 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Audio Diffusion Model for Speech Synthesis: A Survey on Text To Speech and Speech Enhancement in Generative AI
Mar 23, 2023
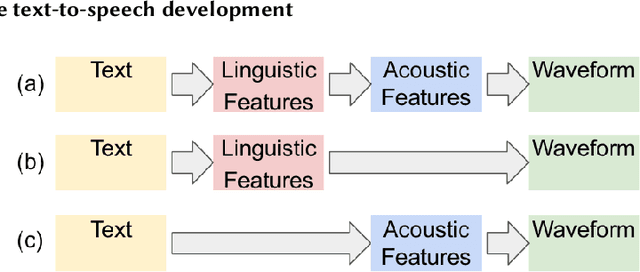
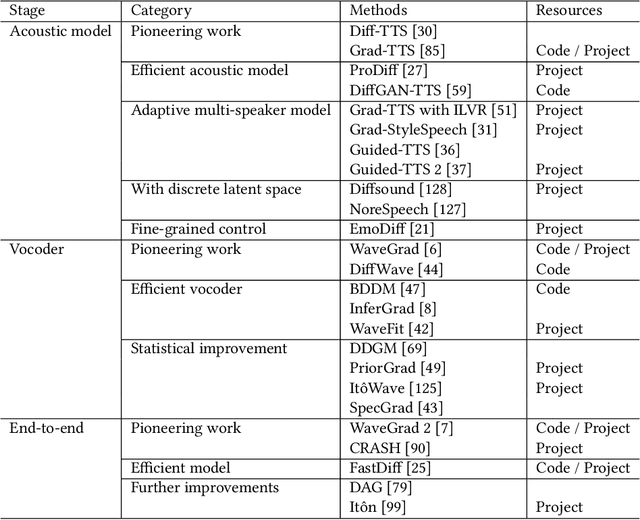
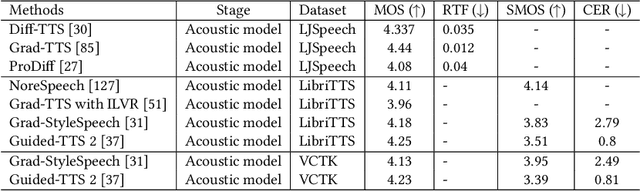

Generative AI has demonstrated impressive performance in various fields, among which speech synthesis is an interesting direction. With the diffusion model as the most popular generative model, numerous works have attempted two active tasks: text to speech and speech enhancement. This work conducts a survey on audio diffusion model, which is complementary to existing surveys that either lack the recent progress of diffusion-based speech synthesis or highlight an overall picture of applying diffusion model in multiple fields. Specifically, this work first briefly introduces the background of audio and diffusion model. As for the text-to-speech task, we divide the methods into three categories based on the stage where diffusion model is adopted: acoustic model, vocoder and end-to-end framework. Moreover, we categorize various speech enhancement tasks by either certain signals are removed or added into the input speech. Comparisons of experimental results and discussions are also covered in this survey.
TrustSER: On the Trustworthiness of Fine-tuning Pre-trained Speech Embeddings For Speech Emotion Recognition
May 18, 2023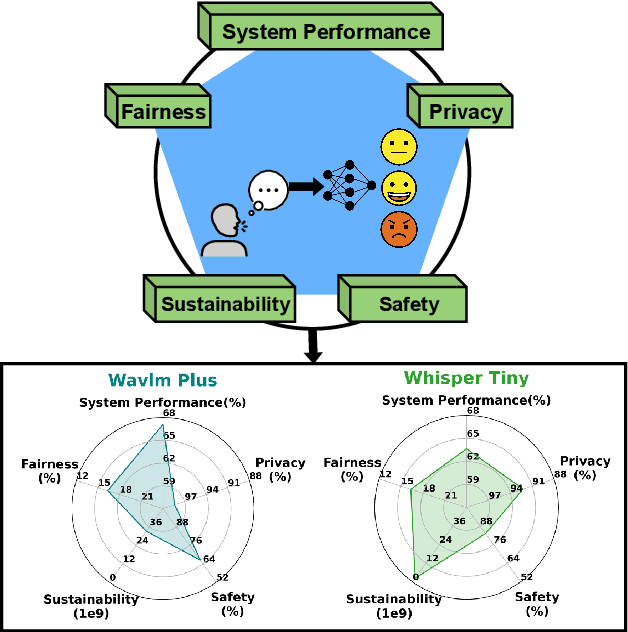


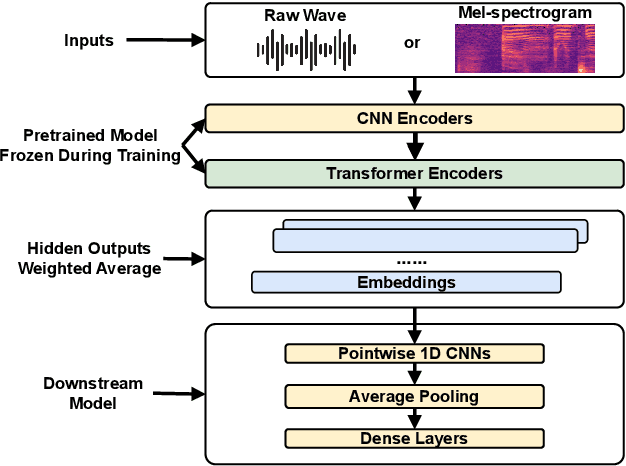
Recent studies have explored the use of pre-trained embeddings for speech emotion recognition (SER), achieving comparable performance to conventional methods that rely on low-level knowledge-inspired acoustic features. These embeddings are often generated from models trained on large-scale speech datasets using self-supervised or weakly-supervised learning objectives. Despite the significant advancements made in SER through the use of pre-trained embeddings, there is a limited understanding of the trustworthiness of these methods, including privacy breaches, unfair performance, vulnerability to adversarial attacks, and computational cost, all of which may hinder the real-world deployment of these systems. In response, we introduce TrustSER, a general framework designed to evaluate the trustworthiness of SER systems using deep learning methods, with a focus on privacy, safety, fairness, and sustainability, offering unique insights into future research in the field of SER. Our code is publicly available under: https://github.com/usc-sail/trust-ser.
Iteratively Improving Speech Recognition and Voice Conversion
May 24, 2023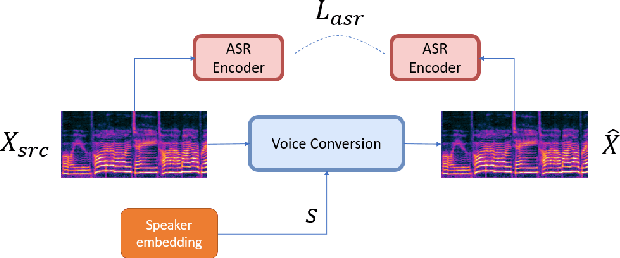
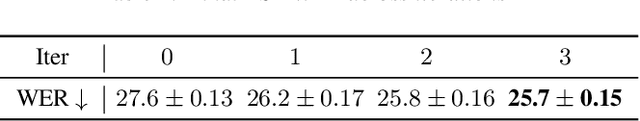
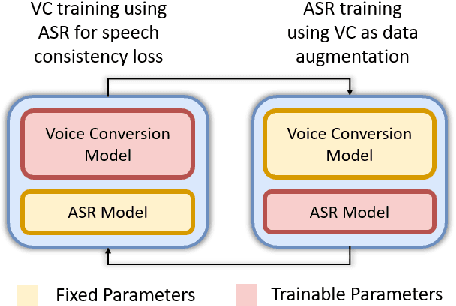
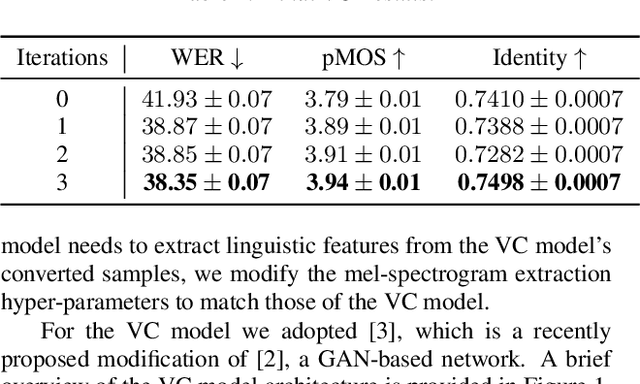
Many existing works on voice conversion (VC) tasks use automatic speech recognition (ASR) models for ensuring linguistic consistency between source and converted samples. However, for the low-data resource domains, training a high-quality ASR remains to be a challenging task. In this work, we propose a novel iterative way of improving both the ASR and VC models. We first train an ASR model which is used to ensure content preservation while training a VC model. In the next iteration, the VC model is used as a data augmentation method to further fine-tune the ASR model and generalize it to diverse speakers. By iteratively leveraging the improved ASR model to train VC model and vice-versa, we experimentally show improvement in both the models. Our proposed framework outperforms the ASR and one-shot VC baseline models on English singing and Hindi speech domains in subjective and objective evaluations in low-data resource settings.
Semantic VAD: Low-Latency Voice Activity Detection for Speech Interaction
May 21, 2023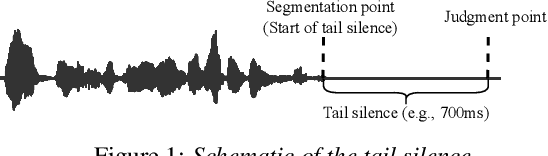
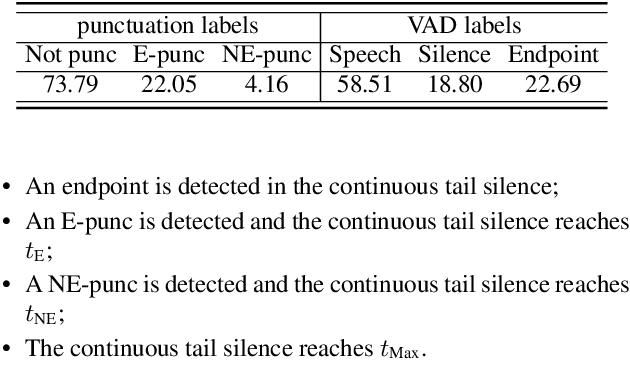
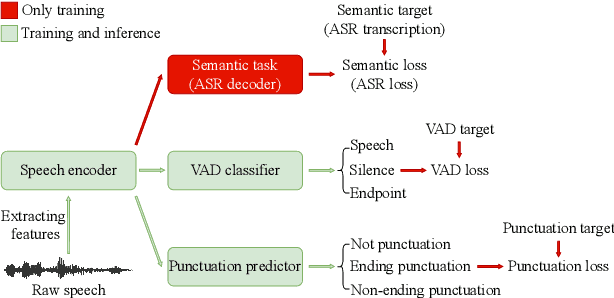
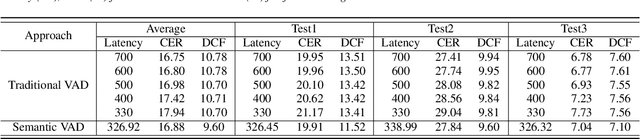
For speech interaction, voice activity detection (VAD) is often used as a front-end. However, traditional VAD algorithms usually need to wait for a continuous tail silence to reach a preset maximum duration before segmentation, resulting in a large latency that affects user experience. In this paper, we propose a novel semantic VAD for low-latency segmentation. Different from existing methods, a frame-level punctuation prediction task is added to the semantic VAD, and the artificial endpoint is included in the classification category in addition to the often-used speech presence and absence. To enhance the semantic information of the model, we also incorporate an automatic speech recognition (ASR) related semantic loss. Evaluations on an internal dataset show that the proposed method can reduce the average latency by 53.3% without significant deterioration of character error rate in the back-end ASR compared to the traditional VAD approach.
Non-uniform Speaker Disentanglement For Depression Detection From Raw Speech Signals
Jun 06, 2023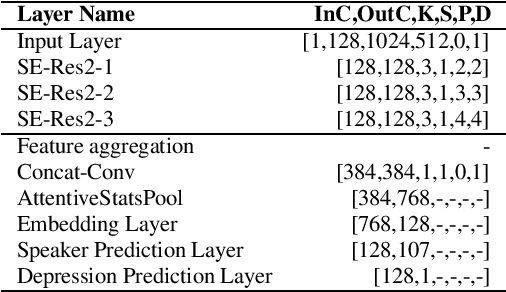
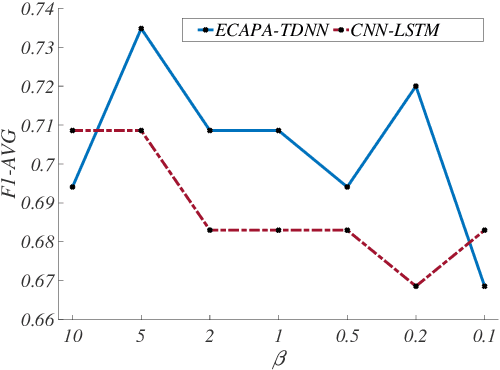
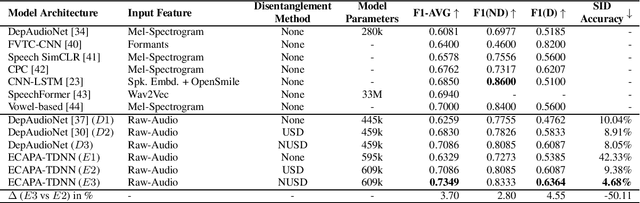
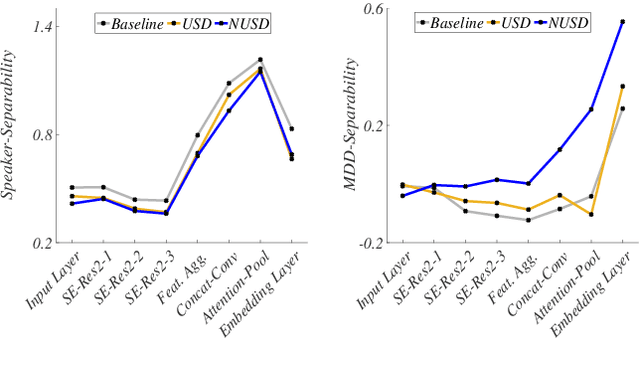
While speech-based depression detection methods that use speaker-identity features, such as speaker embeddings, are popular, they often compromise patient privacy. To address this issue, we propose a speaker disentanglement method that utilizes a non-uniform mechanism of adversarial SID loss maximization. This is achieved by varying the adversarial weight between different layers of a model during training. We find that a greater adversarial weight for the initial layers leads to performance improvement. Our approach using the ECAPA-TDNN model achieves an F1-score of 0.7349 (a 3.7% improvement over audio-only SOTA) on the DAIC-WoZ dataset, while simultaneously reducing the speaker-identification accuracy by 50%. Our findings suggest that identifying depression through speech signals can be accomplished without placing undue reliance on a speaker's identity, paving the way for privacy-preserving approaches of depression detection.
ViLaS: Integrating Vision and Language into Automatic Speech Recognition
May 31, 2023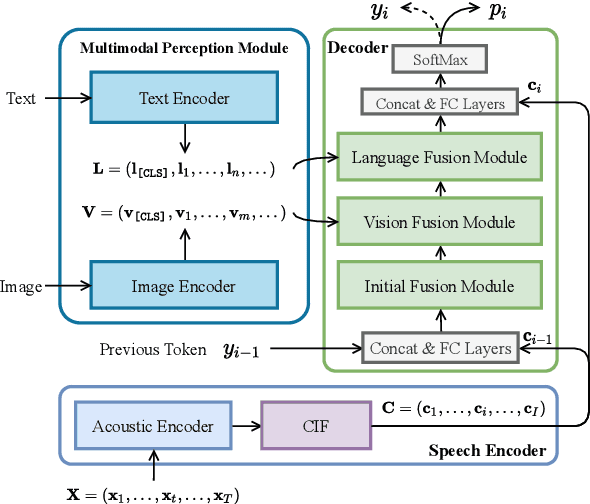
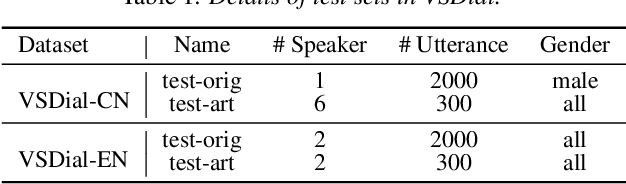
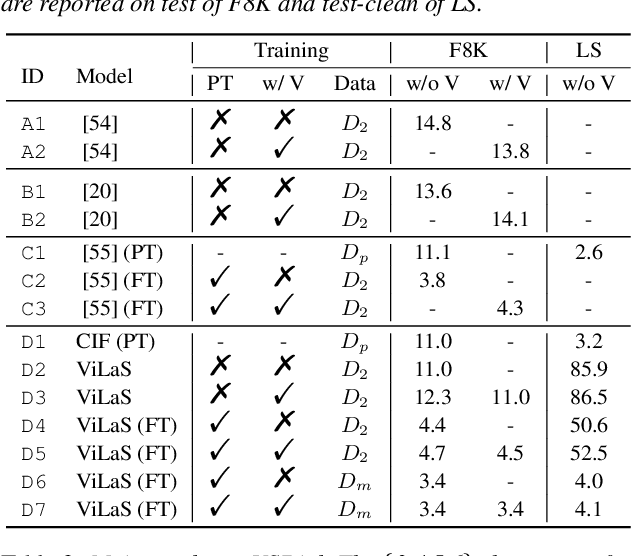
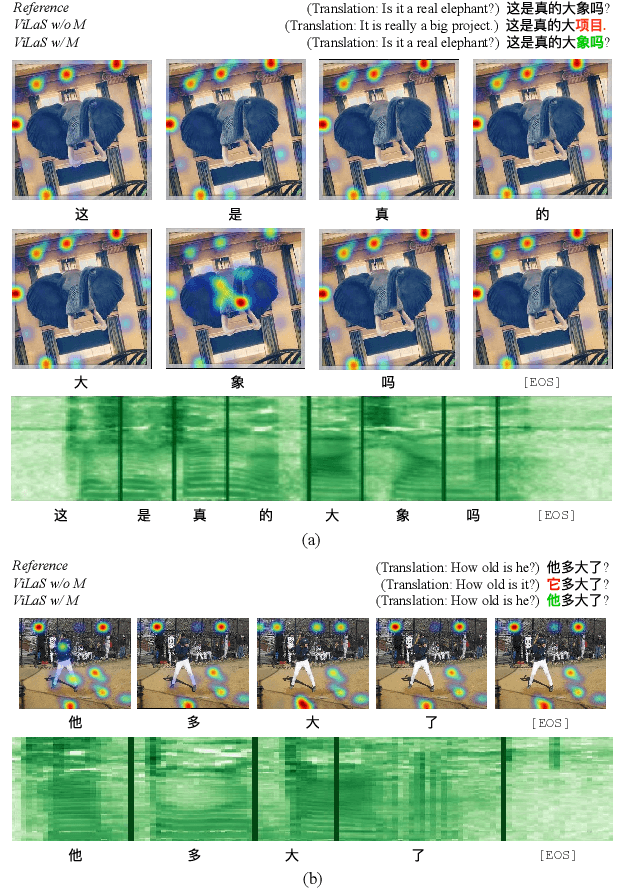
Employing additional multimodal information to improve automatic speech recognition (ASR) performance has been proven effective in previous works. However, many of these works focus only on the utilization of visual cues from human lip motion. In fact, context-dependent visual and linguistic cues can also be used to improve ASR performance in many scenarios. In this paper, we first propose a multimodal ASR model (ViLaS) that can simultaneously or separately integrate visual and linguistic cues to help recognize the input speech, and introduce a training strategy that can improve performance in modal-incomplete test scenarios. Then, we create a multimodal ASR dataset (VSDial) with visual and linguistic cues to explore the effects of integrating vision and language. Finally, we report empirical results on the public Flickr8K and self-constructed VSDial datasets, investigate cross-modal fusion schemes, and analyze fine-grained cross-modal alignment on VSDial.
Active Learning for Classifying 2D Grid-Based Level Completability
Sep 08, 2023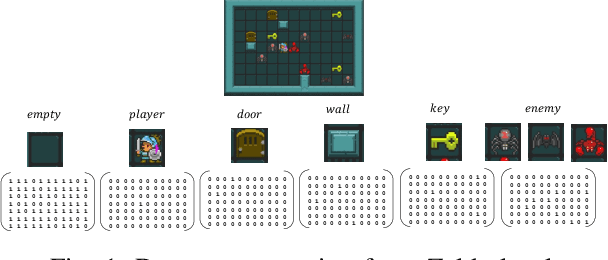
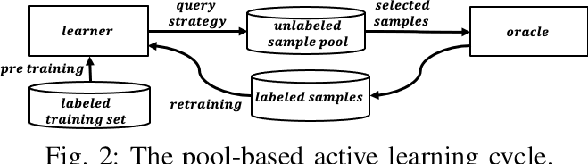
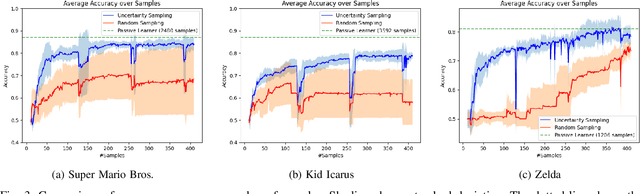
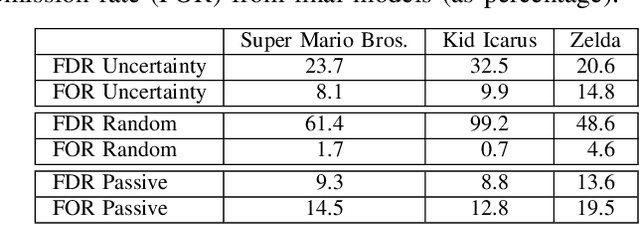
Determining the completability of levels generated by procedural generators such as machine learning models can be challenging, as it can involve the use of solver agents that often require a significant amount of time to analyze and solve levels. Active learning is not yet widely adopted in game evaluations, although it has been used successfully in natural language processing, image and speech recognition, and computer vision, where the availability of labeled data is limited or expensive. In this paper, we propose the use of active learning for learning level completability classification. Through an active learning approach, we train deep-learning models to classify the completability of generated levels for Super Mario Bros., Kid Icarus, and a Zelda-like game. We compare active learning for querying levels to label with completability against random queries. Our results show using an active learning approach to label levels results in better classifier performance with the same amount of labeled data.
* 4 pages, 3 figures
Unified Modeling of Multi-Talker Overlapped Speech Recognition and Diarization with a Sidecar Separator
May 25, 2023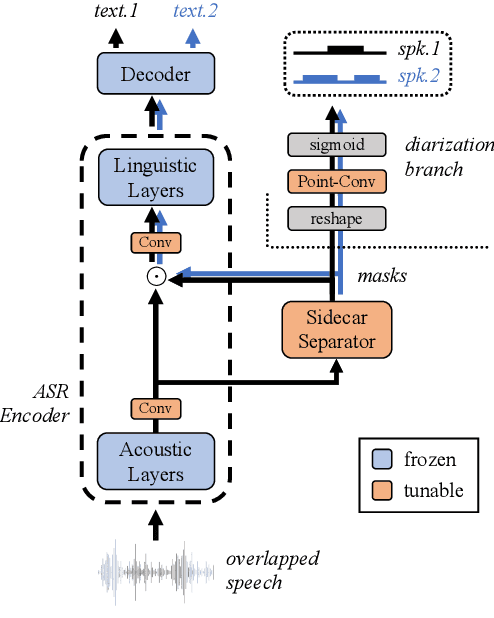
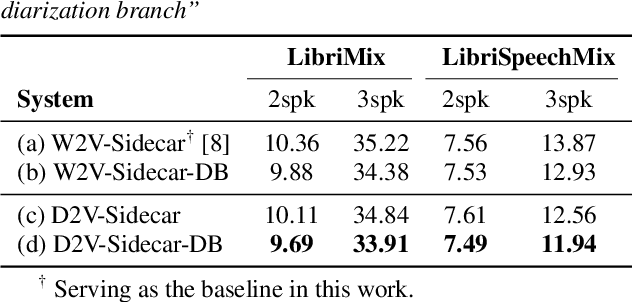
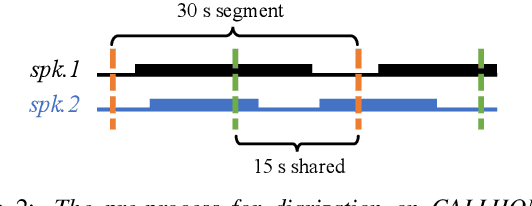
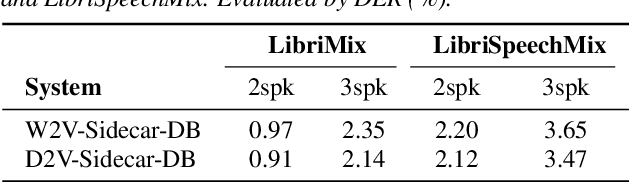
Multi-talker overlapped speech poses a significant challenge for speech recognition and diarization. Recent research indicated that these two tasks are inter-dependent and complementary, motivating us to explore a unified modeling method to address them in the context of overlapped speech. A recent study proposed a cost-effective method to convert a single-talker automatic speech recognition (ASR) system into a multi-talker one, by inserting a Sidecar separator into the frozen well-trained ASR model. Extending on this, we incorporate a diarization branch into the Sidecar, allowing for unified modeling of both ASR and diarization with a negligible overhead of only 768 parameters. The proposed method yields better ASR results compared to the baseline on LibriMix and LibriSpeechMix datasets. Moreover, without sophisticated customization on the diarization task, our method achieves acceptable diarization results on the two-speaker subset of CALLHOME with only a few adaptation steps.
Bayes Risk Transducer: Transducer with Controllable Alignment Prediction
Aug 19, 2023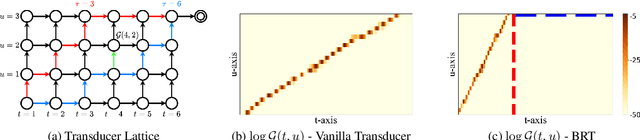
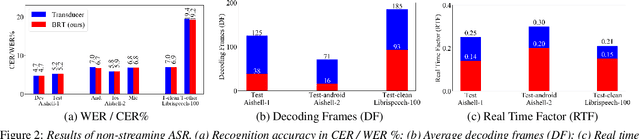
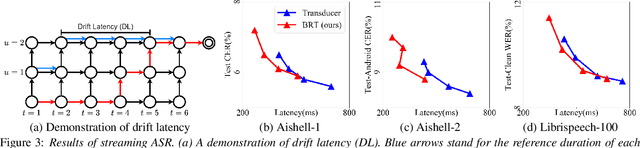
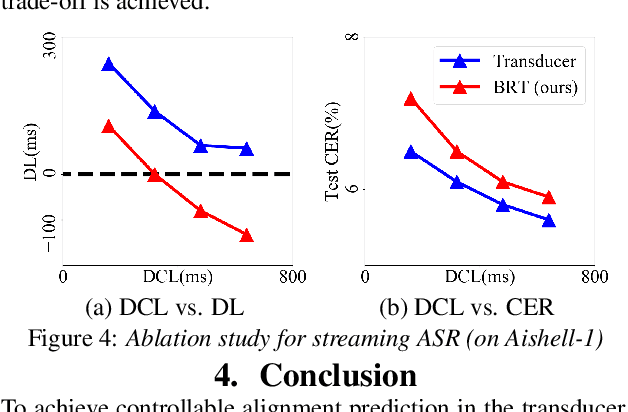
Automatic speech recognition (ASR) based on transducers is widely used. In training, a transducer maximizes the summed posteriors of all paths. The path with the highest posterior is commonly defined as the predicted alignment between the speech and the transcription. While the vanilla transducer does not have a prior preference for any of the valid paths, this work intends to enforce the preferred paths and achieve controllable alignment prediction. Specifically, this work proposes Bayes Risk Transducer (BRT), which uses a Bayes risk function to set lower risk values to the preferred paths so that the predicted alignment is more likely to satisfy specific desired properties. We further demonstrate that these predicted alignments with intentionally designed properties can provide practical advantages over the vanilla transducer. Experimentally, the proposed BRT saves inference cost by up to 46% for non-streaming ASR and reduces overall system latency by 41% for streaming ASR.
LibriSQA: Advancing Free-form and Open-ended Spoken Question Answering with a Novel Dataset and Framework
Aug 22, 2023While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.