 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-point quantization aware training for on-device keyword-spotting
Mar 04, 2023



Fixed-point (FXP) inference has proven suitable for embedded devices with limited computational resources, and yet model training is continually performed in floating-point (FLP). FXP training has not been fully explored and the non-trivial conversion from FLP to FXP presents unavoidable performance drop. We propose a novel method to train and obtain FXP convolutional keyword-spotting (KWS) models. We combine our methodology with two quantization-aware-training (QAT) techniques - squashed weight distribution and absolute cosine regularization for model parameters, and propose techniques for extending QAT over transient variables, otherwise neglected by previous paradigms. Experimental results on the Google Speech Commands v2 dataset show that we can reduce model precision up to 4-bit with no loss in accuracy. Furthermore, on an in-house KWS dataset, we show that our 8-bit FXP-QAT models have a 4-6% improvement in relative false discovery rate at fixed false reject rate compared to full precision FLP models. During inference we argue that FXP-QAT eliminates q-format normalization and enables the use of low-bit accumulators while maximizing SIMD throughput to reduce user perceived latency. We demonstrate that we can reduce execution time by 68% without compromising KWS model's predictive performance or requiring model architectural changes. Our work provides novel findings that aid future research in this area and enable accurate and efficient models.
* 5 pages, 3 figures, 4 tables
Conversational Text-to-SQL: An Odyssey into State-of-the-Art and Challenges Ahead
Feb 21, 2023



Conversational, multi-turn, text-to-SQL (CoSQL) tasks map natural language utterances in a dialogue to SQL queries. State-of-the-art (SOTA) systems use large, pre-trained and finetuned language models, such as the T5-family, in conjunction with constrained decoding. With multi-tasking (MT) over coherent tasks with discrete prompts during training, we improve over specialized text-to-SQL T5-family models. Based on Oracle analyses over n-best hypotheses, we apply a query plan model and a schema linking algorithm as rerankers. Combining MT and reranking, our results using T5-3B show absolute accuracy improvements of 1.0% in exact match and 3.4% in execution match over a SOTA baseline on CoSQL. While these gains consistently manifest at turn level, context dependent turns are considerably harder. We conduct studies to tease apart errors attributable to domain and compositional generalization, with the latter remaining a challenge for multi-turn conversations, especially in generating SQL with unseen parse trees.
N-Best Hypotheses Reranking for Text-To-SQL Systems
Oct 19, 2022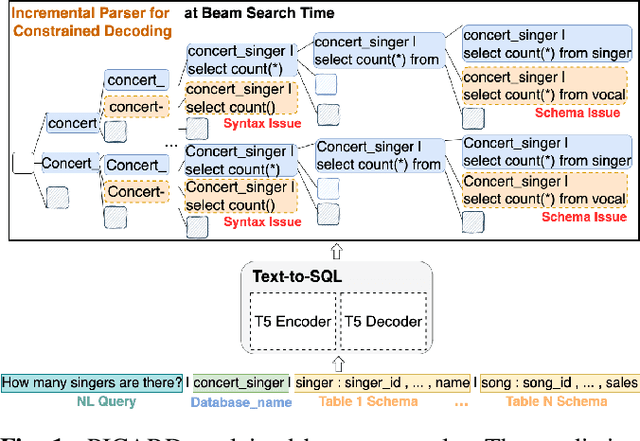
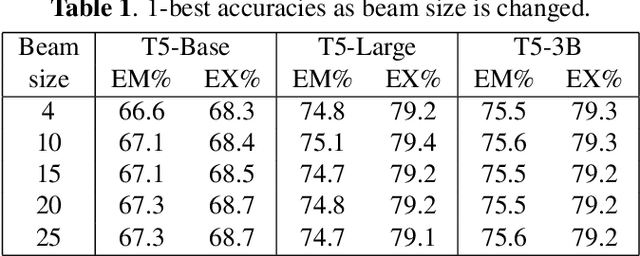
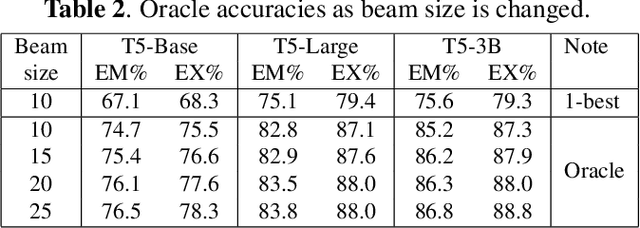
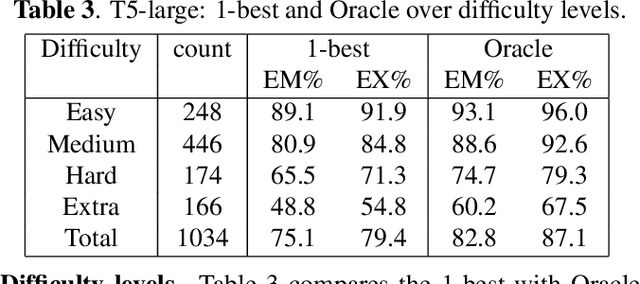
Text-to-SQL task maps natural language utterances to structured queries that can be issued to a database. State-of-the-art (SOTA) systems rely on finetuning large, pre-trained language models in conjunction with constrained decoding applying a SQL parser. On the well established Spider dataset, we begin with Oracle studies: specifically, choosing an Oracle hypothesis from a SOTA model's 10-best list, yields a $7.7\%$ absolute improvement in both exact match (EM) and execution (EX) accuracy, showing significant potential improvements with reranking. Identifying coherence and correctness as reranking approaches, we design a model generating a query plan and propose a heuristic schema linking algorithm. Combining both approaches, with T5-Large, we obtain a consistent $1\% $ improvement in EM accuracy, and a $~2.5\%$ improvement in EX, establishing a new SOTA for this task. Our comprehensive error studies on DEV data show the underlying difficulty in making progress on this task.
Sub 8-Bit Quantization of Streaming Keyword Spotting Models for Embedded Chipsets
Jul 13, 2022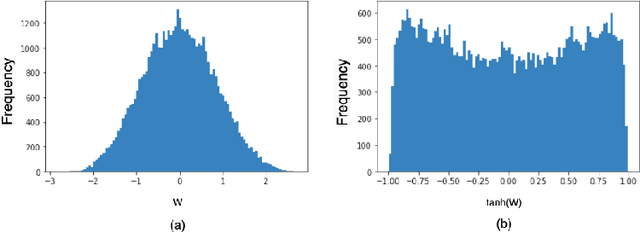
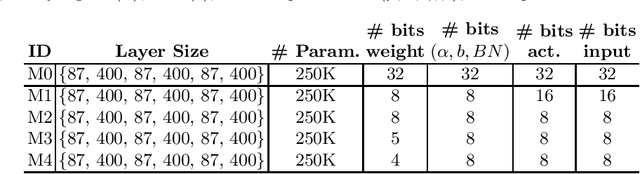
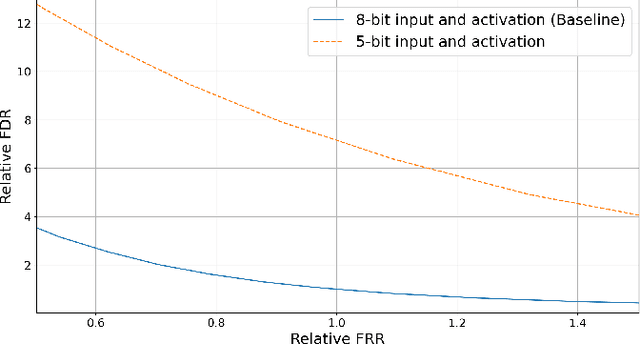
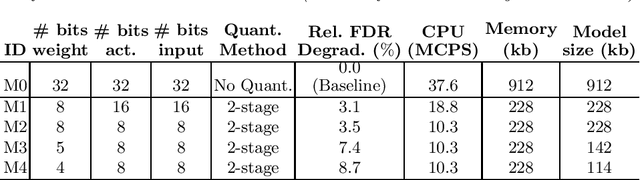
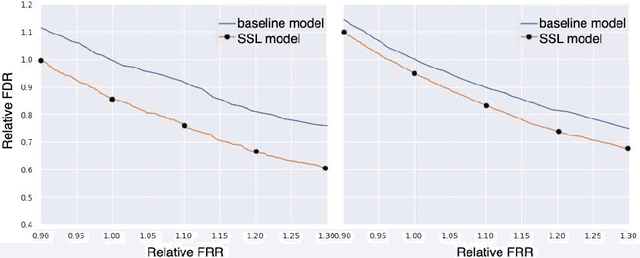
We propose a novel 2-stage sub 8-bit quantization aware training algorithm for all components of a 250K parameter feedforward, streaming, state-free keyword spotting model. For the 1st-stage, we adapt a recently proposed quantization technique using a non-linear transformation with tanh(.) on dense layer weights. In the 2nd-stage, we use linear quantization methods on the rest of the network, including other parameters (bias, gain, batchnorm), inputs, and activations. We conduct large scale experiments, training on 26,000 hours of de-identified production, far-field and near-field audio data (evaluating on 4,000 hours of data). We organize our results in two embedded chipset settings: a) with commodity ARM NEON instruction set and 8-bit containers, we present accuracy, CPU, and memory results using sub 8-bit weights (4, 5, 8-bit) and 8-bit quantization of rest of the network; b) with off-the-shelf neural network accelerators, for a range of weight bit widths (1 and 5-bit), while presenting accuracy results, we project reduction in memory utilization. In both configurations, our results show that the proposed algorithm can achieve: a) parity with a full floating point model's operating point on a detection error tradeoff (DET) curve in terms of false detection rate (FDR) at false rejection rate (FRR); b) significant reduction in compute and memory, yielding up to 3 times improvement in CPU consumption and more than 4 times improvement in memory consumption.
Wakeword Detection under Distribution Shifts
Jul 13, 2022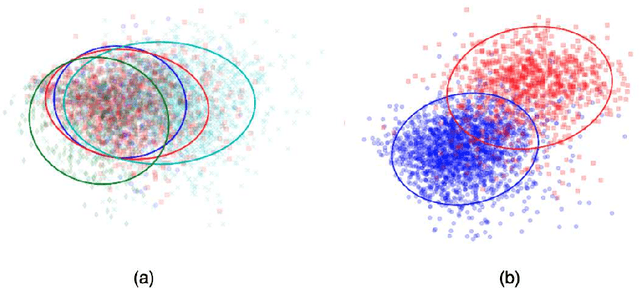
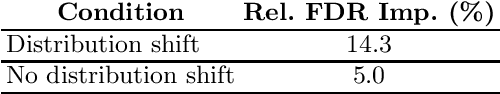
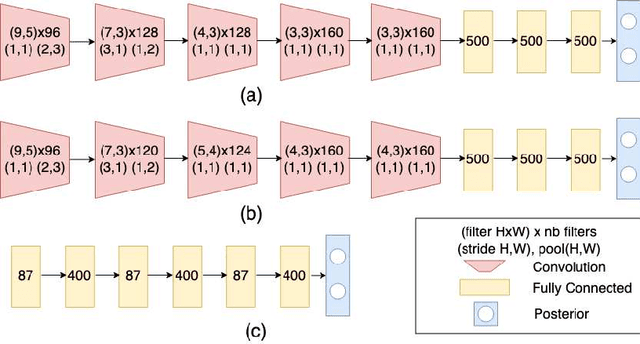
We propose a novel approach for semi-supervised learning (SSL) designed to overcome distribution shifts between training and real-world data arising in the keyword spotting (KWS) task. Shifts from training data distribution are a key challenge for real-world KWS tasks: when a new model is deployed on device, the gating of the accepted data undergoes a shift in distribution, making the problem of timely updates via subsequent deployments hard. Despite the shift, we assume that the marginal distributions on labels do not change. We utilize a modified teacher/student training framework, where labeled training data is augmented with unlabeled data. Note that the teacher does not have access to the new distribution as well. To train effectively with a mix of human and teacher labeled data, we develop a teacher labeling strategy based on confidence heuristics to reduce entropy on the label distribution from the teacher model; the data is then sampled to match the marginal distribution on the labels. Large scale experimental results show that a convolutional neural network (CNN) trained on far-field audio, and evaluated on far-field audio drawn from a different distribution, obtains a 14.3% relative improvement in false discovery rate (FDR) at equal false reject rate (FRR), while yielding a 5% improvement in FDR under no distribution shift. Under a more severe distribution shift from far-field to near-field audio with a smaller fully connected network (FCN) our approach achieves a 52% relative improvement in FDR at equal FRR, while yielding a 20% relative improvement in FDR on the original distribution.
Exploiting Large-scale Teacher-Student Training for On-device Acoustic Models
Jun 11, 2021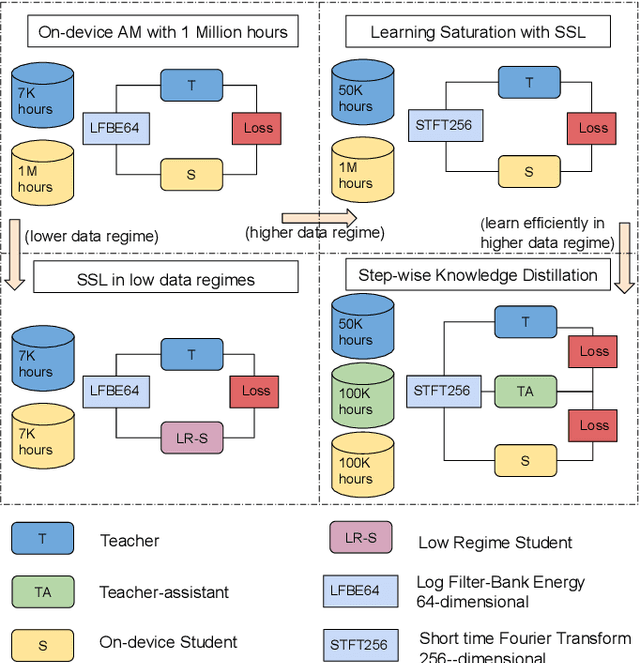
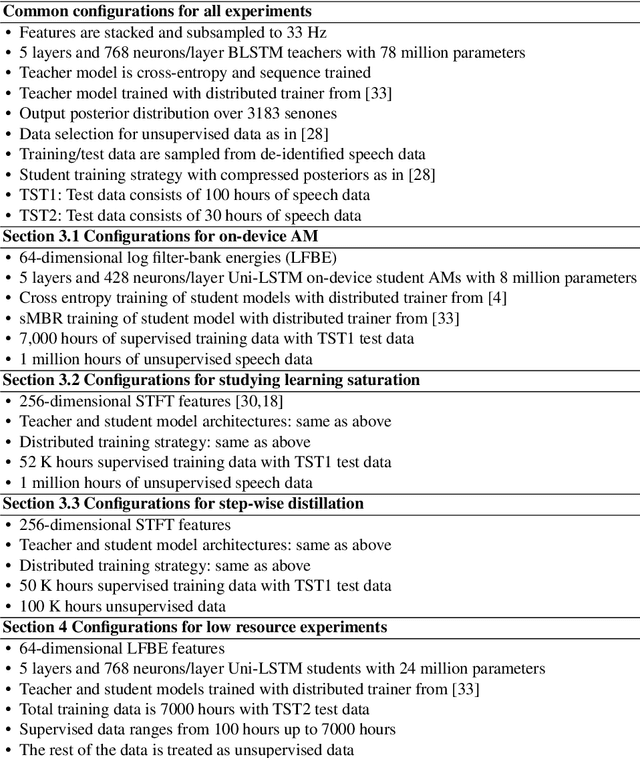
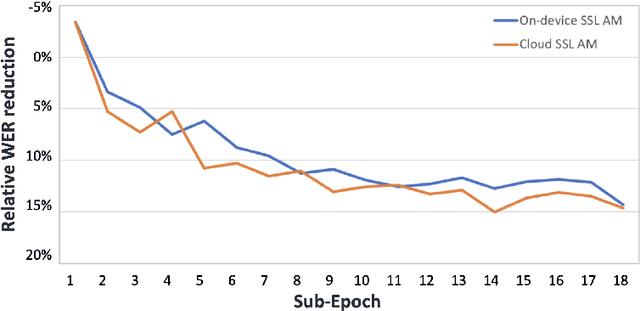
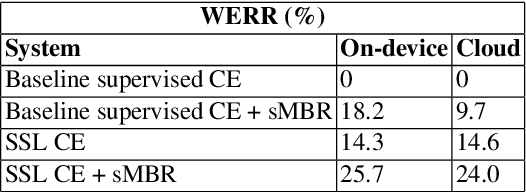
We present results from Alexa speech teams on semi-supervised learning (SSL) of acoustic models (AM) with experiments spanning over 3000 hours of GPU time, making our study one of the largest of its kind. We discuss SSL for AMs in a small footprint setting, showing that a smaller capacity model trained with 1 million hours of unsupervised data can outperform a baseline supervised system by 14.3% word error rate reduction (WERR). When increasing the supervised data to seven-fold, our gains diminish to 7.1% WERR; to improve SSL efficiency at larger supervised data regimes, we employ a step-wise distillation into a smaller model, obtaining a WERR of 14.4%. We then switch to SSL using larger student models in low data regimes; while learning efficiency with unsupervised data is higher, student models may outperform teacher models in such a setting. We develop a theoretical sketch to explain this behavior.
Realizing Petabyte Scale Acoustic Modeling
Apr 24, 2019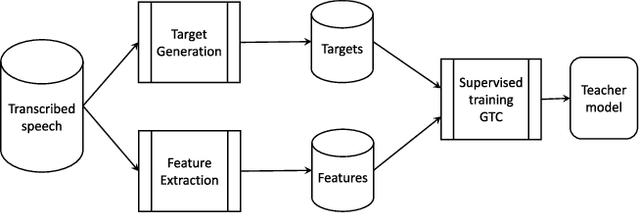
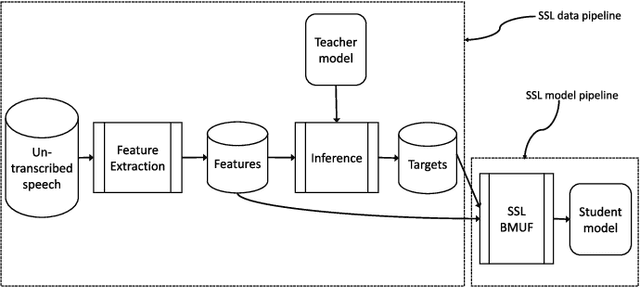
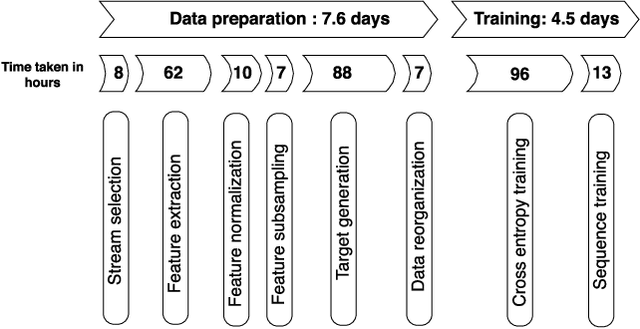
Large scale machine learning (ML) systems such as the Alexa automatic speech recognition (ASR) system continue to improve with increasing amounts of manually transcribed training data. Instead of scaling manual transcription to impractical levels, we utilize semi-supervised learning (SSL) to learn acoustic models (AM) from the vast firehose of untranscribed audio data. Learning an AM from 1 Million hours of audio presents unique ML and system design challenges. We present the design and evaluation of a highly scalable and resource efficient SSL system for AM. Employing the student/teacher learning paradigm, we focus on the student learning subsystem: a scalable and robust data pipeline that generates features and targets from raw audio, and an efficient model pipeline, including the distributed trainer, that builds a student model. Our evaluations show that, even without extensive hyper-parameter tuning, we obtain relative accuracy improvements in the 10 to 20$\%$ range, with higher gains in noisier conditions. The end-to-end processing time of this SSL system was 12 days, and several components in this system can trivially scale linearly with more compute resources.
Lessons from Building Acoustic Models with a Million Hours of Speech
Apr 02, 2019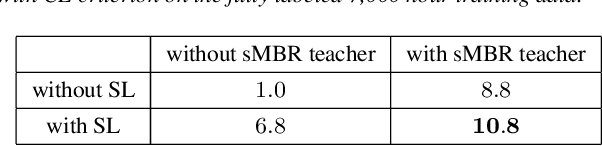
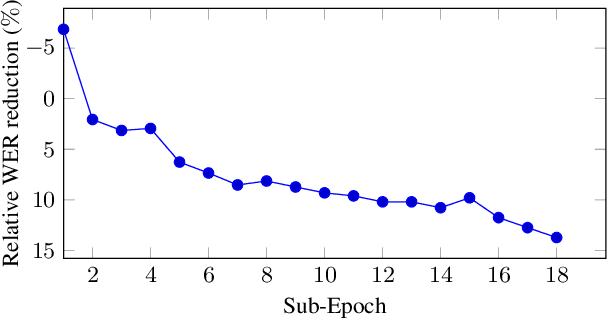
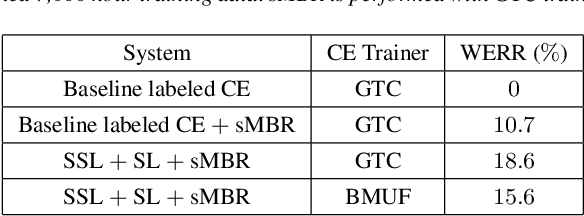
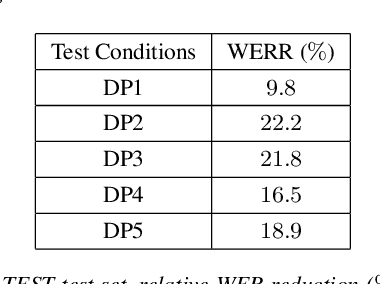
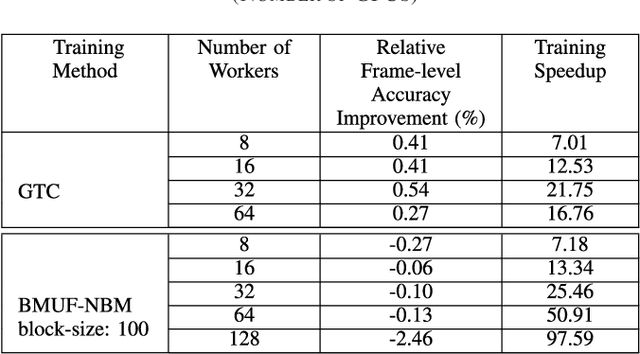
This is a report of our lessons learned building acoustic models from 1 Million hours of unlabeled speech, while labeled speech is restricted to 7,000 hours. We employ student/teacher training on unlabeled data, helping scale out target generation in comparison to confidence model based methods, which require a decoder and a confidence model. To optimize storage and to parallelize target generation, we store high valued logits from the teacher model. Introducing the notion of scheduled learning, we interleave learning on unlabeled and labeled data. To scale distributed training across a large number of GPUs, we use BMUF with 64 GPUs, while performing sequence training only on labeled data with gradient threshold compression SGD using 16 GPUs. Our experiments show that extremely large amounts of data are indeed useful; with little hyper-parameter tuning, we obtain relative WER improvements in the 10 to 20% range, with higher gains in noisier conditions.
Improving noise robustness of automatic speech recognition via parallel data and teacher-student learning
Jan 11, 2019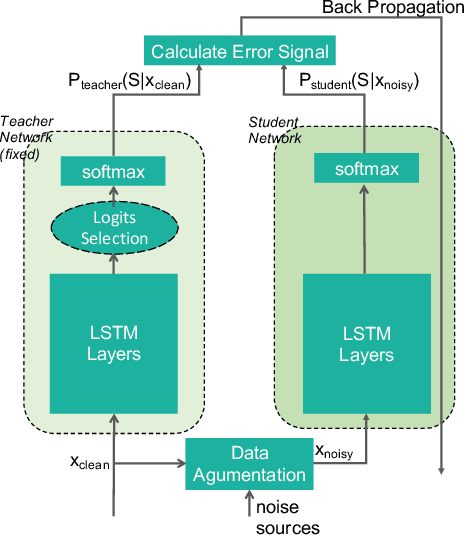
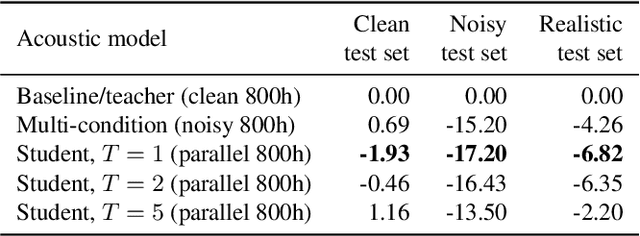
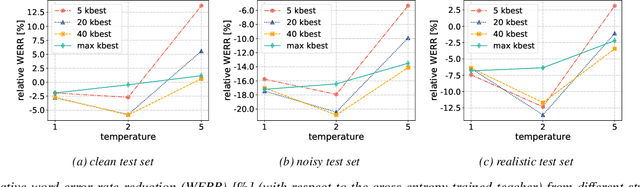
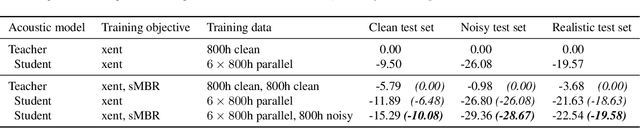
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the k highest values to prevent wrong emphasis of knowledge from the teacher and to reduce bandwidth needed for transferring data. We incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained models apart from cross entropy trained ones. The best sequence trained student model yields relative word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively comparing to a sequence trained teacher.