 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
Toward domain-invariant speech recognition via large scale training
Aug 16, 2018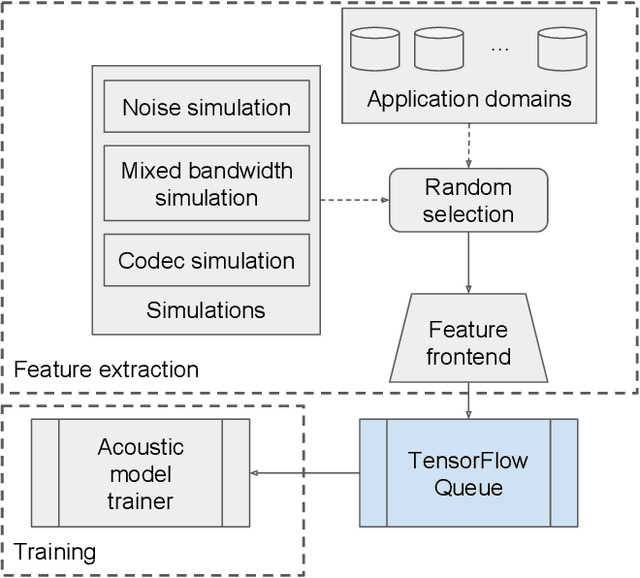
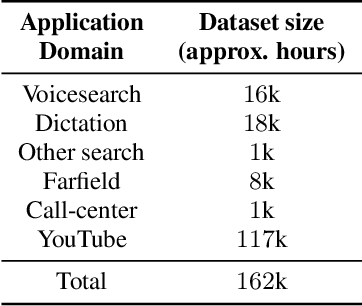
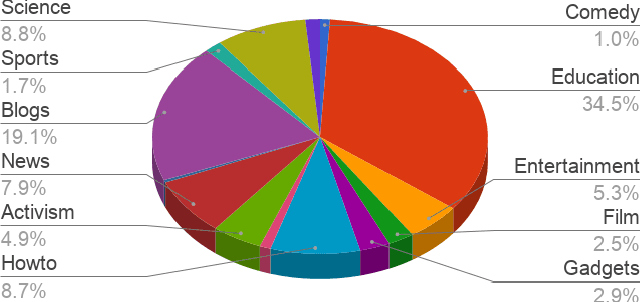
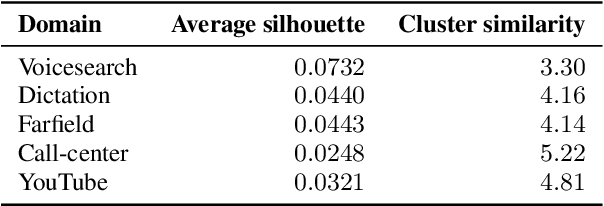
Current state-of-the-art automatic speech recognition systems are trained to work in specific `domains', defined based on factors like application, sampling rate and codec. When such recognizers are used in conditions that do not match the training domain, performance significantly drops. This work explores the idea of building a single domain-invariant model for varied use-cases by combining large scale training data from multiple application domains. Our final system is trained using 162,000 hours of speech. Additionally, each utterance is artificially distorted during training to simulate effects like background noise, codec distortion, and sampling rates. Our results show that, even at such a scale, a model thus trained works almost as well as those fine-tuned to specific subsets: A single model can be robust to multiple application domains, and variations like codecs and noise. More importantly, such models generalize better to unseen conditions and allow for rapid adaptation -- we show that by using as little as 10 hours of data from a new domain, an adapted domain-invariant model can match performance of a domain-specific model trained from scratch using 70 times as much data. We also highlight some of the limitations of such models and areas that need addressing in future work.