 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
Efficient Monotonic Multihead Attention
Dec 07, 2023



We introduce the Efficient Monotonic Multihead Attention (EMMA), a state-of-the-art simultaneous translation model with numerically-stable and unbiased monotonic alignment estimation. In addition, we present improved training and inference strategies, including simultaneous fine-tuning from an offline translation model and reduction of monotonic alignment variance. The experimental results demonstrate that the proposed model attains state-of-the-art performance in simultaneous speech-to-text translation on the Spanish and English translation task.
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
Scaling Speech Technology to 1,000+ Languages
May 22, 2023Expanding the language coverage of speech technology has the potential to improve access to information for many more people. However, current speech technology is restricted to about one hundred languages which is a small fraction of the over 7,000 languages spoken around the world. The Massively Multilingual Speech (MMS) project increases the number of supported languages by 10-40x, depending on the task. The main ingredients are a new dataset based on readings of publicly available religious texts and effectively leveraging self-supervised learning. We built pre-trained wav2vec 2.0 models covering 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for the same number of languages, as well as a language identification model for 4,017 languages. Experiments show that our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark while being trained on a small fraction of the labeled data.
Efficient Speech Representation Learning with Low-Bit Quantization
Dec 14, 2022


With the development of hardware for machine learning, newer models often come at the cost of both increased sizes and computational complexity. In effort to improve the efficiency for these models, we apply and investigate recent quantization techniques on speech representation learning models. The quantization techniques were evaluated on the SUPERB benchmark. On the ASR task, with aggressive quantization to 1 bit, we achieved 86.32% storage reduction (184.42 -> 25.23), 88% estimated runtime reduction (1.00 -> 0.12) with increased word error rate (7.06 -> 15.96). In comparison with DistillHuBERT which also aims for model compression, the 2-bit configuration yielded slightly smaller storage (35.84 vs. 46.98), better word error rate (12.68 vs. 13.37) and more efficient estimated runtime (0.15 vs. 0.73).
Continual Learning for On-Device Speech Recognition using Disentangled Conformers
Dec 13, 2022



Automatic speech recognition research focuses on training and evaluating on static datasets. Yet, as speech models are increasingly deployed on personal devices, such models encounter user-specific distributional shifts. To simulate this real-world scenario, we introduce LibriContinual, a continual learning benchmark for speaker-specific domain adaptation derived from LibriVox audiobooks, with data corresponding to 118 individual speakers and 6 train splits per speaker of different sizes. Additionally, current speech recognition models and continual learning algorithms are not optimized to be compute-efficient. We adapt a general-purpose training algorithm NetAug for ASR and create a novel Conformer variant called the DisConformer (Disentangled Conformer). This algorithm produces ASR models consisting of a frozen 'core' network for general-purpose use and several tunable 'augment' networks for speaker-specific tuning. Using such models, we propose a novel compute-efficient continual learning algorithm called DisentangledCL. Our experiments show that the DisConformer models significantly outperform baselines on general ASR i.e. LibriSpeech (15.58% rel. WER on test-other). On speaker-specific LibriContinual they significantly outperform trainable-parameter-matched baselines (by 20.65% rel. WER on test) and even match fully finetuned baselines in some settings.
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022



We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
Deliberation Model for On-Device Spoken Language Understanding
Apr 04, 2022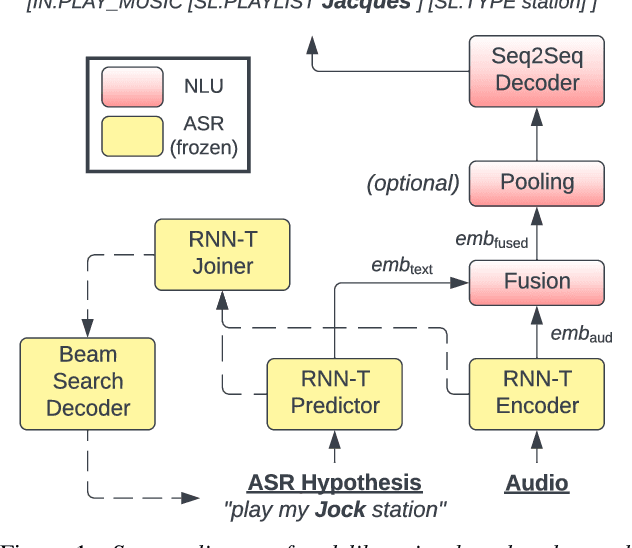

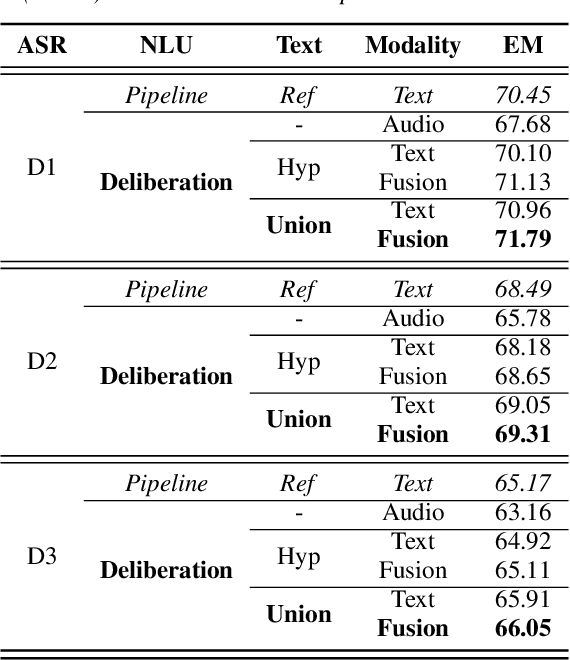
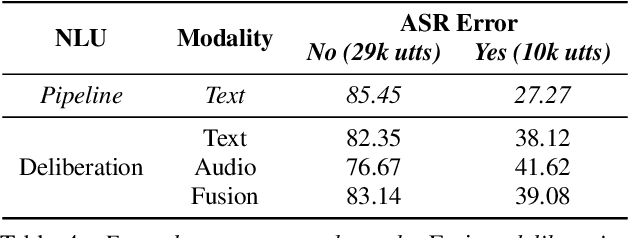
We propose a novel deliberation-based approach to end-to-end (E2E) spoken language understanding (SLU), where a streaming automatic speech recognition (ASR) model produces the first-pass hypothesis and a second-pass natural language understanding (NLU) component generates the semantic parse by conditioning on both ASR's text and audio embeddings. By formulating E2E SLU as a generalized decoder, our system is able to support complex compositional semantic structures. Furthermore, the sharing of parameters between ASR and NLU makes the system especially suitable for resource-constrained (on-device) environments; our proposed approach consistently outperforms strong pipeline NLU baselines by 0.82% to 1.34% across various operating points on the spoken version of the TOPv2 dataset. We demonstrate that the fusion of text and audio features, coupled with the system's ability to rewrite the first-pass hypothesis, makes our approach more robust to ASR errors. Finally, we show that our approach can significantly reduce the degradation when moving from natural speech to synthetic speech training, but more work is required to make text-to-speech (TTS) a viable solution for scaling up E2E SLU.
Generative Spoken Dialogue Language Modeling
Mar 30, 2022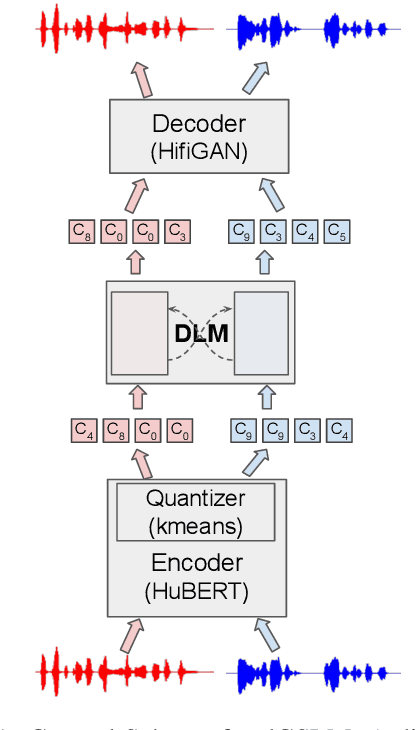
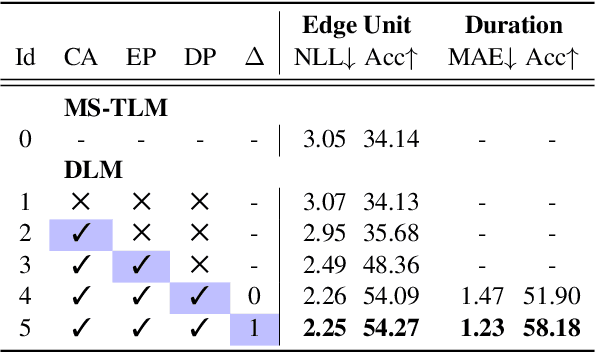
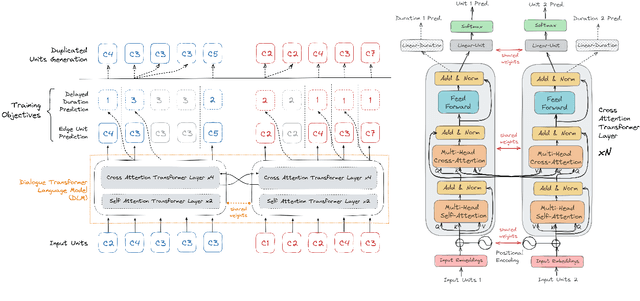
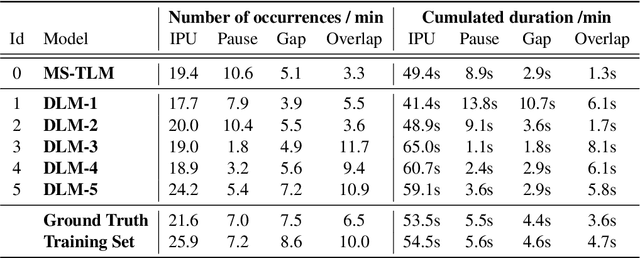
We introduce dGSLM, the first "textless" model able to generate audio samples of naturalistic spoken dialogues. It uses recent work on unsupervised spoken unit discovery coupled with a dual-tower transformer architecture with cross-attention trained on 2000 hours of two-channel raw conversational audio (Fisher dataset) without any text or labels. It is able to generate speech, laughter and other paralinguistic signals in the two channels simultaneously and reproduces naturalistic turn taking. Generation samples can be found at: https://speechbot.github.io/dgslm.