 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneme-Based Contextualization for Cross-Lingual Speech Recognition in End-to-End Models
Paper and Code
Jul 22, 2019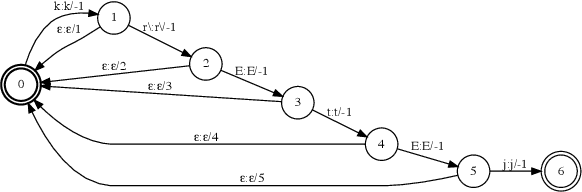


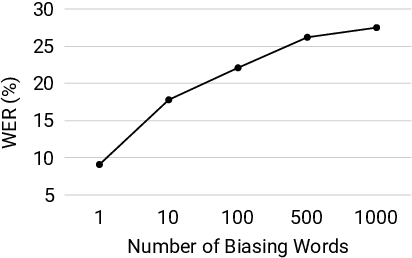
Contextual automatic speech recognition, i.e., biasing recognition towards a given context (e.g. user's playlists, or contacts), is challenging in end-to-end (E2E) models. Such models maintain a limited number of candidates during beam-search decoding, and have been found to recognize rare named entities poorly. The problem is exacerbated when biasing towards proper nouns in foreign languages, e.g., geographic location names, which are virtually unseen in training and are thus out-of-vocabulary (OOV). While grapheme or wordpiece E2E models might have a difficult time spelling OOV words, phonemes are more acoustically salient and past work has shown that E2E phoneme models can better predict such words. In this work, we propose an E2E model containing both English wordpieces and phonemes in the modeling space, and perform contextual biasing of foreign words at the phoneme level by mapping pronunciations of foreign words into similar English phonemes. In experimental evaluations, we find that the proposed approach performs 16% better than a grapheme-only biasing model, and 8% better than a wordpiece-only biasing model on a foreign place name recognition task, with only slight degradation on regular English tasks.