 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Predictive Modelling for Groundwater Salinization in Israel
Feb 07, 2026Increasing salinity and contamination of groundwater is a serious issue in many parts of the world, causing degradation of water resources. The aim of this work is to form a comprehensive understanding of groundwater salinization underlying causal factors and identify important meteorological, geological and anthropogenic drivers of salinity. We have integrated different datasets of potential covariates, to create a robust framework for machine learning based predictive models including Random Forest (RF), XGBoost, Neural network, Long Short-Term Memory (LSTM), convolution neural network (CNN) and linear regression (LR), of groundwater salinity. Additionally, Recursive Feature Elimination (RFE) followed by Global sensitivity analysis (GSA) and Explainable AI (XAI) based SHapley Additive exPlanations (SHAP) were used to estimate the importance scores and find insights into the drivers of salinization. We also did causality analysis via Double machine learning using various predictive models. From these analyses, key meteorological (Precipitation, Temperature), geological (Distance from river, Distance to saline body, TWI, Shoreline distance), and anthropogenic (Area of agriculture field, Treated Wastewater) covariates are identified to be influential drivers of groundwater salinity across Israel. XAI analysis also identified Treated Wastewater (TWW) as an essential anthropogenic driver of salinity, its significance being context-dependent but critical in vulnerable hydro-climatic environment. Our approach provides deeper insight into global salinization mechanisms at country scale, reducing AI model uncertainty and highlighting the need for tailored strategies to address salinity.
Towards scalable efficient on-device ASR with transfer learning
Jul 23, 2024



Multilingual pretraining for transfer learning significantly boosts the robustness of low-resource monolingual ASR models. This study systematically investigates three main aspects: (a) the impact of transfer learning on model performance during initial training or fine-tuning, (b) the influence of transfer learning across dataset domains and languages, and (c) the effect on rare-word recognition compared to non-rare words. Our finding suggests that RNNT-loss pretraining, followed by monolingual fine-tuning with Minimum Word Error Rate (MinWER) loss, consistently reduces Word Error Rates (WER) across languages like Italian and French. WER Reductions (WERR) reach 36.2% and 42.8% compared to monolingual baselines for MLS and in-house datasets. Out-of-domain pretraining leads to 28% higher WERR than in-domain pretraining. Both rare and non-rare words benefit, with rare words showing greater improvements with out-of-domain pretraining, and non-rare words with in-domain pretraining.
Improving Data Driven Inverse Text Normalization using Data Augmentation
Jul 20, 2022
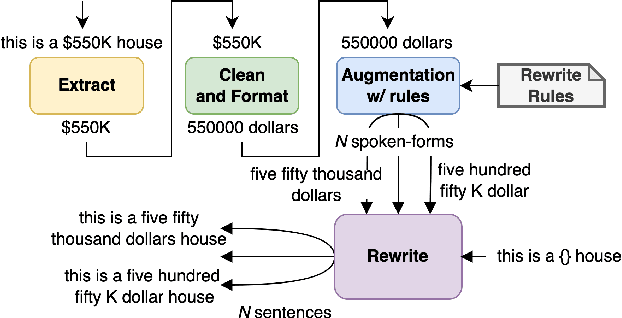

Inverse text normalization (ITN) is used to convert the spoken form output of an automatic speech recognition (ASR) system to a written form. Traditional handcrafted ITN rules can be complex to transcribe and maintain. Meanwhile neural modeling approaches require quality large-scale spoken-written pair examples in the same or similar domain as the ASR system (in-domain data), to train. Both these approaches require costly and complex annotations. In this paper, we present a data augmentation technique that effectively generates rich spoken-written numeric pairs from out-of-domain textual data with minimal human annotation. We empirically demonstrate that ITN model trained using our data augmentation technique consistently outperform ITN model trained using only in-domain data across all numeric surfaces like cardinal, currency, and fraction, by an overall accuracy of 14.44%.
Silent Speech and Emotion Recognition from Vocal Tract Shape Dynamics in Real-Time MRI
Jun 16, 2021
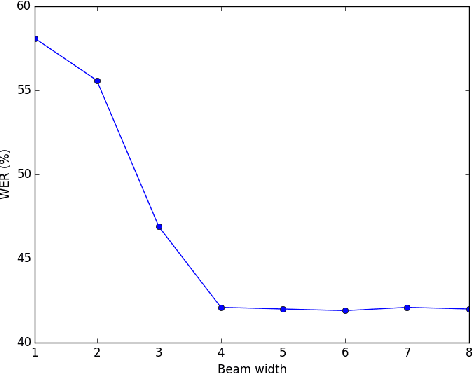
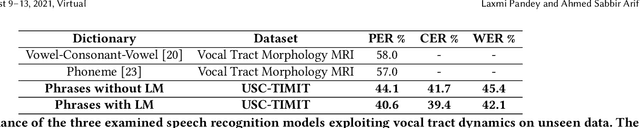
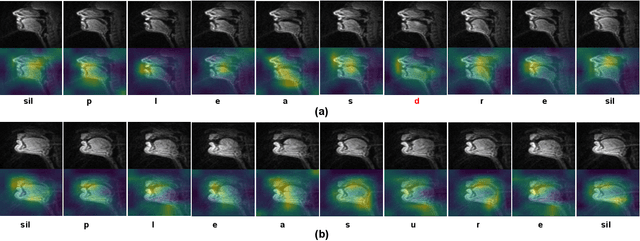
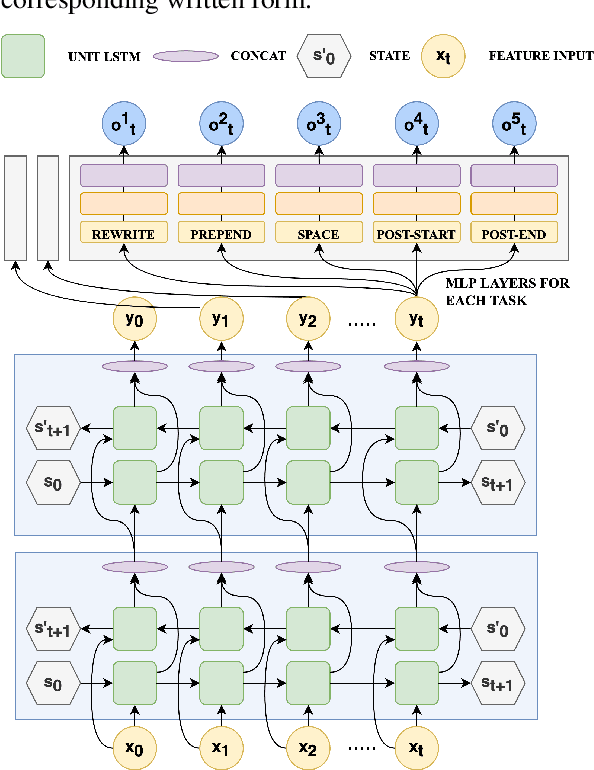
Speech sounds of spoken language are obtained by varying configuration of the articulators surrounding the vocal tract. They contain abundant information that can be utilized to better understand the underlying mechanism of human speech production. We propose a novel deep neural network-based learning framework that understands acoustic information in the variable-length sequence of vocal tract shaping during speech production, captured by real-time magnetic resonance imaging (rtMRI), and translate it into text. The proposed framework comprises of spatiotemporal convolutions, a recurrent network, and the connectionist temporal classification loss, trained entirely end-to-end. On the USC-TIMIT corpus, the model achieved a 40.6% PER at sentence-level, much better compared to the existing models. To the best of our knowledge, this is the first study that demonstrates the recognition of entire spoken sentence based on an individual's articulatory motions captured by rtMRI video. We also performed an analysis of variations in the geometry of articulation in each sub-regions of the vocal tract (i.e., pharyngeal, velar and dorsal, hard palate, labial constriction region) with respect to different emotions and genders. Results suggest that each sub-regions distortion is affected by both emotion and gender.