better-quality synthetic samples that can considerably improve the performance of SER when augmented with synthetic data.
Parameter-Efficient Learning for Text-to-Speech Accent Adaptation
May 18, 2023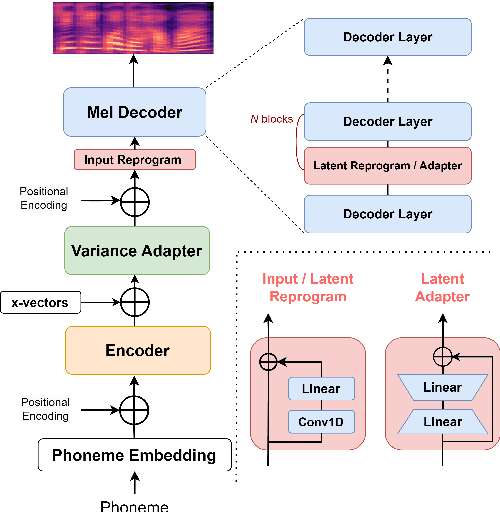
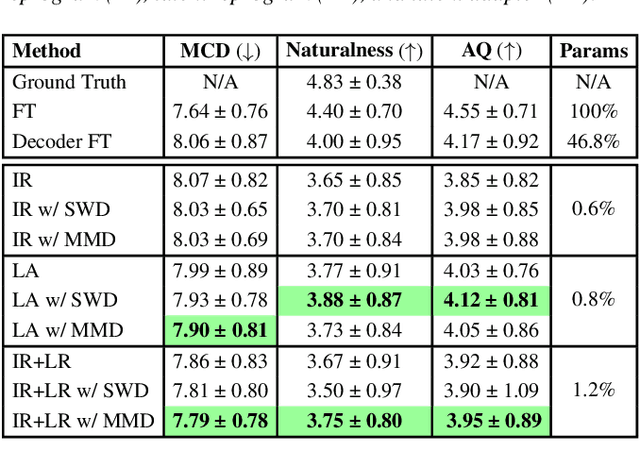
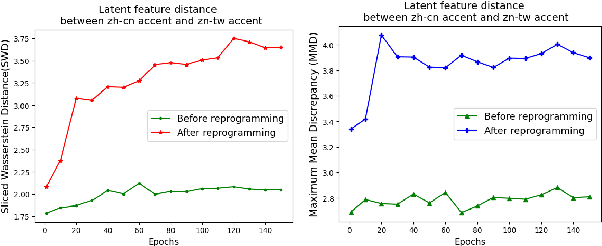
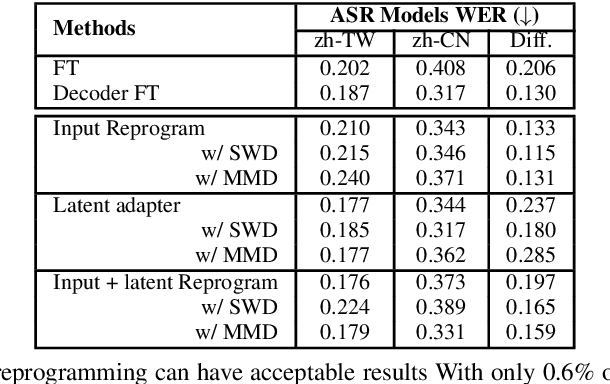
This paper presents a parameter-efficient learning (PEL) to develop a low-resource accent adaptation for text-to-speech (TTS). A resource-efficient adaptation from a frozen pre-trained TTS model is developed by using only 1.2\% to 0.8\% of original trainable parameters to achieve competitive performance in voice synthesis. Motivated by a theoretical foundation of optimal transport (OT), this study carries out PEL for TTS where an auxiliary unsupervised loss based on OT is introduced to maximize a difference between the pre-trained source domain and the (unseen) target domain, in addition to its supervised training loss. Further, we leverage upon this unsupervised loss refinement to boost system performance via either sliced Wasserstein distance or maximum mean discrepancy. The merit of this work is demonstrated by fulfilling PEL solutions based on residual adapter learning, and model reprogramming when evaluating the Mandarin accent adaptation. Experiment results show that the proposed methods can achieve competitive naturalness with parameter-efficient decoder fine-tuning, and the auxiliary unsupervised loss improves model performance empirically.
Knowledge-Aware Audio-Grounded Generative Slot Filling for Limited Annotated Data
Jul 04, 2023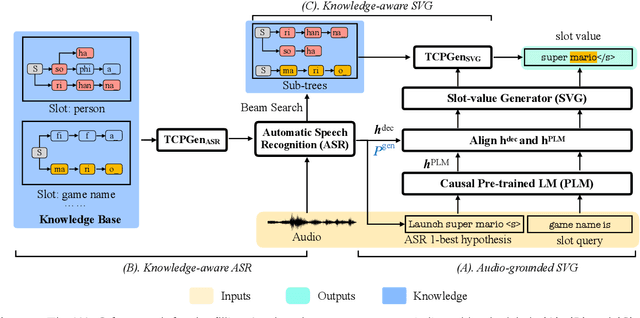
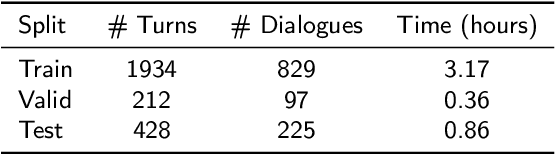
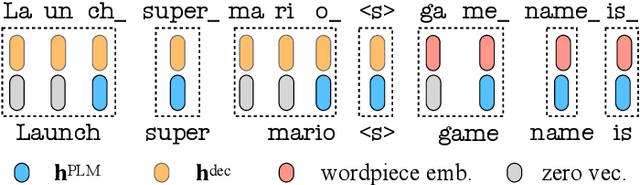

Manually annotating fine-grained slot-value labels for task-oriented dialogue (ToD) systems is an expensive and time-consuming endeavour. This motivates research into slot-filling methods that operate with limited amounts of labelled data. Moreover, the majority of current work on ToD is based solely on text as the input modality, neglecting the additional challenges of imperfect automatic speech recognition (ASR) when working with spoken language. In this work, we propose a Knowledge-Aware Audio-Grounded generative slot-filling framework, termed KA2G, that focuses on few-shot and zero-shot slot filling for ToD with speech input. KA2G achieves robust and data-efficient slot filling for speech-based ToD by 1) framing it as a text generation task, 2) grounding text generation additionally in the audio modality, and 3) conditioning on available external knowledge (e.g. a predefined list of possible slot values). We show that combining both modalities within the KA2G framework improves the robustness against ASR errors. Further, the knowledge-aware slot-value generator in KA2G, implemented via a pointer generator mechanism, particularly benefits few-shot and zero-shot learning. Experiments, conducted on the standard speech-based single-turn SLURP dataset and a multi-turn dataset extracted from a commercial ToD system, display strong and consistent gains over prior work, especially in few-shot and zero-shot setups.
Refining a Deep Learning-based Formant Tracker using Linear Prediction Methods
Aug 17, 2023In this study, formant tracking is investigated by refining the formants tracked by an existing data-driven tracker, DeepFormants, using the formants estimated in a model-driven manner by linear prediction (LP)-based methods. As LP-based formant estimation methods, conventional covariance analysis (LP-COV) and the recently proposed quasi-closed phase forward-backward (QCP-FB) analysis are used. In the proposed refinement approach, the contours of the three lowest formants are first predicted by the data-driven DeepFormants tracker, and the predicted formants are replaced frame-wise with local spectral peaks shown by the model-driven LP-based methods. The refinement procedure can be plugged into the DeepFormants tracker with no need for any new data learning. Two refined DeepFormants trackers were compared with the original DeepFormants and with five known traditional trackers using the popular vocal tract resonance (VTR) corpus. The results indicated that the data-driven DeepFormants trackers outperformed the conventional trackers and that the best performance was obtained by refining the formants predicted by DeepFormants using QCP-FB analysis. In addition, by tracking formants using VTR speech that was corrupted by additive noise, the study showed that the refined DeepFormants trackers were more resilient to noise than the reference trackers. In general, these results suggest that LP-based model-driven approaches, which have traditionally been used in formant estimation, can be combined with a modern data-driven tracker easily with no further training to improve the tracker's performance.
ClArTTS: An Open-Source Classical Arabic Text-to-Speech Corpus
Feb 28, 2023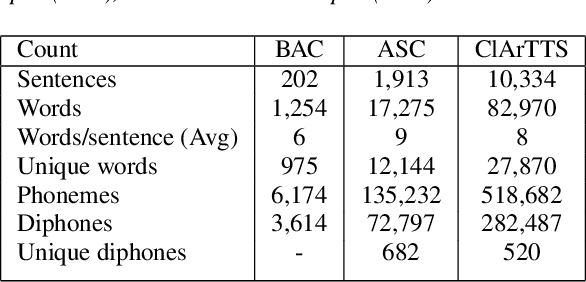
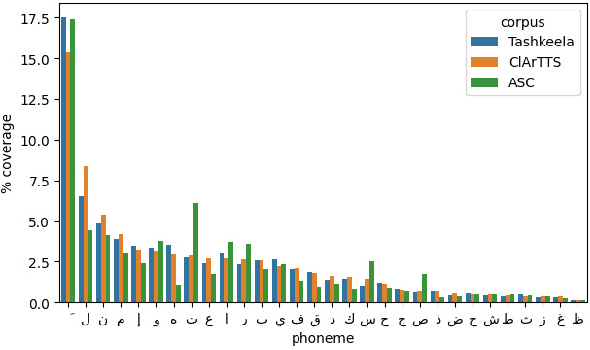
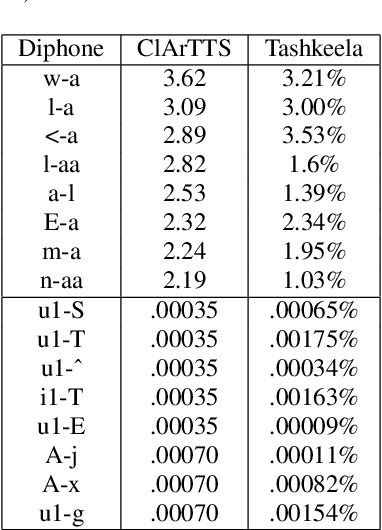
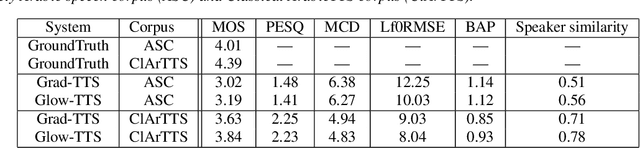
At present, Text-to-speech (TTS) systems that are trained with high-quality transcribed speech data using end-to-end neural models can generate speech that is intelligible, natural, and closely resembles human speech. These models are trained with relatively large single-speaker professionally recorded audio, typically extracted from audiobooks. Meanwhile, due to the scarcity of freely available speech corpora of this kind, a larger gap exists in Arabic TTS research and development. Most of the existing freely available Arabic speech corpora are not suitable for TTS training as they contain multi-speaker casual speech with variations in recording conditions and quality, whereas the corpus curated for speech synthesis are generally small in size and not suitable for training state-of-the-art end-to-end models. In a move towards filling this gap in resources, we present a speech corpus for Classical Arabic Text-to-Speech (ClArTTS) to support the development of end-to-end TTS systems for Arabic. The speech is extracted from a LibriVox audiobook, which is then processed, segmented, and manually transcribed and annotated. The final ClArTTS corpus contains about 12 hours of speech from a single male speaker sampled at 40100 kHz. In this paper, we describe the process of corpus creation and provide details of corpus statistics and a comparison with existing resources. Furthermore, we develop two TTS systems based on Grad-TTS and Glow-TTS and illustrate the performance of the resulting systems via subjective and objective evaluations. The corpus will be made publicly available at www.clartts.com for research purposes, along with the baseline TTS systems demo.
SynthVSR: Scaling Up Visual Speech Recognition With Synthetic Supervision
Apr 03, 2023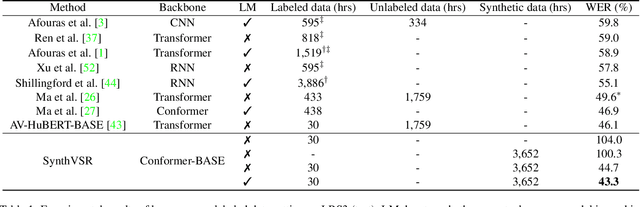
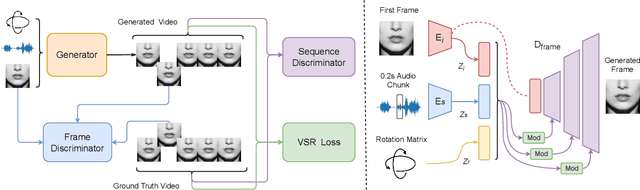
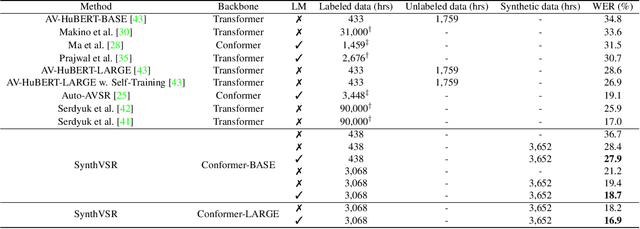

Recently reported state-of-the-art results in visual speech recognition (VSR) often rely on increasingly large amounts of video data, while the publicly available transcribed video datasets are limited in size. In this paper, for the first time, we study the potential of leveraging synthetic visual data for VSR. Our method, termed SynthVSR, substantially improves the performance of VSR systems with synthetic lip movements. The key idea behind SynthVSR is to leverage a speech-driven lip animation model that generates lip movements conditioned on the input speech. The speech-driven lip animation model is trained on an unlabeled audio-visual dataset and could be further optimized towards a pre-trained VSR model when labeled videos are available. As plenty of transcribed acoustic data and face images are available, we are able to generate large-scale synthetic data using the proposed lip animation model for semi-supervised VSR training. We evaluate the performance of our approach on the largest public VSR benchmark - Lip Reading Sentences 3 (LRS3). SynthVSR achieves a WER of 43.3% with only 30 hours of real labeled data, outperforming off-the-shelf approaches using thousands of hours of video. The WER is further reduced to 27.9% when using all 438 hours of labeled data from LRS3, which is on par with the state-of-the-art self-supervised AV-HuBERT method. Furthermore, when combined with large-scale pseudo-labeled audio-visual data SynthVSR yields a new state-of-the-art VSR WER of 16.9% using publicly available data only, surpassing the recent state-of-the-art approaches trained with 29 times more non-public machine-transcribed video data (90,000 hours). Finally, we perform extensive ablation studies to understand the effect of each component in our proposed method.
Acoustic absement in detail: Quantifying acoustic differences across time-series representations of speech data
Apr 14, 2023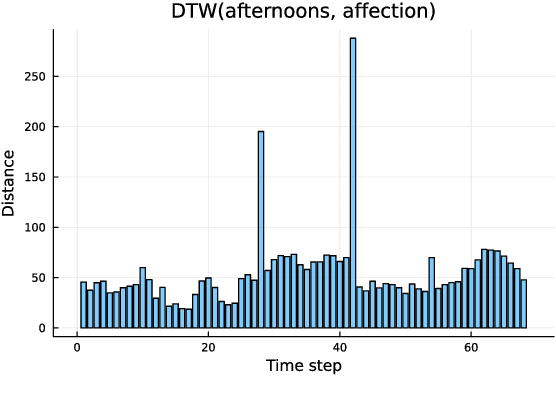
The speech signal is a consummate example of time-series data. The acoustics of the signal change over time, sometimes dramatically. Yet, the most common type of comparison we perform in phonetics is between instantaneous acoustic measurements, such as formant values. In the present paper, I discuss the concept of absement as a quantification of differences between two time-series. I then provide an experimental example of absement applied to phonetic analysis for human and/or computer speech recognition. The experiment is a template-based speech recognition task, using dynamic time warping to compare the acoustics between recordings of isolated words. A recognition accuracy of 57.9% was achieved. The results of the experiment are discussed in terms of using absement as a tool, as well as the implications of using acoustics-only models of spoken word recognition with the word as the smallest discrete linguistic unit.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
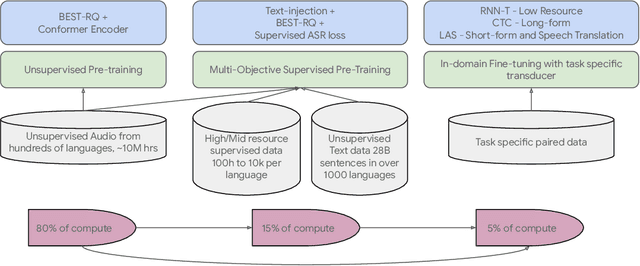
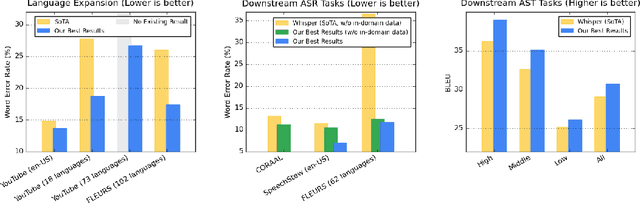

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
LAST: Scalable Lattice-Based Speech Modelling in JAX
Apr 25, 2023
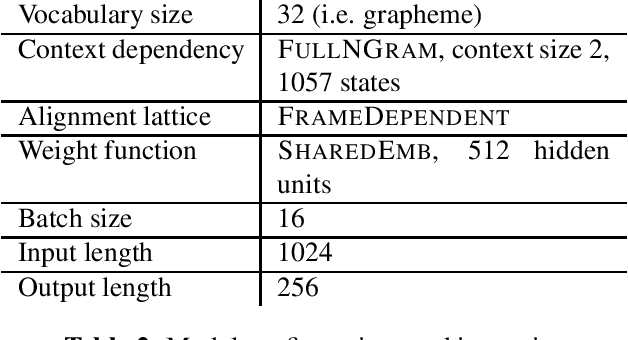
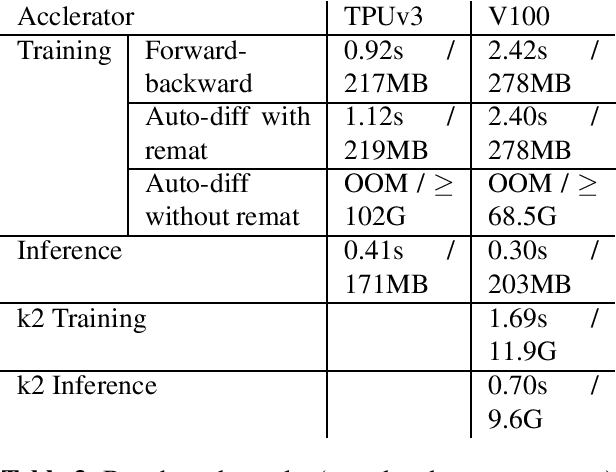
We introduce LAST, a LAttice-based Speech Transducer library in JAX. With an emphasis on flexibility, ease-of-use, and scalability, LAST implements differentiable weighted finite state automaton (WFSA) algorithms needed for training \& inference that scale to a large WFSA such as a recognition lattice over the entire utterance. Despite these WFSA algorithms being well-known in the literature, new challenges arise from performance characteristics of modern architectures, and from nuances in automatic differentiation. We describe a suite of generally applicable techniques employed in LAST to address these challenges, and demonstrate their effectiveness with benchmarks on TPUv3 and V100 GPU.