 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Training for Speech Recognition on Coprocessors
Mar 22, 2020
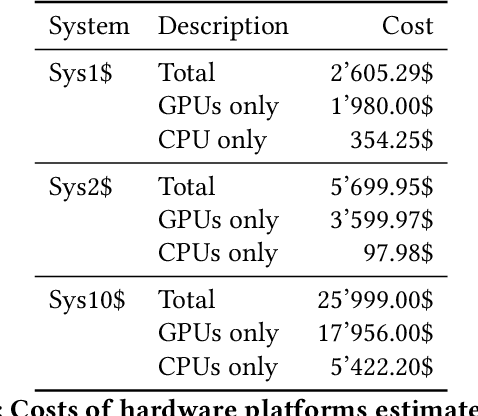

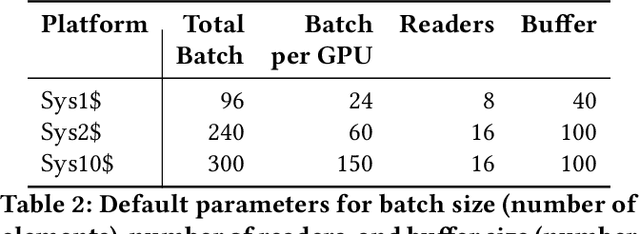
Automatic Speech Recognition (ASR) has increased in popularity in recent years. The evolution of processor and storage technologies has enabled more advanced ASR mechanisms, fueling the development of virtual assistants such as Amazon Alexa, Apple Siri, Microsoft Cortana, and Google Home. The interest in such assistants, in turn, has amplified the novel developments in ASR research. However, despite this popularity, there has not been a detailed training efficiency analysis of modern ASR systems. This mainly stems from: the proprietary nature of many modern applications that depend on ASR, like the ones listed above; the relatively expensive co-processor hardware that is used to accelerate ASR by big vendors to enable such applications; and the absence of well-established benchmarks. The goal of this paper is to address the latter two of these challenges. The paper first describes an ASR model, based on a deep neural network inspired by recent work in this domain, and our experiences building it. Then we evaluate this model on three CPU-GPU co-processor platforms that represent different budget categories. Our results demonstrate that utilizing hardware acceleration yields good results even without high-end equipment. While the most expensive platform (10X price of the least expensive one) converges to the initial accuracy target 10-30% and 60-70% faster than the other two, the differences among the platforms almost disappear at slightly higher accuracy targets. In addition, our results further highlight both the difficulty of evaluating ASR systems due to the complex, long, and resource intensive nature of the model training in this domain, and the importance of establishing benchmarks for ASR.
Phoneme-based speech recognition for commanding the robotic Arm
Jan 25, 2020
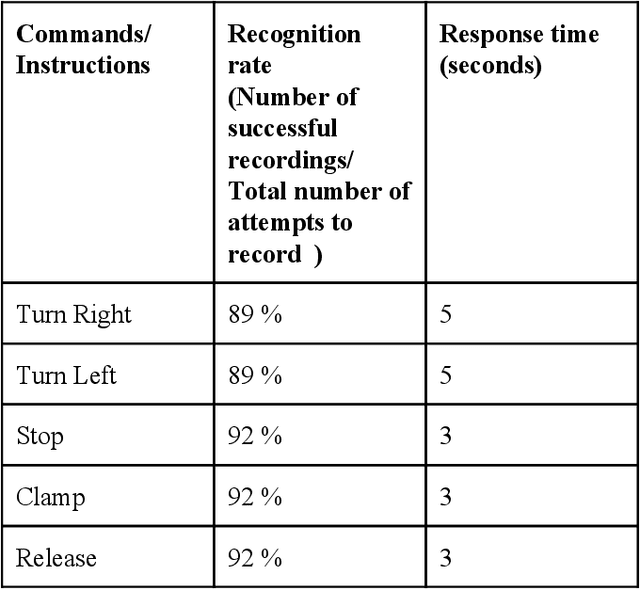

Controlling a robot still requires traditional user interfaces. A more intuitive approach is using verbal or gesture commands. In this paper, we propose a robotic arm that can recognize the human voice commands. The Speech recognition is an essential asset for the robot, enhancing its ability to interact with human beings using their natural form of communication. The approach is verified by deploying the robotic arm into different environments with low, high and medium noise perturbations, where it is tested to perform a set of tasks. With this approach, we have successfully reduced the response time, enhanced the accuracy of the robotic arm to grasp the voice commands and reduced the sentence overlapping by a significant amount. The entire system is divided into three modules: the manipulator, the voice recognition module and the microcontroller. The robotic arm is programmed to orient to the direction where the signal to noise ratio is maximum.
Improving Data Driven Inverse Text Normalization using Data Augmentation
Jul 20, 2022
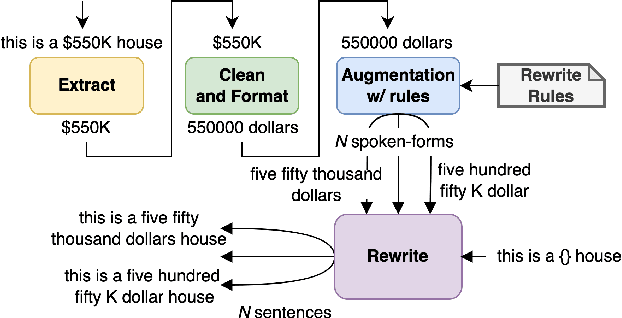

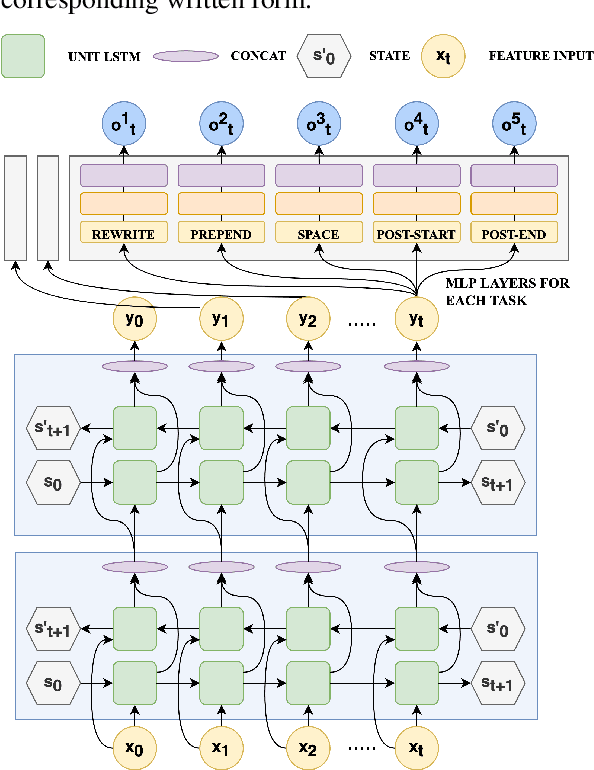
Inverse text normalization (ITN) is used to convert the spoken form output of an automatic speech recognition (ASR) system to a written form. Traditional handcrafted ITN rules can be complex to transcribe and maintain. Meanwhile neural modeling approaches require quality large-scale spoken-written pair examples in the same or similar domain as the ASR system (in-domain data), to train. Both these approaches require costly and complex annotations. In this paper, we present a data augmentation technique that effectively generates rich spoken-written numeric pairs from out-of-domain textual data with minimal human annotation. We empirically demonstrate that ITN model trained using our data augmentation technique consistently outperform ITN model trained using only in-domain data across all numeric surfaces like cardinal, currency, and fraction, by an overall accuracy of 14.44%.
Improving noise robustness of automatic speech recognition via parallel data and teacher-student learning
Jan 11, 2019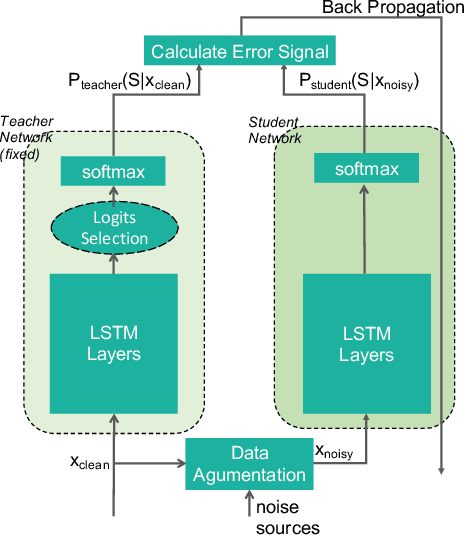
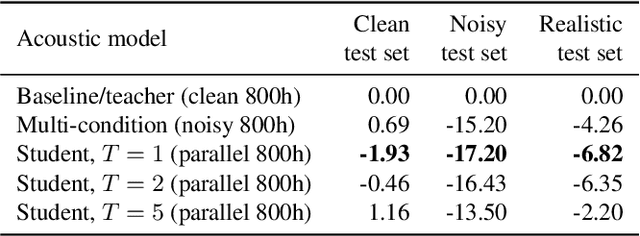
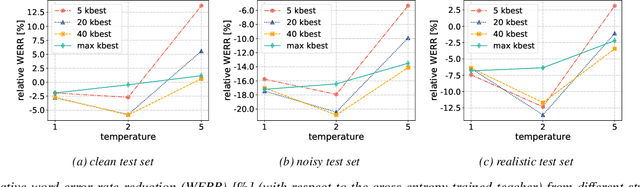
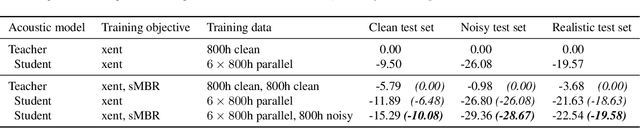
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the k highest values to prevent wrong emphasis of knowledge from the teacher and to reduce bandwidth needed for transferring data. We incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained models apart from cross entropy trained ones. The best sequence trained student model yields relative word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively comparing to a sequence trained teacher.
Improving Readability for Automatic Speech Recognition Transcription
Apr 09, 2020
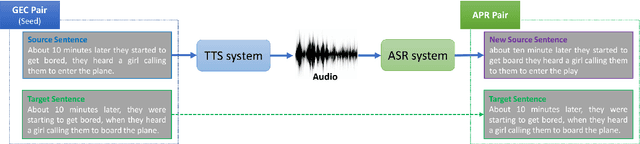
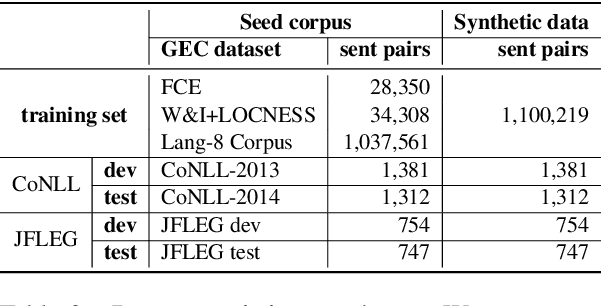
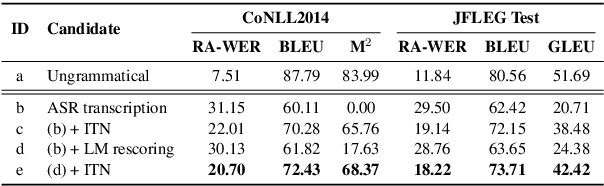
Modern Automatic Speech Recognition (ASR) systems can achieve high performance in terms of recognition accuracy. However, a perfectly accurate transcript still can be challenging to read due to grammatical errors, disfluency, and other errata common in spoken communication. Many downstream tasks and human readers rely on the output of the ASR system; therefore, errors introduced by the speaker and ASR system alike will be propagated to the next task in the pipeline. In this work, we propose a novel NLP task called ASR post-processing for readability (APR) that aims to transform the noisy ASR output into a readable text for humans and downstream tasks while maintaining the semantic meaning of the speaker. In addition, we describe a method to address the lack of task-specific data by synthesizing examples for the APR task using the datasets collected for Grammatical Error Correction (GEC) followed by text-to-speech (TTS) and ASR. Furthermore, we propose metrics borrowed from similar tasks to evaluate performance on the APR task. We compare fine-tuned models based on several open-sourced and adapted pre-trained models with the traditional pipeline method. Our results suggest that finetuned models improve the performance on the APR task significantly, hinting at the potential benefits of using APR systems. We hope that the read, understand, and rewrite approach of our work can serve as a basis that many NLP tasks and human readers can benefit from.
Distribution Aware Metrics for Conditional Natural Language Generation
Sep 15, 2022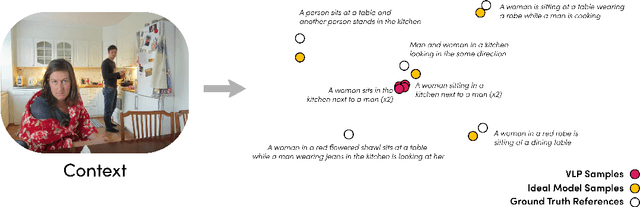
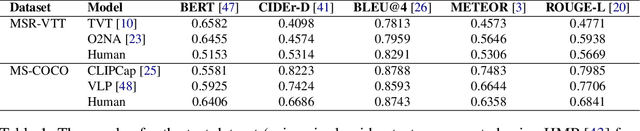

Traditional automated metrics for evaluating conditional natural language generation use pairwise comparisons between a single generated text and the best-matching gold-standard ground truth text. When multiple ground truths are available, scores are aggregated using an average or max operation across references. While this approach works well when diversity in the ground truth data (i.e. dispersion of the distribution of conditional texts) can be ascribed to noise, such as in automated speech recognition, it does not allow for robust evaluation in the case where diversity in the ground truths represents signal for the model. In this work we argue that existing metrics are not appropriate for domains such as visual description or summarization where ground truths are semantically diverse, and where the diversity in those captions captures useful additional information about the context. We propose a novel paradigm for multi-candidate evaluation of conditional language generation models, and a new family of metrics that compare the distributions of reference and model-generated caption sets using small sample sets of each. We demonstrate the utility of our approach with a case study in visual description: where we show that existing models optimize for single-description quality over diversity, and gain some insights into how sampling methods and temperature impact description quality and diversity.
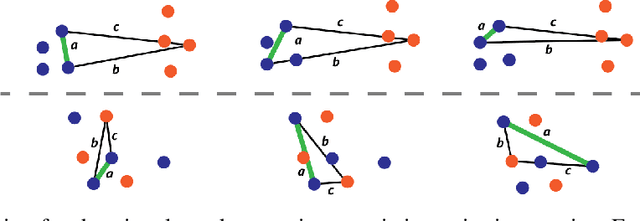
Meeting the Needs of Low-Resource Languages: The Value of Automatic Alignments via Pretrained Models
Feb 15, 2023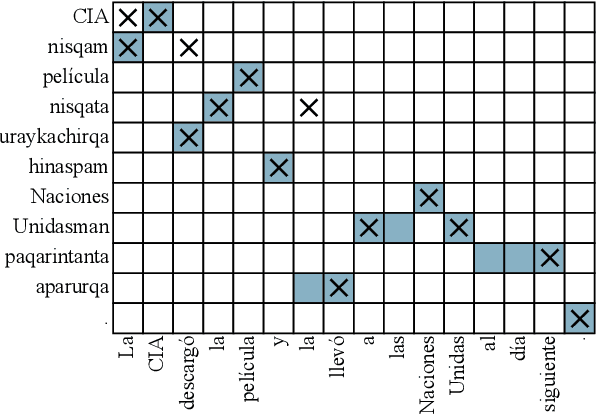
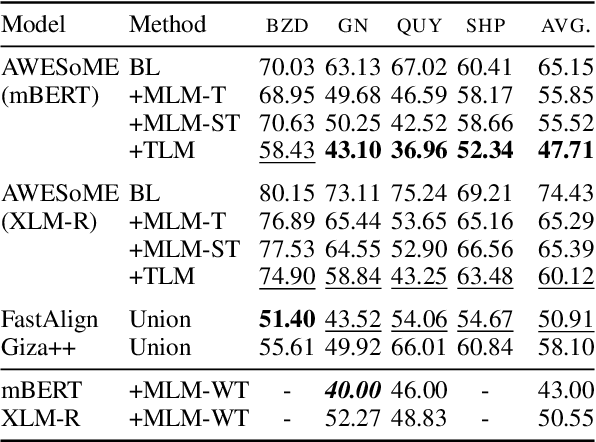
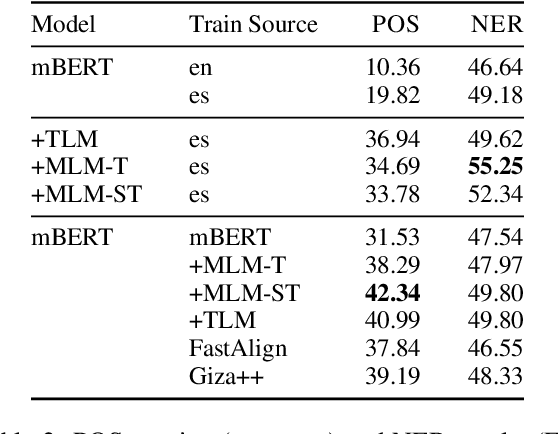
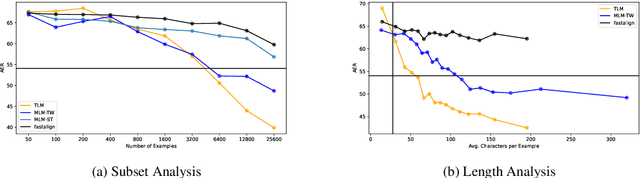
Large multilingual models have inspired a new class of word alignment methods, which work well for the model's pretraining languages. However, the languages most in need of automatic alignment are low-resource and, thus, not typically included in the pretraining data. In this work, we ask: How do modern aligners perform on unseen languages, and are they better than traditional methods? We contribute gold-standard alignments for Bribri--Spanish, Guarani--Spanish, Quechua--Spanish, and Shipibo-Konibo--Spanish. With these, we evaluate state-of-the-art aligners with and without model adaptation to the target language. Finally, we also evaluate the resulting alignments extrinsically through two downstream tasks: named entity recognition and part-of-speech tagging. We find that although transformer-based methods generally outperform traditional models, the two classes of approach remain competitive with each other.
Recurrent Neural Network Transducer for Audio-Visual Speech Recognition
Nov 08, 2019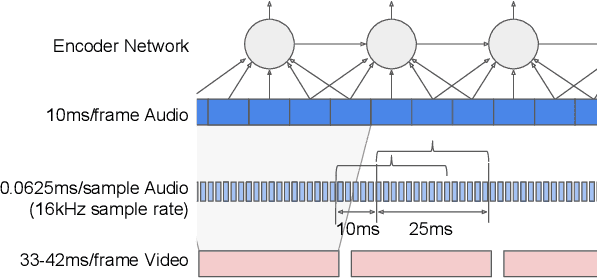
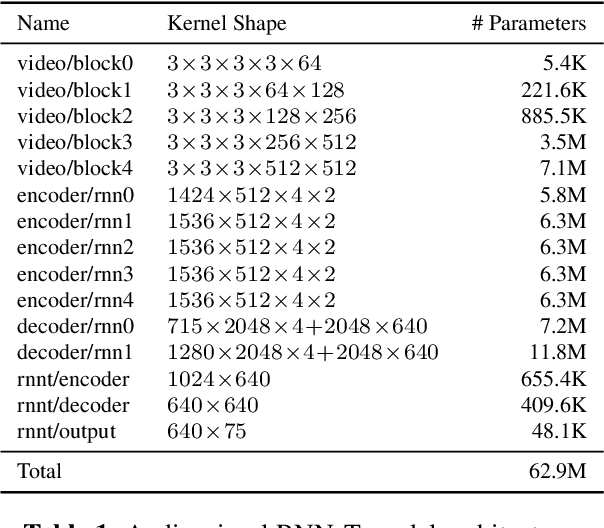
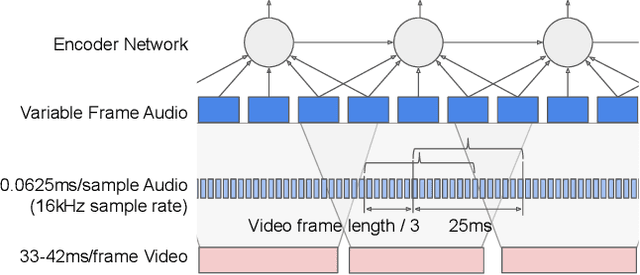

This work presents a large-scale audio-visual speech recognition system based on a recurrent neural network transducer (RNN-T) architecture. To support the development of such a system, we built a large audio-visual (A/V) dataset of segmented utterances extracted from YouTube public videos, leading to 31k hours of audio-visual training content. The performance of an audio-only, visual-only, and audio-visual system are compared on two large-vocabulary test sets: a set of utterance segments from public YouTube videos called YTDEV18 and the publicly available LRS3-TED set. To highlight the contribution of the visual modality, we also evaluated the performance of our system on the YTDEV18 set artificially corrupted with background noise and overlapping speech. To the best of our knowledge, our system significantly improves the state-of-the-art on the LRS3-TED set.
End-to-end label uncertainty modeling for speech emotion recognition using Bayesian neural networks
Oct 07, 2021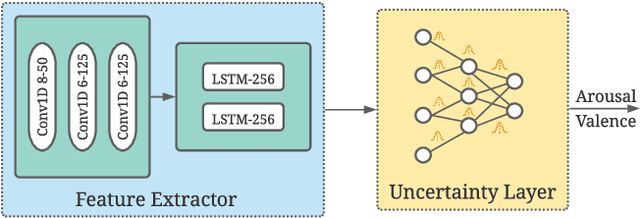
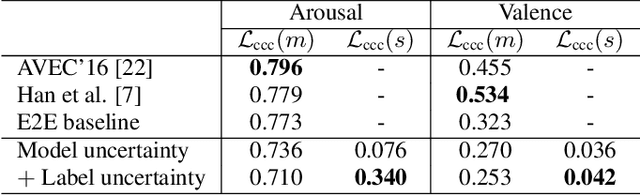

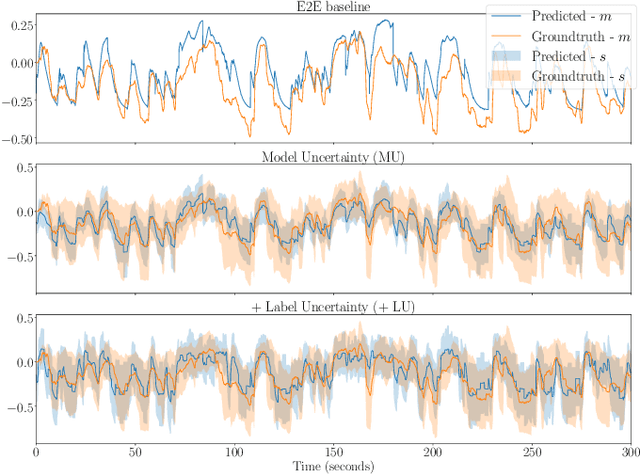
Emotions are subjective constructs. Recent end-to-end speech emotion recognition systems are typically agnostic to the subjective nature of emotions, despite their state-of-the-art performances. In this work, we introduce an end-to-end Bayesian neural network architecture to capture the inherent subjectivity in emotions. To the best of our knowledge, this work is the first to use Bayesian neural networks for speech emotion recognition. At training, the network learns a distribution of weights to capture the inherent uncertainty related to subjective emotion annotations. For this, we introduce a loss term which enables the model to be explicitly trained on a distribution of emotion annotations, rather than training them exclusively on mean or gold-standard labels. We evaluate the proposed approach on the AVEC'16 emotion recognition dataset. Qualitative and quantitative analysis of the results reveal that the proposed model can aptly capture the distribution of subjective emotion annotations with a compromise between mean and standard deviation estimations.
VoxSRC 2022: The Fourth VoxCeleb Speaker Recognition Challenge
Mar 06, 2023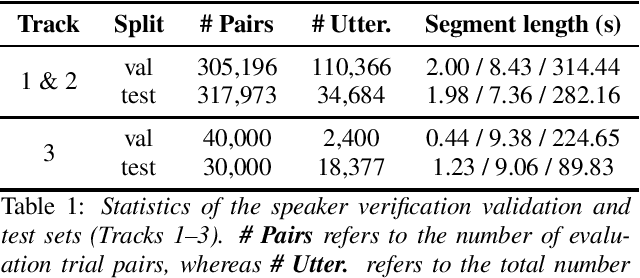
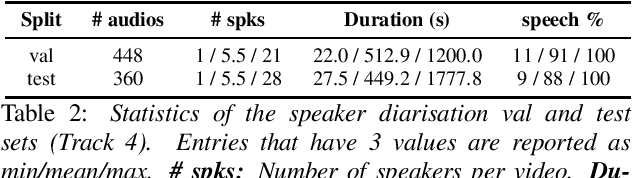
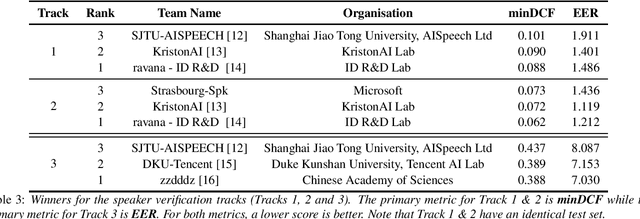

This paper summarises the findings from the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22), which was held in conjunction with INTERSPEECH 2022. The goal of this challenge was to evaluate how well state-of-the-art speaker recognition systems can diarise and recognise speakers from speech obtained "in the wild". The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a public challenge and hybrid workshop held at INTERSPEECH 2022. We describe the four tracks of our challenge along with the baselines, methods, and results. We conclude with a discussion on the new domain-transfer focus of VoxSRC-22, and on the progression of the challenge from the previous three editions.