 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilentCipher: Deep Audio Watermarking
Jun 06, 2024



In the realm of audio watermarking, it is challenging to simultaneously encode imperceptible messages while enhancing the message capacity and robustness. Although recent advancements in deep learning-based methods bolster the message capacity and robustness over traditional methods, the encoded messages introduce audible artefacts that restricts their usage in professional settings. In this study, we introduce three key innovations. Firstly, our work is the first deep learning-based model to integrate psychoacoustic model based thresholding to achieve imperceptible watermarks. Secondly, we introduce psuedo-differentiable compression layers, enhancing the robustness of our watermarking algorithm. Lastly, we introduce a method to eliminate the need for perceptual losses, enabling us to achieve SOTA in both robustness as well as imperceptible watermarking. Our contributions lead us to SilentCipher, a model enabling users to encode messages within audio signals sampled at 44.1kHz.
STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events
Jun 15, 2023



While direction of arrival (DOA) of sound events is generally estimated from multichannel audio data recorded in a microphone array, sound events usually derive from visually perceptible source objects, e.g., sounds of footsteps come from the feet of a walker. This paper proposes an audio-visual sound event localization and detection (SELD) task, which uses multichannel audio and video information to estimate the temporal activation and DOA of target sound events. Audio-visual SELD systems can detect and localize sound events using signals from a microphone array and audio-visual correspondence. We also introduce an audio-visual dataset, Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23), which consists of multichannel audio data recorded with a microphone array, video data, and spatiotemporal annotation of sound events. Sound scenes in STARSS23 are recorded with instructions, which guide recording participants to ensure adequate activity and occurrences of sound events. STARSS23 also serves human-annotated temporal activation labels and human-confirmed DOA labels, which are based on tracking results of a motion capture system. Our benchmark results show that the audio-visual SELD system achieves lower localization error than the audio-only system. The data is available at https://zenodo.org/record/7880637.
Iteratively Improving Speech Recognition and Voice Conversion
May 24, 2023



Many existing works on voice conversion (VC) tasks use automatic speech recognition (ASR) models for ensuring linguistic consistency between source and converted samples. However, for the low-data resource domains, training a high-quality ASR remains to be a challenging task. In this work, we propose a novel iterative way of improving both the ASR and VC models. We first train an ASR model which is used to ensure content preservation while training a VC model. In the next iteration, the VC model is used as a data augmentation method to further fine-tune the ASR model and generalize it to diverse speakers. By iteratively leveraging the improved ASR model to train VC model and vice-versa, we experimentally show improvement in both the models. Our proposed framework outperforms the ASR and one-shot VC baseline models on English singing and Hindi speech domains in subjective and objective evaluations in low-data resource settings.
The Whole Is Greater than the Sum of Its Parts: Improving DNN-based Music Source Separation
May 13, 2023This paper presents the crossing scheme (X-scheme) for improving the performance of deep neural network (DNN)-based music source separation (MSS) without increasing calculation cost. It consists of three components: (i) multi-domain loss (MDL), (ii) bridging operation, which couples the individual instrument networks, and (iii) combination loss (CL). MDL enables the taking advantage of the frequency- and time-domain representations of audio signals. We modify the target network, i.e., the network architecture of the original DNN-based MSS, by adding bridging paths for each output instrument to share their information. MDL is then applied to the combinations of the output sources as well as each independent source, hence we called it CL. MDL and CL can easily be applied to many DNN-based separation methods as they are merely loss functions that are only used during training and do not affect the inference step. Bridging operation does not increase the number of learnable parameters in the network. Experimental results showed that the validity of Open-Unmix (UMX) and densely connected dilated DenseNet (D3Net) extended with our X-scheme, respectively called X-UMX and X-D3Net, by comparing them with their original versions. We also verified the effectiveness of X-scheme in a large-scale data regime, showing its generality with respect to data size. X-UMX Large (X-UMXL), which was trained on large-scale internal data and used in our experiments, is newly available at https://github.com/asteroid-team/asteroid/tree/master/egs/musdb18/X-UMX.
Cross-modal Face- and Voice-style Transfer
Mar 01, 2023



Image-to-image translation and voice conversion enable the generation of a new facial image and voice while maintaining some of the semantics such as a pose in an image and linguistic content in audio, respectively. They can aid in the content-creation process in many applications. However, as they are limited to the conversion within each modality, matching the impression of the generated face and voice remains an open question. We propose a cross-modal style transfer framework called XFaVoT that jointly learns four tasks: image translation and voice conversion tasks with audio or image guidance, which enables the generation of ``face that matches given voice" and ``voice that matches given face", and intra-modality translation tasks with a single framework. Experimental results on multiple datasets show that XFaVoT achieves cross-modal style translation of image and voice, outperforming baselines in terms of quality, diversity, and face-voice correspondence.
Nonparallel Emotional Voice Conversion For Unseen Speaker-Emotion Pairs Using Dual Domain Adversarial Network & Virtual Domain Pairing
Feb 21, 2023

Primary goal of an emotional voice conversion (EVC) system is to convert the emotion of a given speech signal from one style to another style without modifying the linguistic content of the signal. Most of the state-of-the-art approaches convert emotions for seen speaker-emotion combinations only. In this paper, we tackle the problem of converting the emotion of speakers whose only neutral data are present during the time of training and testing (i.e., unseen speaker-emotion combinations). To this end, we extend a recently proposed StartGANv2-VC architecture by utilizing dual encoders for learning the speaker and emotion style embeddings separately along with dual domain source classifiers. For achieving the conversion to unseen speaker-emotion combinations, we propose a Virtual Domain Pairing (VDP) training strategy, which virtually incorporates the speaker-emotion pairs that are not present in the real data without compromising the min-max game of a discriminator and generator in adversarial training. We evaluate the proposed method using a Hindi emotional database.
CLIPSep: Learning Text-queried Sound Separation with Noisy Unlabeled Videos
Dec 14, 2022



Recent years have seen progress beyond domain-specific sound separation for speech or music towards universal sound separation for arbitrary sounds. Prior work on universal sound separation has investigated separating a target sound out of an audio mixture given a text query. Such text-queried sound separation systems provide a natural and scalable interface for specifying arbitrary target sounds. However, supervised text-queried sound separation systems require costly labeled audio-text pairs for training. Moreover, the audio provided in existing datasets is often recorded in a controlled environment, causing a considerable generalization gap to noisy audio in the wild. In this work, we aim to approach text-queried universal sound separation by using only unlabeled data. We propose to leverage the visual modality as a bridge to learn the desired audio-textual correspondence. The proposed CLIPSep model first encodes the input query into a query vector using the contrastive language-image pretraining (CLIP) model, and the query vector is then used to condition an audio separation model to separate out the target sound. While the model is trained on image-audio pairs extracted from unlabeled videos, at test time we can instead query the model with text inputs in a zero-shot setting, thanks to the joint language-image embedding learned by the CLIP model. Further, videos in the wild often contain off-screen sounds and background noise that may hinder the model from learning the desired audio-textual correspondence. To address this problem, we further propose an approach called noise invariant training for training a query-based sound separation model on noisy data. Experimental results show that the proposed models successfully learn text-queried universal sound separation using only noisy unlabeled videos, even achieving competitive performance against a supervised model in some settings.
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
Oct 18, 2022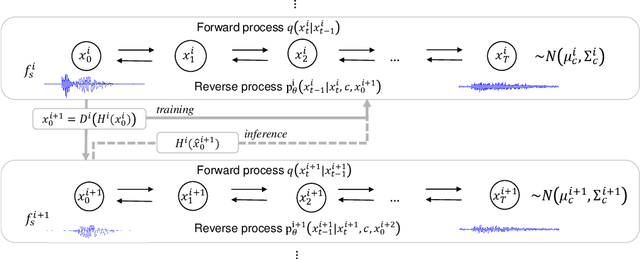
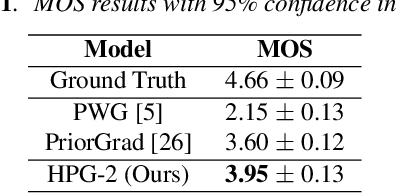
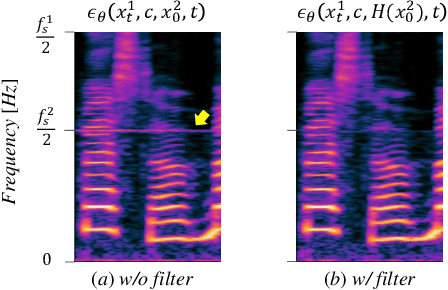
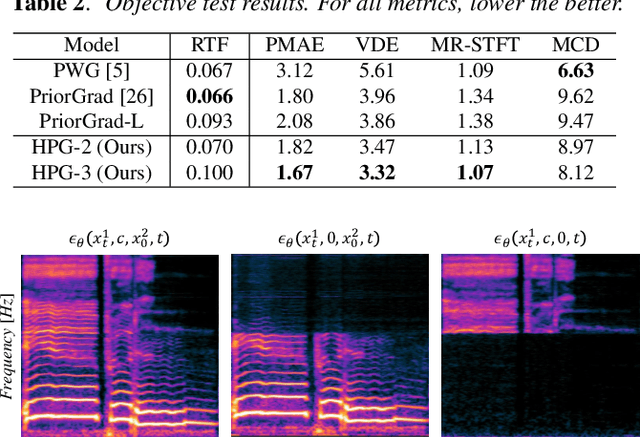
Recent progress in deep generative models has improved the quality of neural vocoders in speech domain. However, generating a high-quality singing voice remains challenging due to a wider variety of musical expressions in pitch, loudness, and pronunciations. In this work, we propose a hierarchical diffusion model for singing voice neural vocoders. The proposed method consists of multiple diffusion models operating in different sampling rates; the model at the lowest sampling rate focuses on generating accurate low-frequency components such as pitch, and other models progressively generate the waveform at higher sampling rates on the basis of the data at the lower sampling rate and acoustic features. Experimental results show that the proposed method produces high-quality singing voices for multiple singers, outperforming state-of-the-art neural vocoders with a similar range of computational costs.
DiffRoll: Diffusion-based Generative Music Transcription with Unsupervised Pretraining Capability
Oct 11, 2022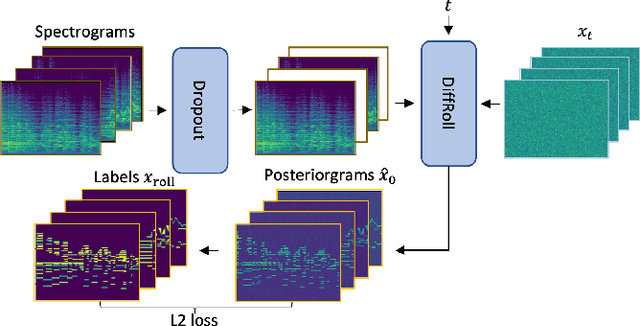
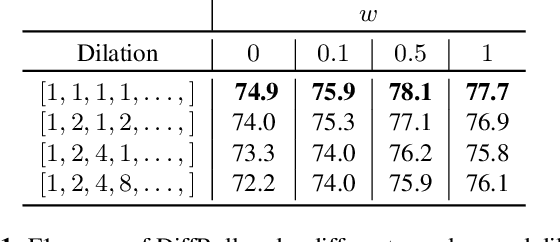
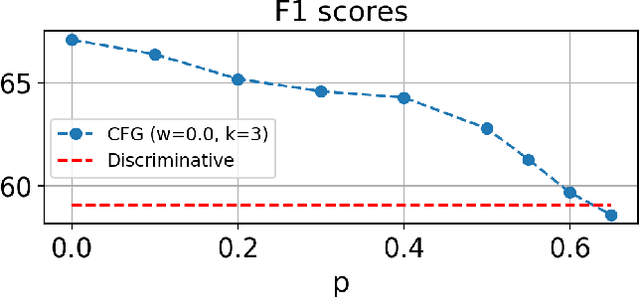

In this paper we propose a novel generative approach, DiffRoll, to tackle automatic music transcription (AMT). Instead of treating AMT as a discriminative task in which the model is trained to convert spectrograms into piano rolls, we think of it as a conditional generative task where we train our model to generate realistic looking piano rolls from pure Gaussian noise conditioned on spectrograms. This new AMT formulation enables DiffRoll to transcribe, generate and even inpaint music. Due to the classifier-free nature, DiffRoll is also able to be trained on unpaired datasets where only piano rolls are available. Our experiments show that DiffRoll outperforms its discriminative counterpart by 17.9 percentage points (ppt.) and our ablation studies also indicate that it outperforms similar existing methods by 3.70 ppt.
Leveraging Symmetrical Convolutional Transformer Networks for Speech to Singing Voice Style Transfer
Aug 26, 2022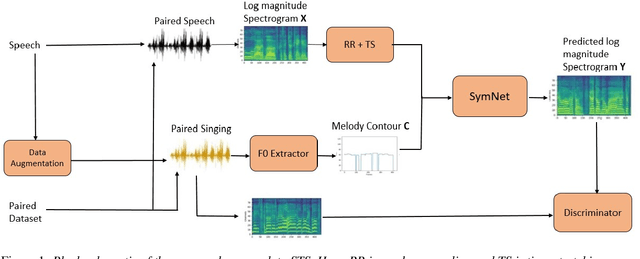

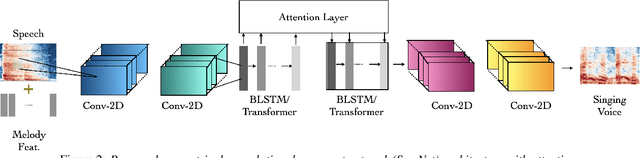
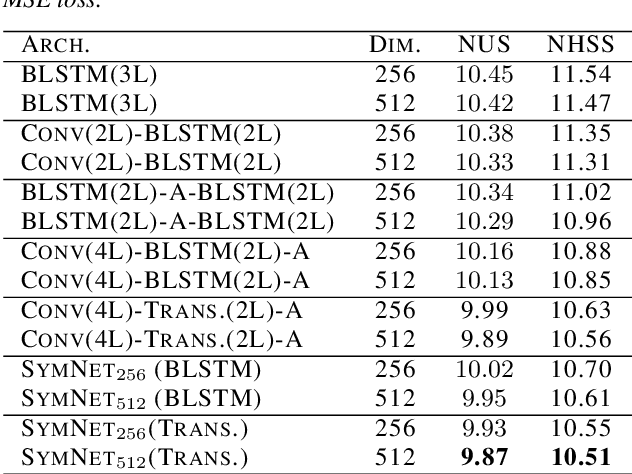
In this paper, we propose a model to perform style transfer of speech to singing voice. Contrary to the previous signal processing-based methods, which require high-quality singing templates or phoneme synchronization, we explore a data-driven approach for the problem of converting natural speech to singing voice. We develop a novel neural network architecture, called SymNet, which models the alignment of the input speech with the target melody while preserving the speaker identity and naturalness. The proposed SymNet model is comprised of symmetrical stack of three types of layers - convolutional, transformer, and self-attention layers. The paper also explores novel data augmentation and generative loss annealing methods to facilitate the model training. Experiments are performed on the NUS and NHSS datasets which consist of parallel data of speech and singing voice. In these experiments, we show that the proposed SymNet model improves the objective reconstruction quality significantly over the previously published methods and baseline architectures. Further, a subjective listening test confirms the improved quality of the audio obtained using the proposed approach (absolute improvement of 0.37 in mean opinion score measure over the baseline system).