 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Replay to Remember: Continual Layer-Specific Fine-tuning for German Speech Recognition
Jul 14, 2023
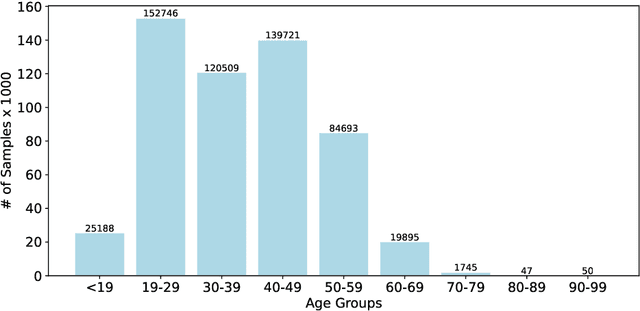
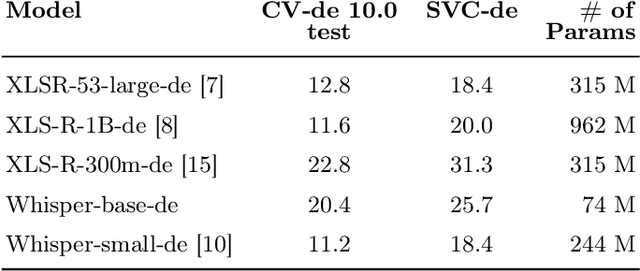

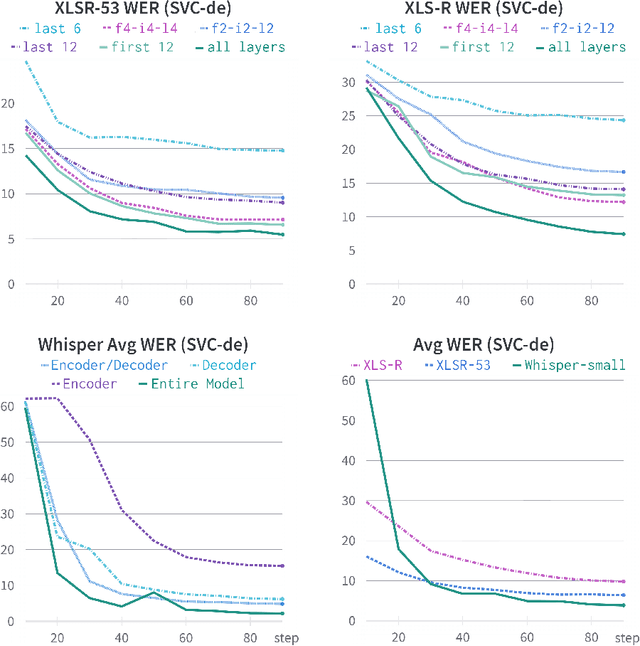
While Automatic Speech Recognition (ASR) models have shown significant advances with the introduction of unsupervised or self-supervised training techniques, these improvements are still only limited to a subsection of languages and speakers. Transfer learning enables the adaptation of large-scale multilingual models to not only low-resource languages but also to more specific speaker groups. However, fine-tuning on data from new domains is usually accompanied by a decrease in performance on the original domain. Therefore, in our experiments, we examine how well the performance of large-scale ASR models can be approximated for smaller domains, with our own dataset of German Senior Voice Commands (SVC-de), and how much of the general speech recognition performance can be preserved by selectively freezing parts of the model during training. To further increase the robustness of the ASR model to vocabulary and speakers outside of the fine-tuned domain, we apply Experience Replay for continual learning. By adding only a fraction of data from the original domain, we are able to reach Word-Error-Rates (WERs) below 5\% on the new domain, while stabilizing performance for general speech recognition at acceptable WERs.
Gesper: A Restoration-Enhancement Framework for General Speech Reconstruction
Jun 14, 2023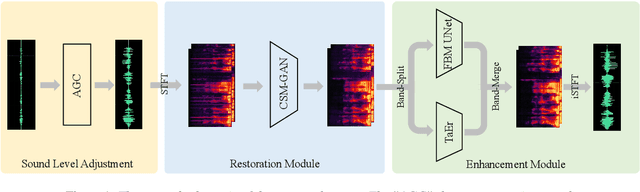
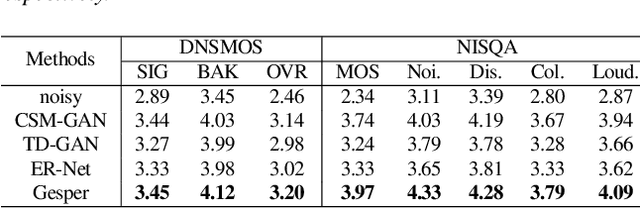
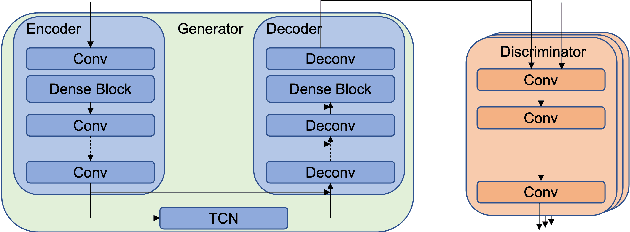
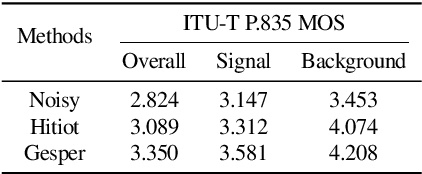
This paper describes a real-time General Speech Reconstruction (Gesper) system submitted to the ICASSP 2023 Speech Signal Improvement (SSI) Challenge. This novel proposed system is a two-stage architecture, in which the speech restoration is performed, and then cascaded by speech enhancement. We propose a complex spectral mapping-based generative adversarial network (CSM-GAN) as the speech restoration module for the first time. For noise suppression and dereverberation, the enhancement module is performed with fullband-wideband parallel processing. On the blind test set of ICASSP 2023 SSI Challenge, the proposed Gesper system, which satisfies the real-time condition, achieves 3.27 P.804 overall mean opinion score (MOS) and 3.35 P.835 overall MOS, ranked 1st in both track 1 and track 2.
ComSL: A Composite Speech-Language Model for End-to-End Speech-to-Text Translation
May 24, 2023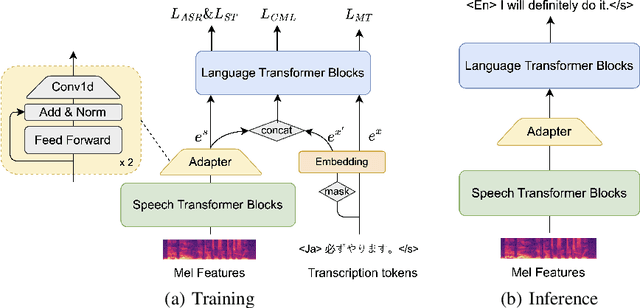
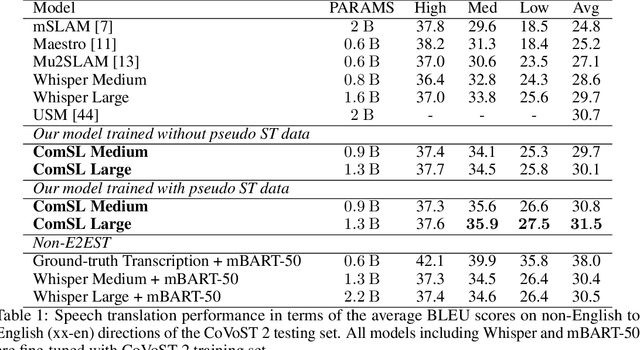
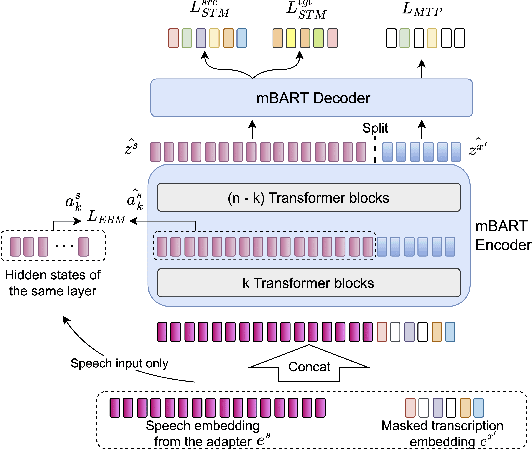
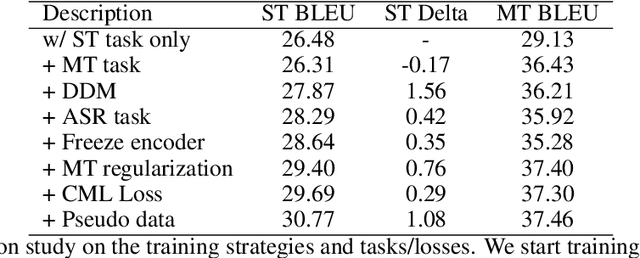
Joint speech-language training is challenging due to the large demand for training data and GPU consumption, as well as the modality gap between speech and language. We present ComSL, a speech-language model built atop a composite architecture of public pretrained speech-only and language-only models and optimized data-efficiently for spoken language tasks. Particularly, we propose to incorporate cross-modality learning into transfer learning and conduct them simultaneously for downstream tasks in a multi-task learning manner. Our approach has demonstrated effectiveness in end-to-end speech-to-text translation tasks, achieving a new state-of-the-art average BLEU score of 31.5 on the multilingual speech to English text translation task for 21 languages, as measured on the public CoVoST2 evaluation set.
SA-Paraformer: Non-autoregressive End-to-End Speaker-Attributed ASR
Oct 07, 2023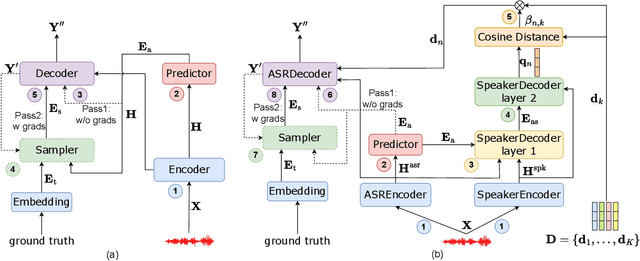
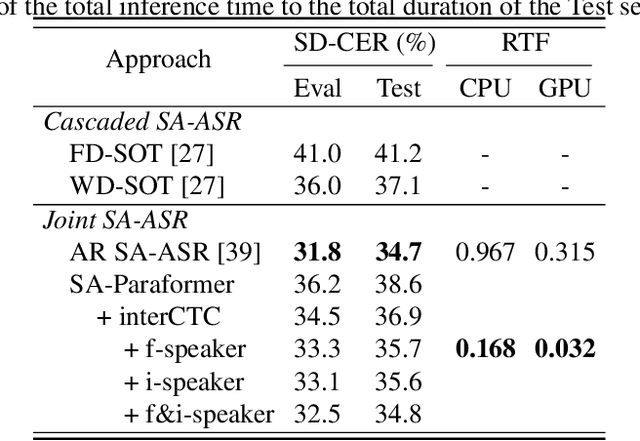
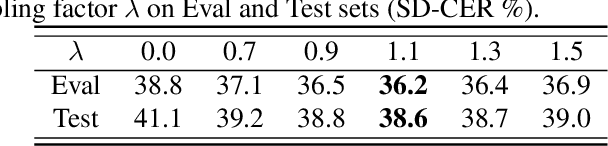
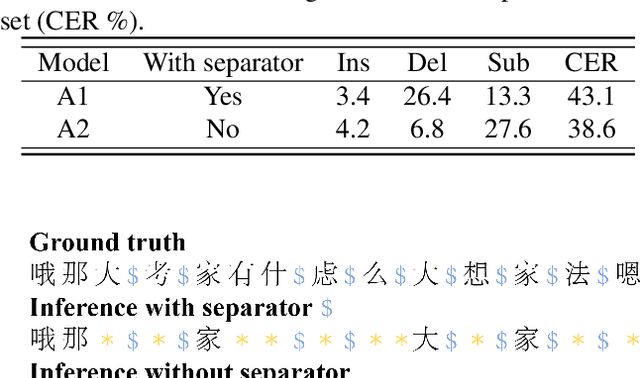
Joint modeling of multi-speaker ASR and speaker diarization has recently shown promising results in speaker-attributed automatic speech recognition (SA-ASR).Although being able to obtain state-of-the-art (SOTA) performance, most of the studies are based on an autoregressive (AR) decoder which generates tokens one-by-one and results in a large real-time factor (RTF). To speed up inference, we introduce a recently proposed non-autoregressive model Paraformer as an acoustic model in the SA-ASR model.Paraformer uses a single-step decoder to enable parallel generation, obtaining comparable performance to the SOTA AR transformer models. Besides, we propose a speaker-filling strategy to reduce speaker identification errors and adopt an inter-CTC strategy to enhance the encoder's ability in acoustic modeling. Experiments on the AliMeeting corpus show that our model outperforms the cascaded SA-ASR model by a 6.1% relative speaker-dependent character error rate (SD-CER) reduction on the test set. Moreover, our model achieves a comparable SD-CER of 34.8% with only 1/10 RTF compared with the SOTA joint AR SA-ASR model.
GeRA: Label-Efficient Geometrically Regularized Alignment
Oct 07, 2023Pretrained unimodal encoders incorporate rich semantic information into embedding space structures. To be similarly informative, multi-modal encoders typically require massive amounts of paired data for alignment and training. We introduce a semi-supervised Geometrically Regularized Alignment (GeRA) method to align the embedding spaces of pretrained unimodal encoders in a label-efficient way. Our method leverages the manifold geometry of unpaired (unlabeled) data to improve alignment performance. To prevent distortions to local geometry during the alignment process, potentially disrupting semantic neighborhood structures and causing misalignment of unobserved pairs, we introduce a geometric loss term. This term is built upon a diffusion operator that captures the local manifold geometry of the unimodal pretrained encoders. GeRA is modality-agnostic and thus can be used to align pretrained encoders from any data modalities. We provide empirical evidence to the effectiveness of our method in the domains of speech-text and image-text alignment. Our experiments demonstrate significant improvement in alignment quality compared to a variaty of leading baselines, especially with a small amount of paired data, using our proposed geometric regularization.
Updated Corpora and Benchmarks for Long-Form Speech Recognition
Sep 26, 2023The vast majority of ASR research uses corpora in which both the training and test data have been pre-segmented into utterances. In most real-word ASR use-cases, however, test audio is not segmented, leading to a mismatch between inference-time conditions and models trained on segmented utterances. In this paper, we re-release three standard ASR corpora - TED-LIUM 3, Gigapeech, and VoxPopuli-en - with updated transcription and alignments to enable their use for long-form ASR research. We use these reconstituted corpora to study the train-test mismatch problem for transducers and attention-based encoder-decoders (AEDs), confirming that AEDs are more susceptible to this issue. Finally, we benchmark a simple long-form training for these models, showing its efficacy for model robustness under this domain shift.
Inaudible Adversarial Perturbation: Manipulating the Recognition of User Speech in Real Tim
Aug 02, 2023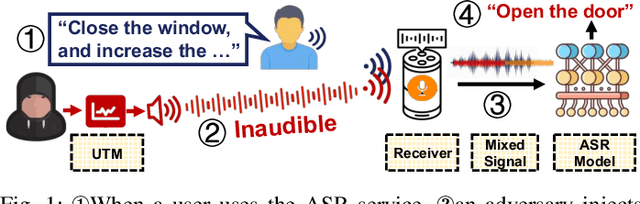
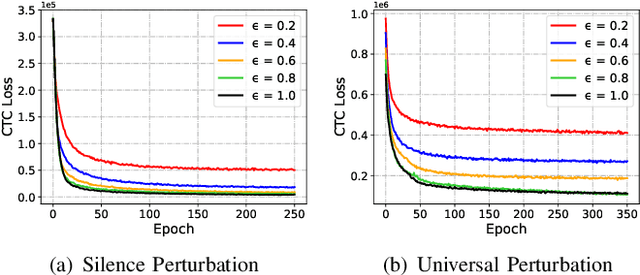
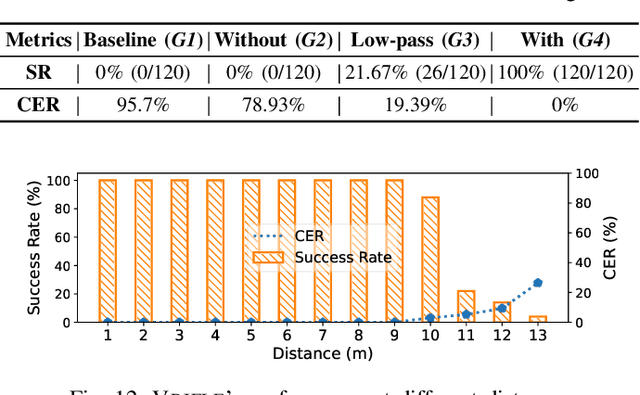
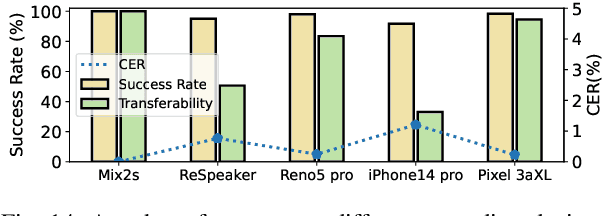
Automatic speech recognition (ASR) systems have been shown to be vulnerable to adversarial examples (AEs). Recent success all assumes that users will not notice or disrupt the attack process despite the existence of music/noise-like sounds and spontaneous responses from voice assistants. Nonetheless, in practical user-present scenarios, user awareness may nullify existing attack attempts that launch unexpected sounds or ASR usage. In this paper, we seek to bridge the gap in existing research and extend the attack to user-present scenarios. We propose VRIFLE, an inaudible adversarial perturbation (IAP) attack via ultrasound delivery that can manipulate ASRs as a user speaks. The inherent differences between audible sounds and ultrasounds make IAP delivery face unprecedented challenges such as distortion, noise, and instability. In this regard, we design a novel ultrasonic transformation model to enhance the crafted perturbation to be physically effective and even survive long-distance delivery. We further enable VRIFLE's robustness by adopting a series of augmentation on user and real-world variations during the generation process. In this way, VRIFLE features an effective real-time manipulation of the ASR output from different distances and under any speech of users, with an alter-and-mute strategy that suppresses the impact of user disruption. Our extensive experiments in both digital and physical worlds verify VRIFLE's effectiveness under various configurations, robustness against six kinds of defenses, and universality in a targeted manner. We also show that VRIFLE can be delivered with a portable attack device and even everyday-life loudspeakers.
Don't Stop Self-Supervision: Accent Adaptation of Speech Representations via Residual Adapters
Jul 02, 2023
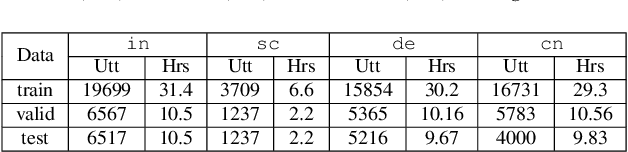
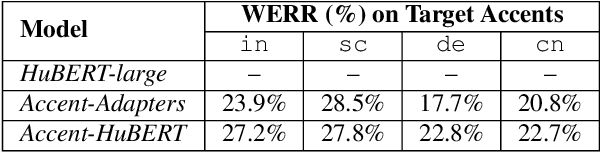
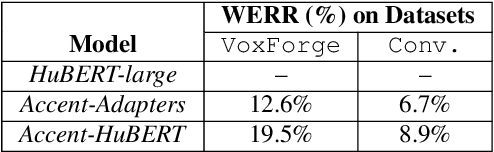
Speech representations learned in a self-supervised fashion from massive unlabeled speech corpora have been adapted successfully toward several downstream tasks. However, such representations may be skewed toward canonical data characteristics of such corpora and perform poorly on atypical, non-native accented speaker populations. With the state-of-the-art HuBERT model as a baseline, we propose and investigate self-supervised adaptation of speech representations to such populations in a parameter-efficient way via training accent-specific residual adapters. We experiment with 4 accents and choose automatic speech recognition (ASR) as the downstream task of interest. We obtain strong word error rate reductions (WERR) over HuBERT-large for all 4 accents, with a mean WERR of 22.7% with accent-specific adapters and a mean WERR of 25.1% if the entire encoder is accent-adapted. While our experiments utilize HuBERT and ASR as the downstream task, our proposed approach is both model and task-agnostic.
Use of Speech Impairment Severity for Dysarthric Speech Recognition
May 18, 2023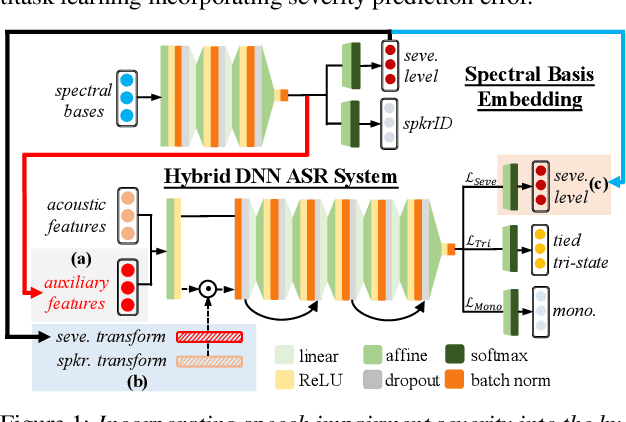

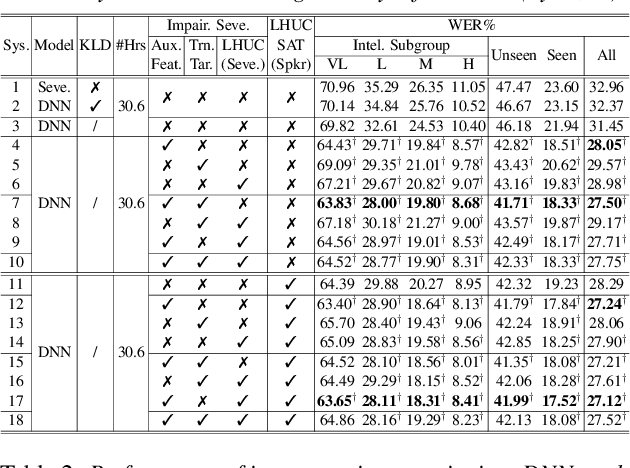
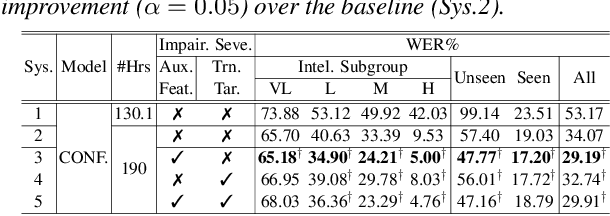
A key challenge in dysarthric speech recognition is the speaker-level diversity attributed to both speaker-identity associated factors such as gender, and speech impairment severity. Most prior researches on addressing this issue focused on using speaker-identity only. To this end, this paper proposes a novel set of techniques to use both severity and speaker-identity in dysarthric speech recognition: a) multitask training incorporating severity prediction error; b) speaker-severity aware auxiliary feature adaptation; and c) structured LHUC transforms separately conditioned on speaker-identity and severity. Experiments conducted on UASpeech suggest incorporating additional speech impairment severity into state-of-the-art hybrid DNN, E2E Conformer and pre-trained Wav2vec 2.0 ASR systems produced statistically significant WER reductions up to 4.78% (14.03% relative). Using the best system the lowest published WER of 17.82% (51.25% on very low intelligibility) was obtained on UASpeech.
SpeechGLUE: How Well Can Self-Supervised Speech Models Capture Linguistic Knowledge?
Jun 14, 2023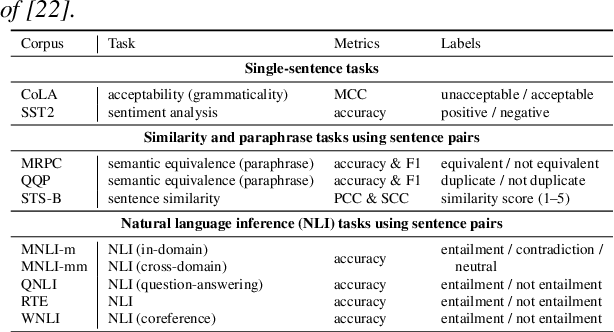
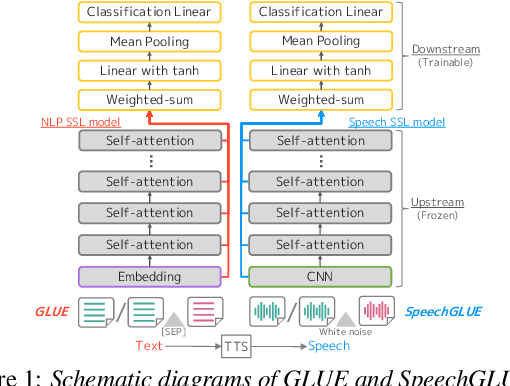
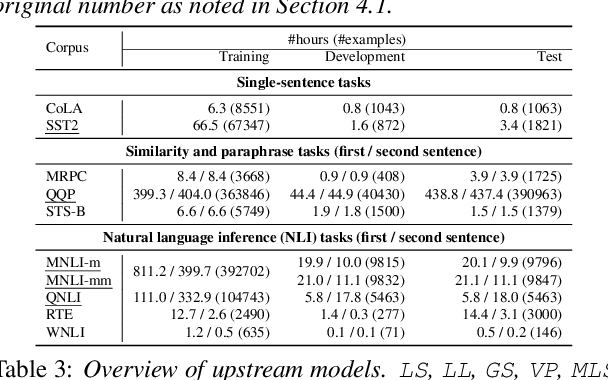
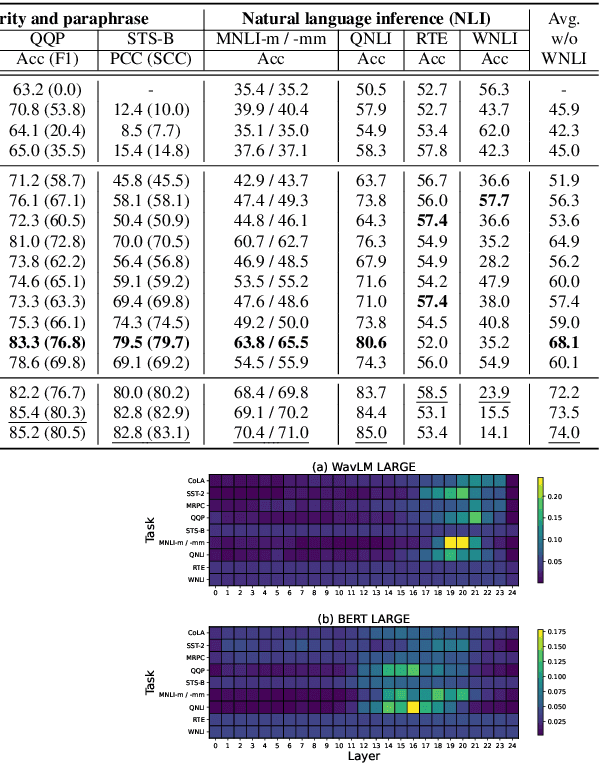
Self-supervised learning (SSL) for speech representation has been successfully applied in various downstream tasks, such as speech and speaker recognition. More recently, speech SSL models have also been shown to be beneficial in advancing spoken language understanding tasks, implying that the SSL models have the potential to learn not only acoustic but also linguistic information. In this paper, we aim to clarify if speech SSL techniques can well capture linguistic knowledge. For this purpose, we introduce SpeechGLUE, a speech version of the General Language Understanding Evaluation (GLUE) benchmark. Since GLUE comprises a variety of natural language understanding tasks, SpeechGLUE can elucidate the degree of linguistic ability of speech SSL models. Experiments demonstrate that speech SSL models, although inferior to text-based SSL models, perform better than baselines, suggesting that they can acquire a certain amount of general linguistic knowledge from just unlabeled speech data.