 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Real-World Assessment of Audio Watermarking Algorithms: Will They Survive Neural Codecs?
May 26, 2025We present a framework to foster the evaluation of deep learning-based audio watermarking algorithms, establishing a standardized benchmark and allowing systematic comparisons. To simulate real-world usage, we introduce a comprehensive audio attack pipeline, featuring various distortions such as compression, background noise, and reverberation, and propose a diverse test dataset, including speech, environmental sounds, and music recordings. By assessing the performance of four existing watermarking algorithms on our framework, two main insights stand out: (i) neural compression techniques pose the most significant challenge, even when algorithms are trained with such compressions; and (ii) training with audio attacks generally improves robustness, although it is insufficient in some cases. Furthermore, we find that specific distortions, such as polarity inversion, time stretching, or reverb, seriously affect certain algorithms. Our contributions strengthen the robustness and perceptual assessment of audio watermarking algorithms across a wide range of applications, while ensuring a fair and consistent evaluation approach. The evaluation framework, including the attack pipeline, is accessible at github.com/SonyResearch/wm_robustness_eval.
SilentCipher: Deep Audio Watermarking
Jun 06, 2024



In the realm of audio watermarking, it is challenging to simultaneously encode imperceptible messages while enhancing the message capacity and robustness. Although recent advancements in deep learning-based methods bolster the message capacity and robustness over traditional methods, the encoded messages introduce audible artefacts that restricts their usage in professional settings. In this study, we introduce three key innovations. Firstly, our work is the first deep learning-based model to integrate psychoacoustic model based thresholding to achieve imperceptible watermarks. Secondly, we introduce psuedo-differentiable compression layers, enhancing the robustness of our watermarking algorithm. Lastly, we introduce a method to eliminate the need for perceptual losses, enabling us to achieve SOTA in both robustness as well as imperceptible watermarking. Our contributions lead us to SilentCipher, a model enabling users to encode messages within audio signals sampled at 44.1kHz.
Iteratively Improving Speech Recognition and Voice Conversion
May 24, 2023



Many existing works on voice conversion (VC) tasks use automatic speech recognition (ASR) models for ensuring linguistic consistency between source and converted samples. However, for the low-data resource domains, training a high-quality ASR remains to be a challenging task. In this work, we propose a novel iterative way of improving both the ASR and VC models. We first train an ASR model which is used to ensure content preservation while training a VC model. In the next iteration, the VC model is used as a data augmentation method to further fine-tune the ASR model and generalize it to diverse speakers. By iteratively leveraging the improved ASR model to train VC model and vice-versa, we experimentally show improvement in both the models. Our proposed framework outperforms the ASR and one-shot VC baseline models on English singing and Hindi speech domains in subjective and objective evaluations in low-data resource settings.
Nonparallel Emotional Voice Conversion For Unseen Speaker-Emotion Pairs Using Dual Domain Adversarial Network & Virtual Domain Pairing
Feb 21, 2023

Primary goal of an emotional voice conversion (EVC) system is to convert the emotion of a given speech signal from one style to another style without modifying the linguistic content of the signal. Most of the state-of-the-art approaches convert emotions for seen speaker-emotion combinations only. In this paper, we tackle the problem of converting the emotion of speakers whose only neutral data are present during the time of training and testing (i.e., unseen speaker-emotion combinations). To this end, we extend a recently proposed StartGANv2-VC architecture by utilizing dual encoders for learning the speaker and emotion style embeddings separately along with dual domain source classifiers. For achieving the conversion to unseen speaker-emotion combinations, we propose a Virtual Domain Pairing (VDP) training strategy, which virtually incorporates the speaker-emotion pairs that are not present in the real data without compromising the min-max game of a discriminator and generator in adversarial training. We evaluate the proposed method using a Hindi emotional database.
Source Mixing and Separation Robust Audio Steganography
Oct 11, 2021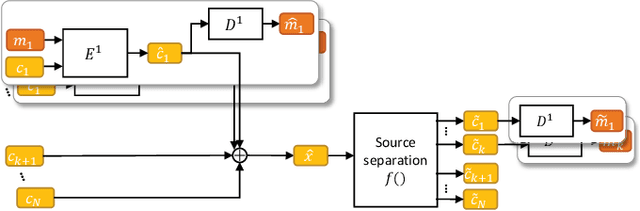

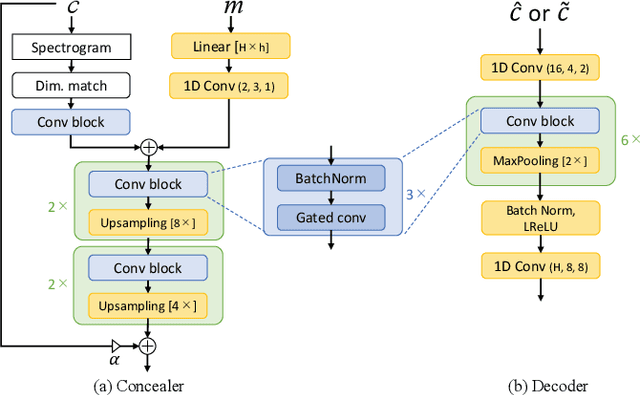
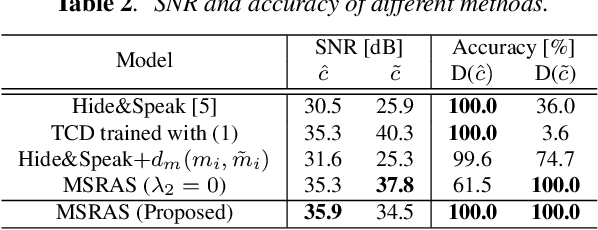
Audio steganography aims at concealing secret information in carrier audio with imperceptible modification on the carrier. Although previous works addressed the robustness of concealed message recovery against distortions introduced during transmission, they do not address the robustness against aggressive editing such as mixing of other audio sources and source separation. In this work, we propose for the first time a steganography method that can embed information into individual sound sources in a mixture such as instrumental tracks in music. To this end, we propose a time-domain model and curriculum learning essential to learn to decode the concealed message from the separated sources. Experimental results show that the proposed method successfully conceals the information in an imperceptible perturbation and that the information can be correctly recovered even after mixing of other sources and separation by a source separation algorithm. Furthermore, we show that the proposed method can be applied to multiple sources simultaneously without interfering with the decoder for other sources even after the sources are mixed and separated.
Hierarchical disentangled representation learning for singing voice conversion
Jan 18, 2021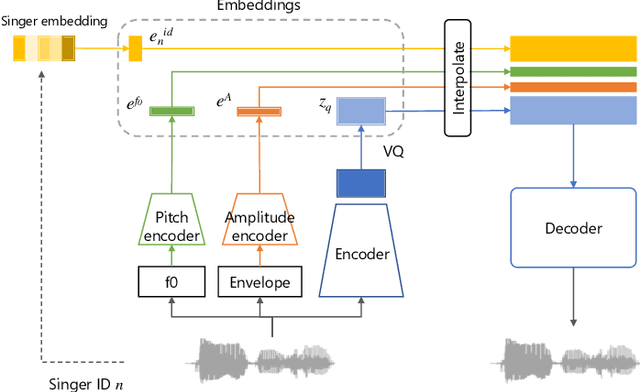
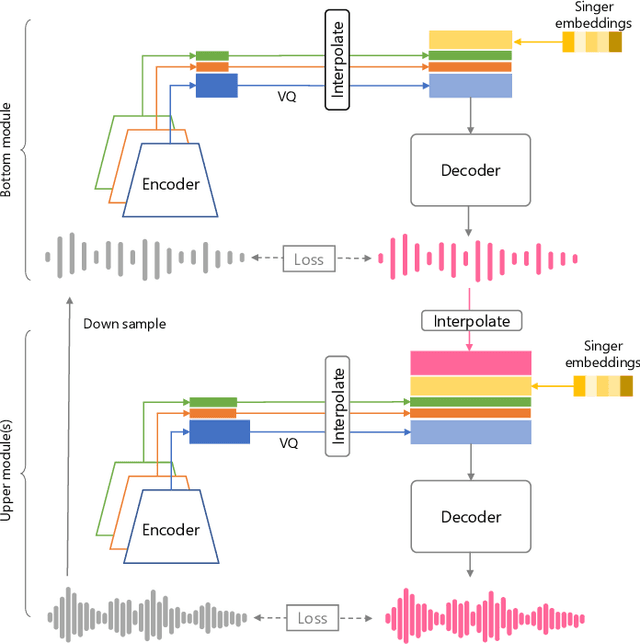
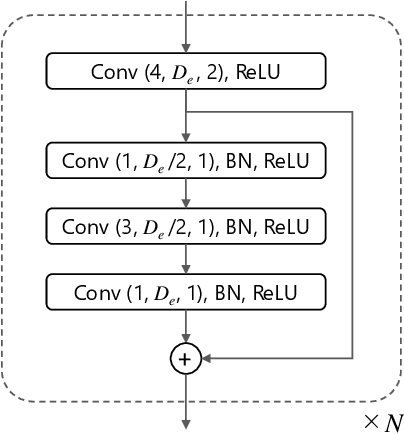
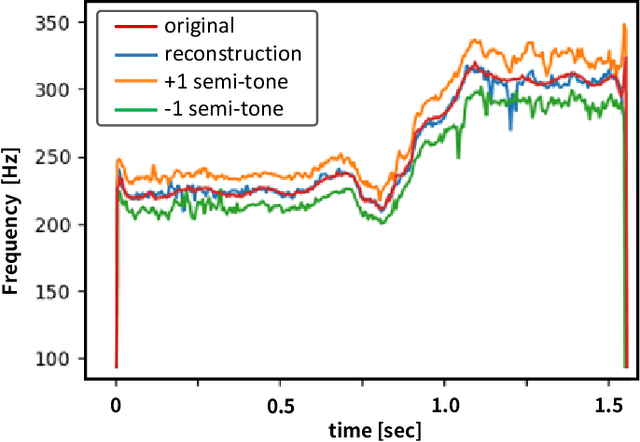
Conventional singing voice conversion (SVC) methods often suffer from operating in high-resolution audio owing to a high dimensionality of data. In this paper, we propose a hierarchical representation learning that enables the learning of disentangled representations with multiple resolutions independently. With the learned disentangled representations, the proposed method progressively performs SVC from low to high resolutions. Experimental results show that the proposed method outperforms baselines that operate with a single resolution in terms of mean opinion score (MOS), similarity score, and pitch accuracy.
NENET: An Edge Learnable Network for Link Prediction in Scene Text
May 25, 2020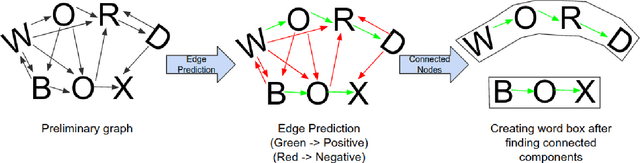
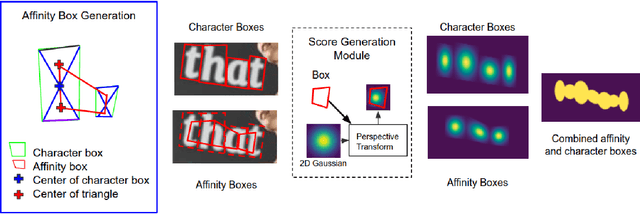

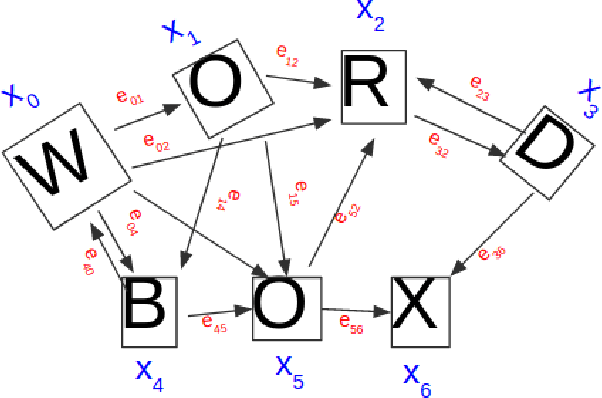
Text detection in scenes based on deep neural networks have shown promising results. Instead of using word bounding box regression, recent state-of-the-art methods have started focusing on character bounding box and pixel-level prediction. This necessitates the need to link adjacent characters, which we propose in this paper using a novel Graph Neural Network (GNN) architecture that allows us to learn both node and edge features as opposed to only the node features under the typical GNN. The main advantage of using GNN for link prediction lies in its ability to connect characters which are spatially separated and have an arbitrary orientation. We show our concept on the well known SynthText dataset, achieving top results as compared to state-of-the-art methods.
Improving Voice Separation by Incorporating End-to-end Speech Recognition
Nov 29, 2019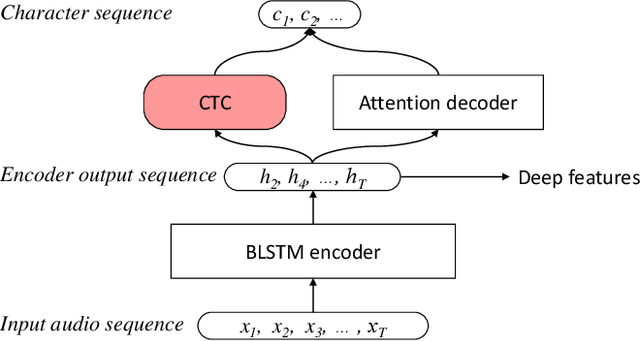
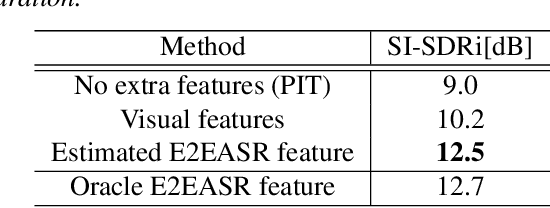
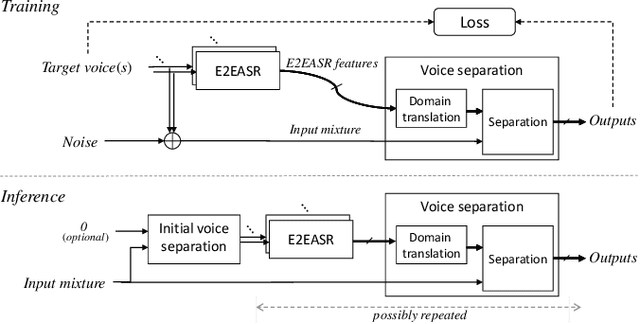

Despite recent advances in voice separation methods, many challenges remain in realistic scenarios such as noisy recording and the limits of available data. In this work, we propose to explicitly incorporate the phonetic and linguistic nature of speech by taking a transfer learning approach using an end-to-end automatic speech recognition (E2EASR) system. The voice separation is conditioned on deep features extracted from E2EASR to cover the long-term dependence of phonetic aspects. Experimental results on speech separation and enhancement task on the AVSpeech dataset show that the proposed method significantly improves the signal-to-distortion ratio over the baseline model and even outperforms an audio visual model, that utilizes visual information of lip movements.