 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Toward domain-invariant speech recognition via large scale training
Aug 16, 2018
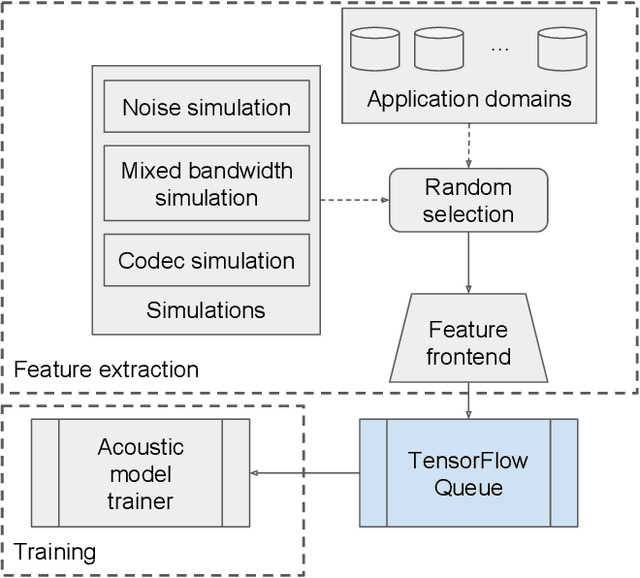
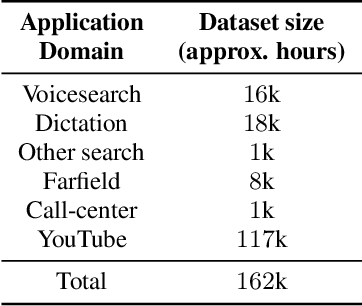
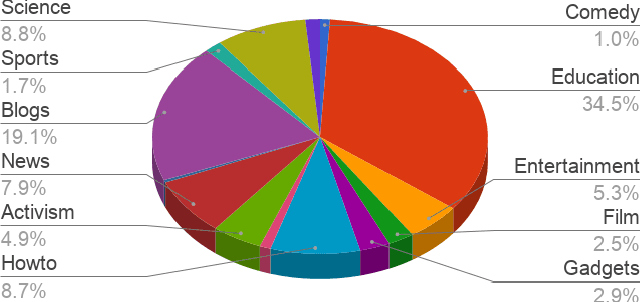
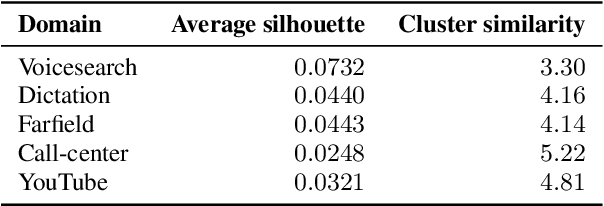
Current state-of-the-art automatic speech recognition systems are trained to work in specific `domains', defined based on factors like application, sampling rate and codec. When such recognizers are used in conditions that do not match the training domain, performance significantly drops. This work explores the idea of building a single domain-invariant model for varied use-cases by combining large scale training data from multiple application domains. Our final system is trained using 162,000 hours of speech. Additionally, each utterance is artificially distorted during training to simulate effects like background noise, codec distortion, and sampling rates. Our results show that, even at such a scale, a model thus trained works almost as well as those fine-tuned to specific subsets: A single model can be robust to multiple application domains, and variations like codecs and noise. More importantly, such models generalize better to unseen conditions and allow for rapid adaptation -- we show that by using as little as 10 hours of data from a new domain, an adapted domain-invariant model can match performance of a domain-specific model trained from scratch using 70 times as much data. We also highlight some of the limitations of such models and areas that need addressing in future work.
Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation
Aug 11, 2021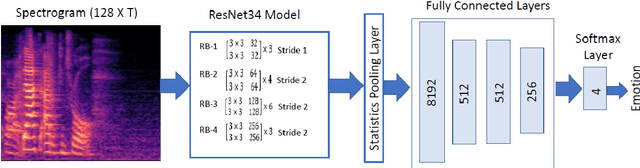
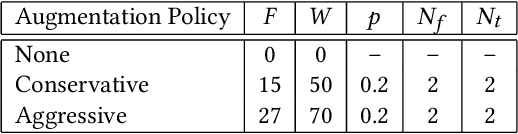
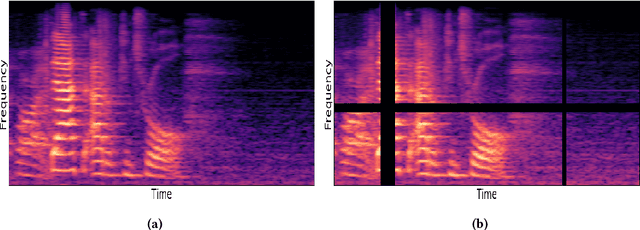
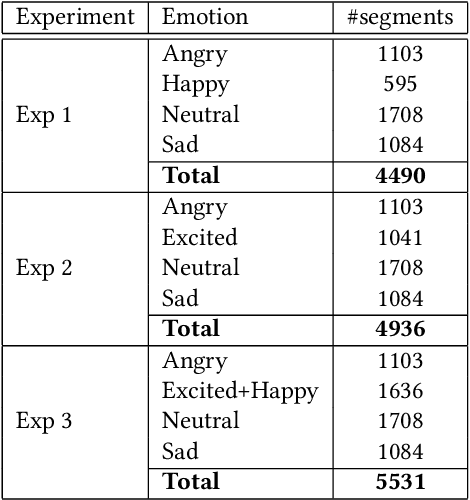
Automatic speech emotion recognition (SER) is a challenging task that plays a crucial role in natural human-computer interaction. One of the main challenges in SER is data scarcity, i.e., insufficient amounts of carefully labeled data to build and fully explore complex deep learning models for emotion classification. This paper aims to address this challenge using a transfer learning strategy combined with spectrogram augmentation. Specifically, we propose a transfer learning approach that leverages a pre-trained residual network (ResNet) model including a statistics pooling layer from speaker recognition trained using large amounts of speaker-labeled data. The statistics pooling layer enables the model to efficiently process variable-length input, thereby eliminating the need for sequence truncation which is commonly used in SER systems. In addition, we adopt a spectrogram augmentation technique to generate additional training data samples by applying random time-frequency masks to log-mel spectrograms to mitigate overfitting and improve the generalization of emotion recognition models. We evaluate the effectiveness of our proposed approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that the transfer learning and spectrogram augmentation approaches improve the SER performance, and when combined achieve state-of-the-art results.
Improving Noise Robustness of Contrastive Speech Representation Learning with Speech Reconstruction
Oct 28, 2021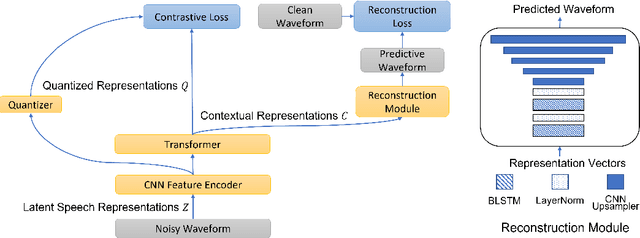
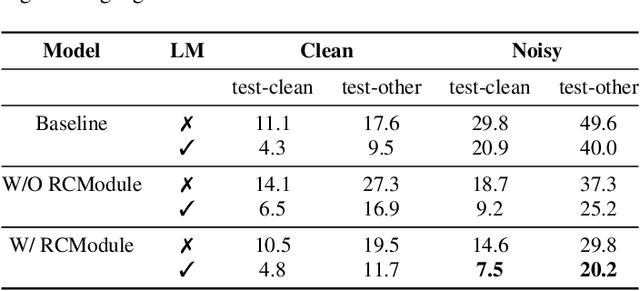
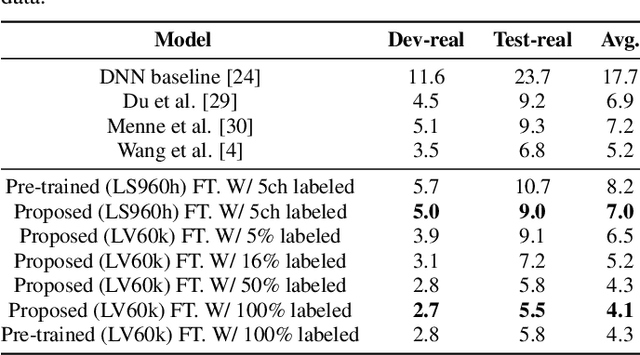
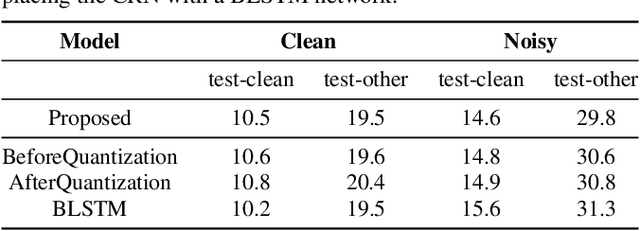
Noise robustness is essential for deploying automatic speech recognition (ASR) systems in real-world environments. One way to reduce the effect of noise interference is to employ a preprocessing module that conducts speech enhancement, and then feed the enhanced speech to an ASR backend. In this work, instead of suppressing background noise with a conventional cascaded pipeline, we employ a noise-robust representation learned by a refined self-supervised framework for noisy speech recognition. We propose to combine a reconstruction module with contrastive learning and perform multi-task continual pre-training on noisy data. The reconstruction module is used for auxiliary learning to improve the noise robustness of the learned representation and thus is not required during inference. Experiments demonstrate the effectiveness of our proposed method. Our model substantially reduces the word error rate (WER) for the synthesized noisy LibriSpeech test sets, and yields around 4.1/7.5% WER reduction on noisy clean/other test sets compared to data augmentation. For the real-world noisy speech from the CHiME-4 challenge (1-channel track), we have obtained the state of the art ASR performance without any denoising front-end. Moreover, we achieve comparable performance to the best supervised approach reported with only 16% of labeled data.
Unsupervised Data Selection via Discrete Speech Representation for ASR
Apr 05, 2022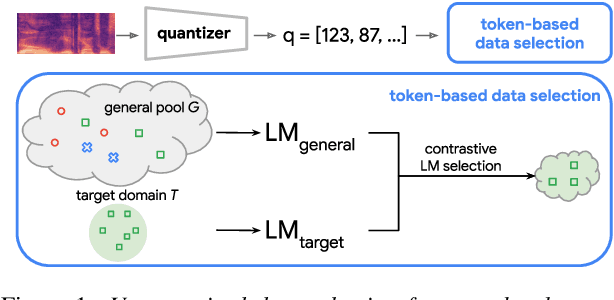


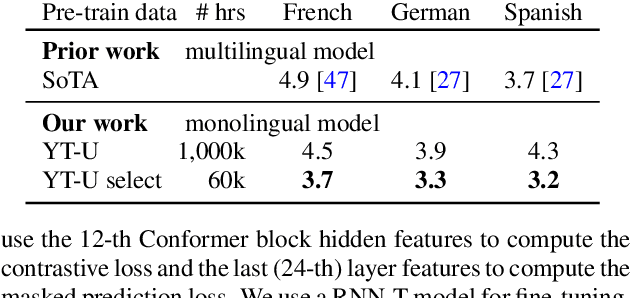
Self-supervised learning of speech representations has achieved impressive results in improving automatic speech recognition (ASR). In this paper, we show that data selection is important for self-supervised learning. We propose a simple and effective unsupervised data selection method which selects acoustically similar speech to a target domain. It takes the discrete speech representation available in common self-supervised learning frameworks as input, and applies a contrastive data selection method on the discrete tokens. Through extensive empirical studies we show that our proposed method reduces the amount of required pre-training data and improves the downstream ASR performance. Pre-training on a selected subset of 6% of the general data pool results in 11.8% relative improvements in LibriSpeech test-other compared to pre-training on the full set. On Multilingual LibriSpeech French, German, and Spanish test sets, selecting 6% data for pre-training reduces word error rate by more than 15% relatively compared to the full set, and achieves competitive results compared to current state-of-the-art performances.
Factorized Neural Transducer for Efficient Language Model Adaptation
Oct 07, 2021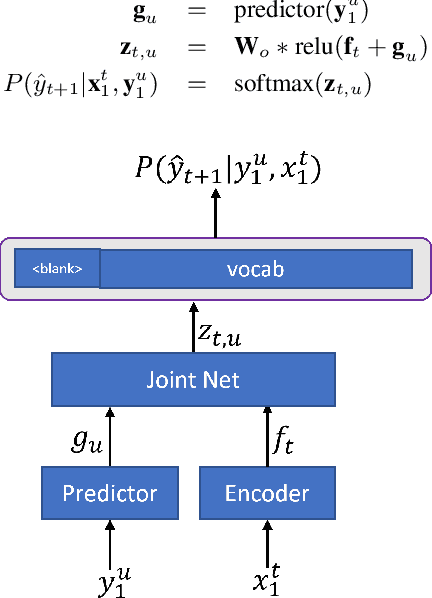

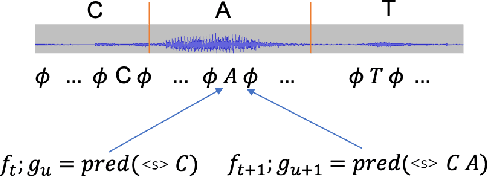
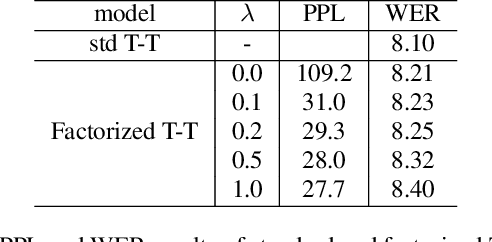
In recent years, end-to-end (E2E) based automatic speech recognition (ASR) systems have achieved great success due to their simplicity and promising performance. Neural Transducer based models are increasingly popular in streaming E2E based ASR systems and have been reported to outperform the traditional hybrid system in some scenarios. However, the joint optimization of acoustic model, lexicon and language model in neural Transducer also brings about challenges to utilize pure text for language model adaptation. This drawback might prevent their potential applications in practice. In order to address this issue, in this paper, we propose a novel model, factorized neural Transducer, by factorizing the blank and vocabulary prediction, and adopting a standalone language model for the vocabulary prediction. It is expected that this factorization can transfer the improvement of the standalone language model to the Transducer for speech recognition, which allows various language model adaptation techniques to be applied. We demonstrate that the proposed factorized neural Transducer yields 15% to 20% WER improvements when out-of-domain text data is used for language model adaptation, at the cost of a minor degradation in WER on a general test set.
Deep-FSMN for Large Vocabulary Continuous Speech Recognition
Mar 04, 2018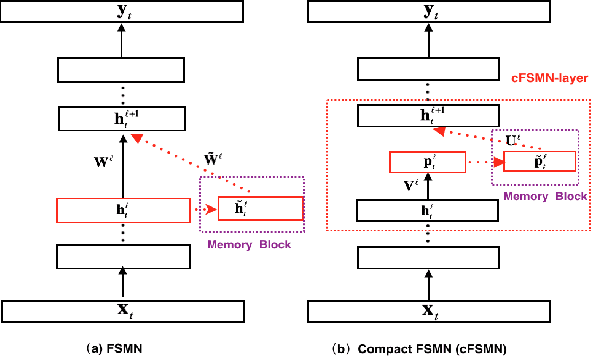
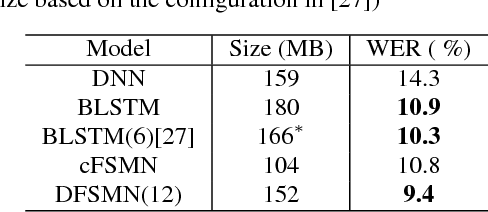
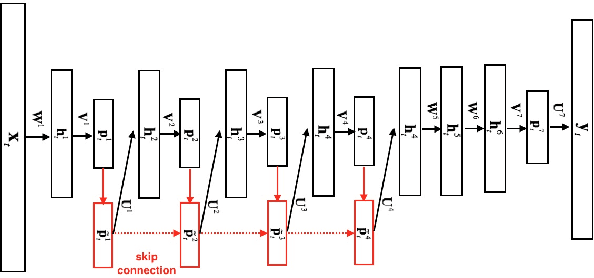
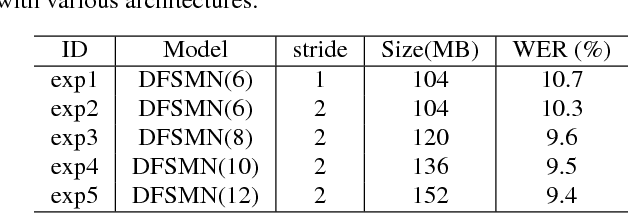
In this paper, we present an improved feedforward sequential memory networks (FSMN) architecture, namely Deep-FSMN (DFSMN), by introducing skip connections between memory blocks in adjacent layers. These skip connections enable the information flow across different layers and thus alleviate the gradient vanishing problem when building very deep structure. As a result, DFSMN significantly benefits from these skip connections and deep structure. We have compared the performance of DFSMN to BLSTM both with and without lower frame rate (LFR) on several large speech recognition tasks, including English and Mandarin. Experimental results shown that DFSMN can consistently outperform BLSTM with dramatic gain, especially trained with LFR using CD-Phone as modeling units. In the 2000 hours Fisher (FSH) task, the proposed DFSMN can achieve a word error rate of 9.4% by purely using the cross-entropy criterion and decoding with a 3-gram language model, which achieves a 1.5% absolute improvement compared to the BLSTM. In a 20000 hours Mandarin recognition task, the LFR trained DFSMN can achieve more than 20% relative improvement compared to the LFR trained BLSTM. Moreover, we can easily design the lookahead filter order of the memory blocks in DFSMN to control the latency for real-time applications.
Deliberation Model for On-Device Spoken Language Understanding
Apr 04, 2022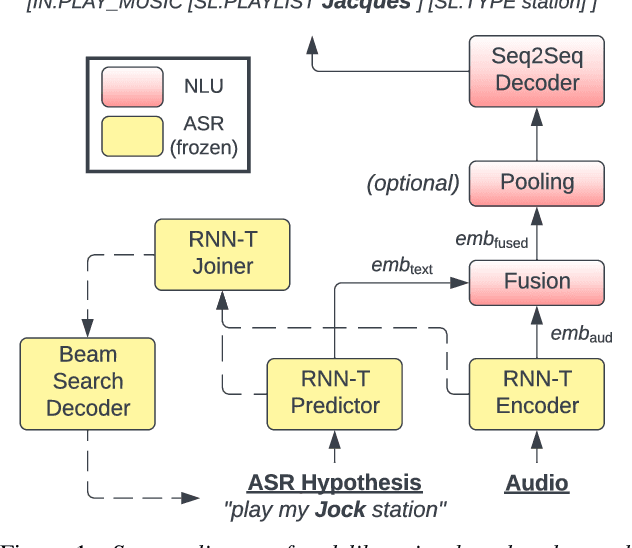

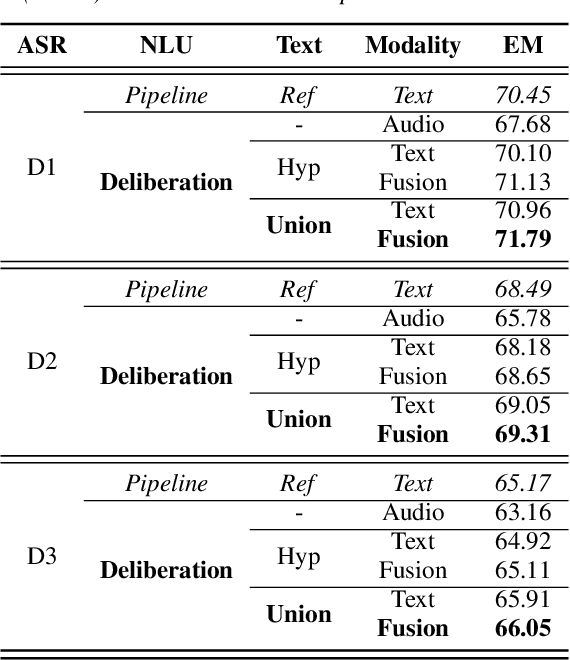
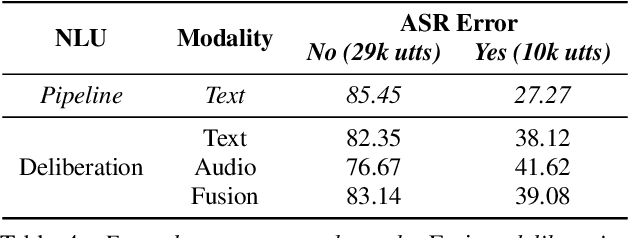
We propose a novel deliberation-based approach to end-to-end (E2E) spoken language understanding (SLU), where a streaming automatic speech recognition (ASR) model produces the first-pass hypothesis and a second-pass natural language understanding (NLU) component generates the semantic parse by conditioning on both ASR's text and audio embeddings. By formulating E2E SLU as a generalized decoder, our system is able to support complex compositional semantic structures. Furthermore, the sharing of parameters between ASR and NLU makes the system especially suitable for resource-constrained (on-device) environments; our proposed approach consistently outperforms strong pipeline NLU baselines by 0.82% to 1.34% across various operating points on the spoken version of the TOPv2 dataset. We demonstrate that the fusion of text and audio features, coupled with the system's ability to rewrite the first-pass hypothesis, makes our approach more robust to ASR errors. Finally, we show that our approach can significantly reduce the degradation when moving from natural speech to synthetic speech training, but more work is required to make text-to-speech (TTS) a viable solution for scaling up E2E SLU.
Constructing Long Short-Term Memory based Deep Recurrent Neural Networks for Large Vocabulary Speech Recognition
May 11, 2015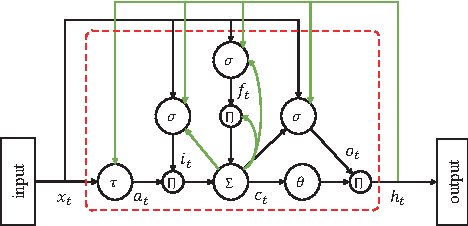
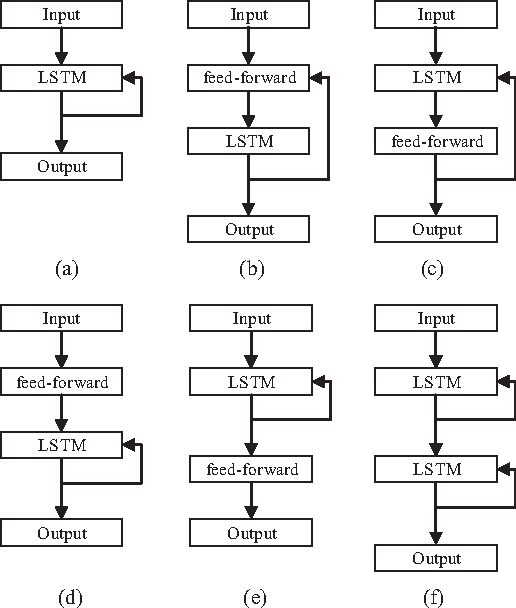

Long short-term memory (LSTM) based acoustic modeling methods have recently been shown to give state-of-the-art performance on some speech recognition tasks. To achieve a further performance improvement, in this research, deep extensions on LSTM are investigated considering that deep hierarchical model has turned out to be more efficient than a shallow one. Motivated by previous research on constructing deep recurrent neural networks (RNNs), alternative deep LSTM architectures are proposed and empirically evaluated on a large vocabulary conversational telephone speech recognition task. Meanwhile, regarding to multi-GPU devices, the training process for LSTM networks is introduced and discussed. Experimental results demonstrate that the deep LSTM networks benefit from the depth and yield the state-of-the-art performance on this task.
Phoneme-Based Contextualization for Cross-Lingual Speech Recognition in End-to-End Models
Jul 22, 2019


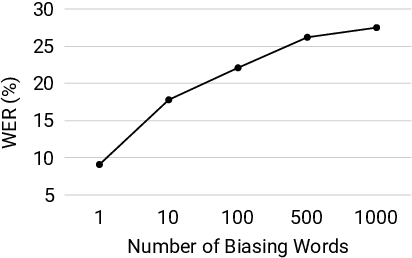
Contextual automatic speech recognition, i.e., biasing recognition towards a given context (e.g. user's playlists, or contacts), is challenging in end-to-end (E2E) models. Such models maintain a limited number of candidates during beam-search decoding, and have been found to recognize rare named entities poorly. The problem is exacerbated when biasing towards proper nouns in foreign languages, e.g., geographic location names, which are virtually unseen in training and are thus out-of-vocabulary (OOV). While grapheme or wordpiece E2E models might have a difficult time spelling OOV words, phonemes are more acoustically salient and past work has shown that E2E phoneme models can better predict such words. In this work, we propose an E2E model containing both English wordpieces and phonemes in the modeling space, and perform contextual biasing of foreign words at the phoneme level by mapping pronunciations of foreign words into similar English phonemes. In experimental evaluations, we find that the proposed approach performs 16% better than a grapheme-only biasing model, and 8% better than a wordpiece-only biasing model on a foreign place name recognition task, with only slight degradation on regular English tasks.
Multimodal Depression Classification Using Articulatory Coordination Features And Hierarchical Attention Based Text Embeddings
Feb 13, 2022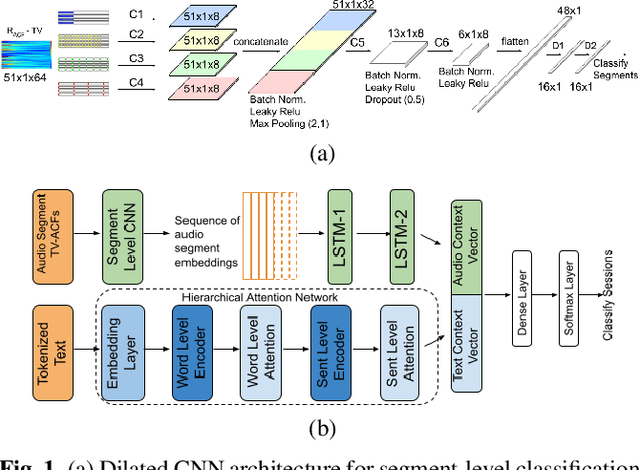

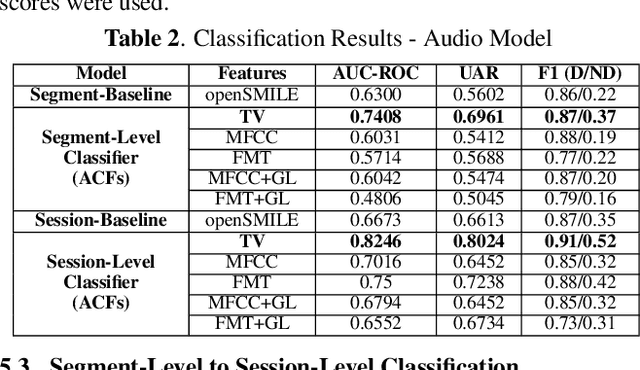
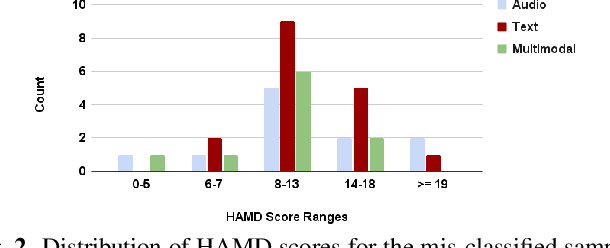
Multimodal depression classification has gained immense popularity over the recent years. We develop a multimodal depression classification system using articulatory coordination features extracted from vocal tract variables and text transcriptions obtained from an automatic speech recognition tool that yields improvements of area under the receiver operating characteristics curve compared to uni-modal classifiers (7.5% and 13.7% for audio and text respectively). We show that in the case of limited training data, a segment-level classifier can first be trained to then obtain a session-wise prediction without hindering the performance, using a multi-stage convolutional recurrent neural network. A text model is trained using a Hierarchical Attention Network (HAN). The multimodal system is developed by combining embeddings from the session-level audio model and the HAN text model