 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multidimensional measurement of photorealistic avatar quality of experience
Nov 13, 2024



Photorealistic avatars are human avatars that look, move, and talk like real people. The performance of photorealistic avatars has significantly improved recently based on objective metrics such as PSNR, SSIM, LPIPS, FID, and FVD. However, recent photorealistic avatar publications do not provide subjective tests of the avatars to measure human usability factors. We provide an open source test framework to subjectively measure photorealistic avatar performance in ten dimensions: realism, trust, comfortableness using, comfortableness interacting with, appropriateness for work, creepiness, formality, affinity, resemblance to the person, and emotion accuracy. We show that the correlation of nine of these subjective metrics with PSNR, SSIM, LPIPS, FID, and FVD is weak, and moderate for emotion accuracy. The crowdsourced subjective test framework is highly reproducible and accurate when compared to a panel of experts. We analyze a wide range of avatars from photorealistic to cartoon-like and show that some photorealistic avatars are approaching real video performance based on these dimensions. We also find that for avatars above a certain level of realism, eight of these measured dimensions are strongly correlated. In particular, for photorealistic avatars there is a linear relationship between avatar affinity and realism; in other words, there is no uncanny valley effect for photorealistic avatars in the telecommunication scenario. We provide several extensions of this test framework for future work and discuss design implications for telecommunication systems. The test framework is available at https://github.com/microsoft/P.910.
Streetwise Agents: Empowering Offline RL Policies to Outsmart Exogenous Stochastic Disturbances in RTC
Nov 11, 2024



The difficulty of exploring and training online on real production systems limits the scope of real-time online data/feedback-driven decision making. The most feasible approach is to adopt offline reinforcement learning from limited trajectory samples. However, after deployment, such policies fail due to exogenous factors that temporarily or permanently disturb/alter the transition distribution of the assumed decision process structure induced by offline samples. This results in critical policy failures and generalization errors in sensitive domains like Real-Time Communication (RTC). We solve this crucial problem of identifying robust actions in presence of domain shifts due to unseen exogenous stochastic factors in the wild. As it is impossible to learn generalized offline policies within the support of offline data that are robust to these unseen exogenous disturbances, we propose a novel post-deployment shaping of policies (Streetwise), conditioned on real-time characterization of out-of-distribution sub-spaces. This leads to robust actions in bandwidth estimation (BWE) of network bottlenecks in RTC and in standard benchmarks. Our extensive experimental results on BWE and other standard offline RL benchmark environments demonstrate a significant improvement ($\approx$ 18% on some scenarios) in final returns wrt. end-user metrics over state-of-the-art baselines.
Real-time Bandwidth Estimation from Offline Expert Demonstrations
Sep 23, 2023



In this work, we tackle the problem of bandwidth estimation (BWE) for real-time communication systems; however, in contrast to previous works, we leverage the vast efforts of prior heuristic-based BWE methods and synergize these approaches with deep learning-based techniques. Our work addresses challenges in generalizing to unseen network dynamics and extracting rich representations from prior experience, two key challenges in integrating data-driven bandwidth estimators into real-time systems. To that end, we propose Merlin, the first purely offline, data-driven solution to BWE that harnesses prior heuristic-based methods to extract an expert BWE policy. Through a series of experiments, we demonstrate that Merlin surpasses state-of-the-art heuristic-based and deep learning-based bandwidth estimators in terms of objective quality of experience metrics while generalizing beyond the offline world to in-the-wild network deployments where Merlin achieves a 42.85% and 12.8% reduction in packet loss and delay, respectively, when compared against WebRTC in inter-continental videoconferencing calls. We hope that Merlin's offline-oriented design fosters new strategies for real-time network control.
A Real-Time Active Speaker Detection System Integrating an Audio-Visual Signal with a Spatial Querying Mechanism
Sep 15, 2023



We introduce a distinctive real-time, causal, neural network-based active speaker detection system optimized for low-power edge computing. This system drives a virtual cinematography module and is deployed on a commercial device. The system uses data originating from a microphone array and a 360-degree camera. Our network requires only 127 MFLOPs per participant, for a meeting with 14 participants. Unlike previous work, we examine the error rate of our network when the computational budget is exhausted, and find that it exhibits graceful degradation, allowing the system to operate reasonably well even in this case. Departing from conventional DOA estimation approaches, our network learns to query the available acoustic data, considering the detected head locations. We train and evaluate our algorithm on a realistic meetings dataset featuring up to 14 participants in the same meeting, overlapped speech, and other challenging scenarios.
LSTM-based Video Quality Prediction Accounting for Temporal Distortions in Videoconferencing Calls
Mar 22, 2023



Current state-of-the-art video quality models, such as VMAF, give excellent prediction results by comparing the degraded video with its reference video. However, they do not consider temporal distortions (e.g., frame freezes or skips) that occur during videoconferencing calls. In this paper, we present a data-driven approach for modeling such distortions automatically by training an LSTM with subjective quality ratings labeled via crowdsourcing. The videos were collected from live videoconferencing calls in 83 different network conditions. We applied QR codes as markers on the source videos to create aligned references and compute temporal features based on the alignment vectors. Using these features together with VMAF core features, our proposed model achieves a PCC of 0.99 on the validation set. Furthermore, our model outputs per-frame quality that gives detailed insight into the cause of video quality impairments. The VCM model and dataset are open-sourced at https://github.com/microsoft/Video_Call_MOS.
ICASSP 2023 Deep Speech Enhancement Challenge
Mar 21, 2023
Deep Speech Enhancement Challenge is the 5th edition of deep noise suppression (DNS) challenges organized at ICASSP 2023 Signal Processing Grand Challenges. DNS challenges were organized during 2019-2023 to stimulate research in deep speech enhancement (DSE). Previous DNS challenges were organized at INTERSPEECH 2020, ICASSP 2021, INTERSPEECH 2021, and ICASSP 2022. From prior editions, we learnt that improving signal quality (SIG) is challenging particularly in presence of simultaneously active interfering talkers and noise. This challenge aims to develop models for joint denosing, dereverberation and suppression of interfering talkers. When primary talker wears a headphone, certain acoustic properties of their speech such as direct-to-reverberation (DRR), signal to noise ratio (SNR) etc. make it possible to suppress neighboring talkers even without enrollment data for primary talker. This motivated us to create two tracks for this challenge: (i) Track-1 Headset; (ii) Track-2 Speakerphone. Both tracks has fullband (48kHz) training data and testset, and each testclips has a corresponding enrollment data (10-30s duration) for primary talker. Each track invited submissions of personalized and non-personalized models all of which are evaluated through same subjective evaluation. Most models submitted to challenge were personalized models, same team is winner in both tracks where the best models has improvement of 0.145 and 0.141 in challenge's Score as compared to noisy blind testset.
ICASSP 2022 Deep Noise Suppression Challenge
Feb 27, 2022
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. This is the 4th DNS challenge, with the previous editions held at INTERSPEECH 2020, ICASSP 2021, and INTERSPEECH 2021. We open-source datasets and test sets for researchers to train their deep noise suppression models, as well as a subjective evaluation framework based on ITU-T P.835 to rate and rank-order the challenge entries. We provide access to DNSMOS P.835 and word accuracy (WAcc) APIs to challenge participants to help with iterative model improvements. In this challenge, we introduced the following changes: (i) Included mobile device scenarios in the blind test set; (ii) Included a personalized noise suppression track with baseline; (iii) Added WAcc as an objective metric; (iv) Included DNSMOS P.835; (v) Made the training datasets and test sets fullband (48 kHz). We use an average of WAcc and subjective scores P.835 SIG, BAK, and OVRL to get the final score for ranking the DNS models. We believe that as a research community, we still have a long way to go in achieving excellent speech quality in challenging noisy real-world scenarios.
Performance optimizations on deep noise suppression models
Oct 08, 2021
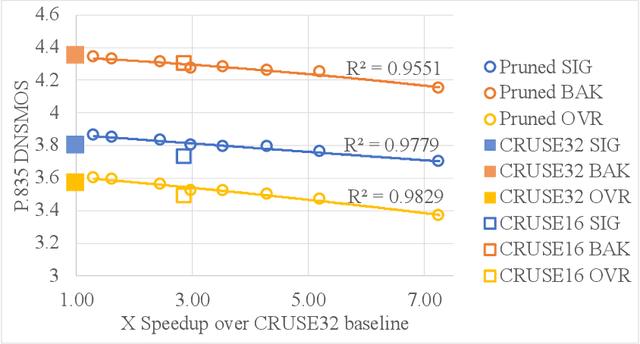
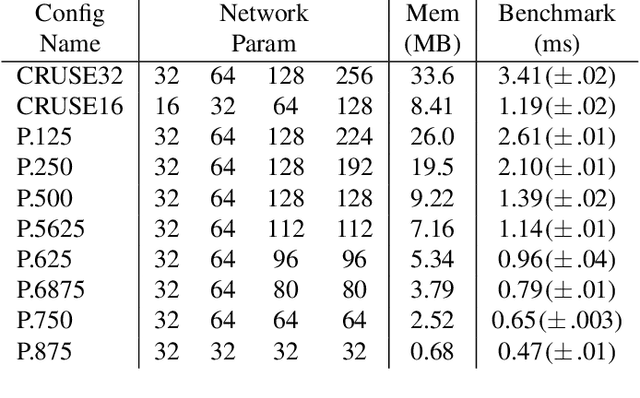
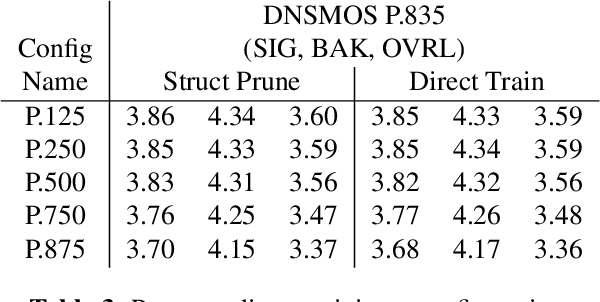
We study the role of magnitude structured pruning as an architecture search to speed up the inference time of a deep noise suppression (DNS) model. While deep learning approaches have been remarkably successful in enhancing audio quality, their increased complexity inhibits their deployment in real-time applications. We achieve up to a 7.25X inference speedup over the baseline, with a smooth model performance degradation. Ablation studies indicate that our proposed network re-parameterization (i.e., size per layer) is the major driver of the speedup, and that magnitude structured pruning does comparably to directly training a model in the smaller size. We report inference speed because a parameter reduction does not necessitate speedup, and we measure model quality using an accurate non-intrusive objective speech quality metric.
DNSMOS P.835: A Non-Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors
Oct 08, 2021
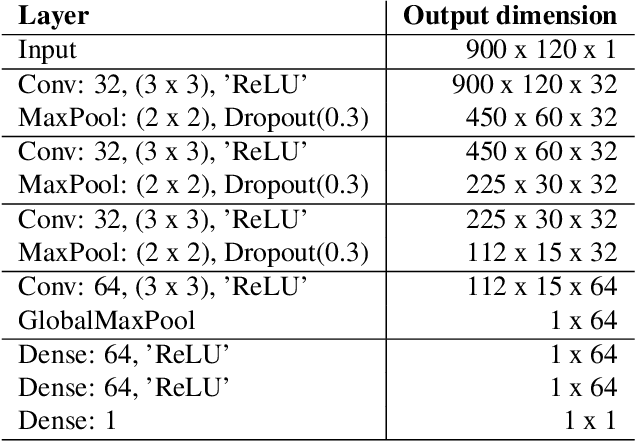
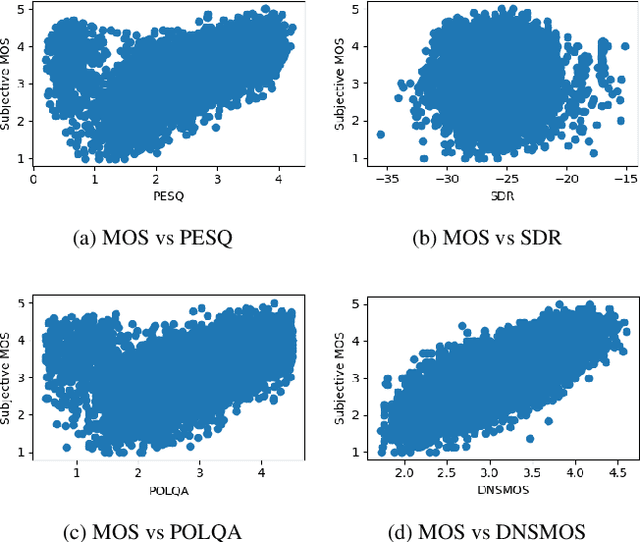
Human subjective evaluation is the gold standard to evaluate speech quality optimized for human perception. Perceptual objective metrics serve as a proxy for subjective scores. We have recently developed a non-intrusive speech quality metric called Deep Noise Suppression Mean Opinion Score (DNSMOS) using the scores from ITU-T Rec. P.808 subjective evaluation. The P.808 scores reflect the overall quality of the audio clip. ITU-T Rec. P.835 subjective evaluation framework gives the standalone quality scores of speech and background noise in addition to the overall quality. In this work, we train an objective metric based on P.835 human ratings that outputs 3 scores: i) speech quality (SIG), ii) background noise quality (BAK), and iii) the overall quality (OVRL) of the audio. The developed metric is highly correlated with human ratings, with a Pearson's Correlation Coefficient (PCC)=0.94 for SIG and PCC=0.98 for BAK and OVRL. This is the first non-intrusive P.835 predictor we are aware of. DNSMOS P.835 is made publicly available as an Azure service.
Interspeech 2021 Deep Noise Suppression Challenge
Jan 10, 2021
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. We recently organized a DNS challenge special session at INTERSPEECH and ICASSP 2020. We open-sourced training and test datasets for the wideband scenario. We also open-sourced a subjective evaluation framework based on ITU-T standard P.808, which was also used to evaluate participants of the challenge. Many researchers from academia and industry made significant contributions to push the field forward, yet even the best noise suppressor was far from achieving superior speech quality in challenging scenarios. In this version of the challenge organized at INTERSPEECH 2021, we are expanding both our training and test datasets to accommodate full band scenarios. The two tracks in this challenge will focus on real-time denoising for (i) wide band, and(ii) full band scenarios. We are also making available a reliable non-intrusive objective speech quality metric called DNSMOS for the participants to use during their development phase.