 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Self-Learning Framework For Interactive Spoken Dialog Systems
Sep 16, 2024



Dialog systems, such as voice assistants, are expected to engage with users in complex, evolving conversations. Unfortunately, traditional automatic speech recognition (ASR) systems deployed in such applications are usually trained to recognize each turn independently and lack the ability to adapt to the conversational context or incorporate user feedback. In this work, we introduce a general framework for ASR in dialog systems that can go beyond learning from single-turn utterances and learn over time how to adapt to both explicit supervision and implicit user feedback present in multi-turn conversations. We accomplish that by leveraging advances in student-teacher learning and context-aware dialog processing, and designing contrastive self-supervision approaches with Ohm, a new online hard-negative mining approach. We show that leveraging our new framework compared to traditional training leads to relative WER reductions of close to 10% in real-world dialog systems, and up to 26% on public synthetic data.
Task Oriented Dialogue as a Catalyst for Self-Supervised Automatic Speech Recognition
Jan 04, 2024



While word error rates of automatic speech recognition (ASR) systems have consistently fallen, natural language understanding (NLU) applications built on top of ASR systems still attribute significant numbers of failures to low-quality speech recognition results. Existing assistant systems collect large numbers of these unsuccessful interactions, but these systems usually fail to learn from these interactions, even in an offline fashion. In this work, we introduce CLC: Contrastive Learning for Conversations, a family of methods for contrastive fine-tuning of models in a self-supervised fashion, making use of easily detectable artifacts in unsuccessful conversations with assistants. We demonstrate that our CLC family of approaches can improve the performance of ASR models on OD3, a new public large-scale semi-synthetic meta-dataset of audio task-oriented dialogues, by up to 19.2%. These gains transfer to real-world systems as well, where we show that CLC can help to improve performance by up to 6.7% over baselines. We make OD3 publicly available at https://github.com/amazon-science/amazon-od3 .
Using External Off-Policy Speech-To-Text Mappings in Contextual End-To-End Automated Speech Recognition
Jan 06, 2023Despite improvements to the generalization performance of automated speech recognition (ASR) models, specializing ASR models for downstream tasks remains a challenging task, primarily due to reduced data availability (necessitating increased data collection), and rapidly shifting data distributions (requiring more frequent model fine-tuning). In this work, we investigate the potential of leveraging external knowledge, particularly through off-policy key-value stores generated with text-to-speech methods, to allow for flexible post-training adaptation to new data distributions. In our approach, audio embeddings captured from text-to-speech, along with semantic text embeddings, are used to bias ASR via an approximate k-nearest-neighbor (KNN) based attentive fusion step. Our experiments on LibiriSpeech and in-house voice assistant/search datasets show that the proposed approach can reduce domain adaptation time by up to 1K GPU-hours while providing up to 3% WER improvement compared to a fine-tuning baseline, suggesting a promising approach for adapting production ASR systems in challenging zero and few-shot scenarios.
Multi-Modal Pre-Training for Automated Speech Recognition
Oct 12, 2021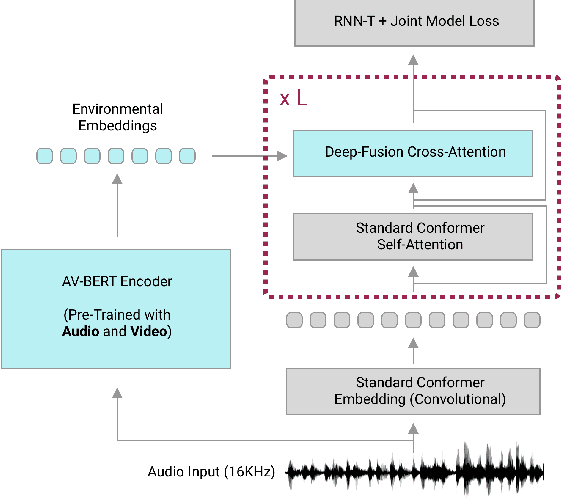
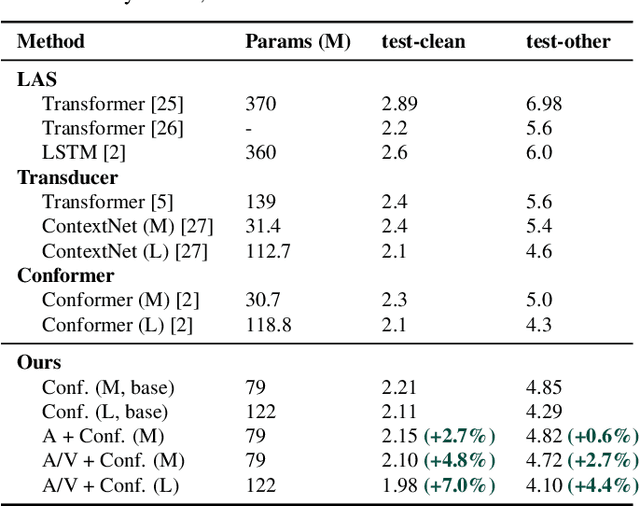
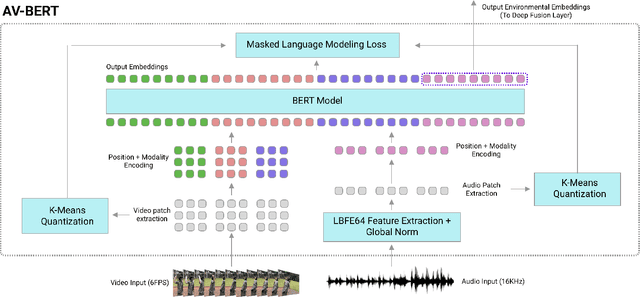
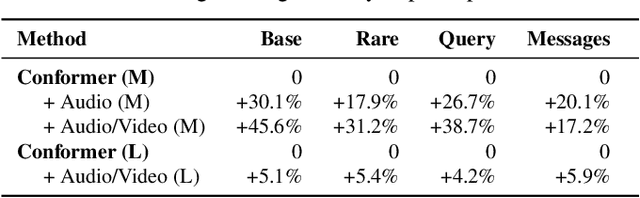
Traditionally, research in automated speech recognition has focused on local-first encoding of audio representations to predict the spoken phonemes in an utterance. Unfortunately, approaches relying on such hyper-local information tend to be vulnerable to both local-level corruption (such as audio-frame drops, or loud noises) and global-level noise (such as environmental noise, or background noise) that has not been seen during training. In this work, we introduce a novel approach which leverages a self-supervised learning technique based on masked language modeling to compute a global, multi-modal encoding of the environment in which the utterance occurs. We then use a new deep-fusion framework to integrate this global context into a traditional ASR method, and demonstrate that the resulting method can outperform baseline methods by up to 7% on Librispeech; gains on internal datasets range from 6% (on larger models) to 45% (on smaller models).
Low-Resource Adaptation of Open-Domain Generative Chatbots
Aug 13, 2021
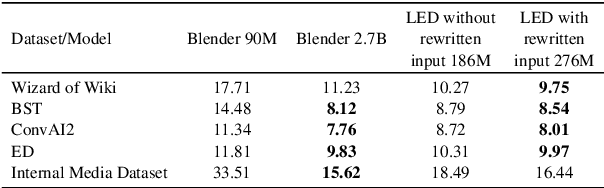
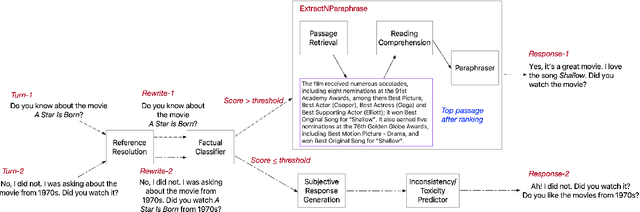
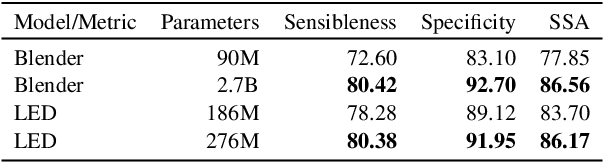
Recent work building open-domain chatbots has demonstrated that increasing model size improves performance. On the other hand, latency and connectivity considerations dictate the move of digital assistants on the device. Giving a digital assistant like Siri, Alexa, or Google Assistant the ability to discuss just about anything leads to the need for reducing the chatbot model size such that it fits on the user's device. We demonstrate that low parameter models can simultaneously retain their general knowledge conversational abilities while improving in a specific domain. Additionally, we propose a generic framework that accounts for variety in question types, tracks reference throughout multi-turn conversations, and removes inconsistent and potentially toxic responses. Our framework seamlessly transitions between chatting and performing transactional tasks, which will ultimately make interactions with digital assistants more human-like. We evaluate our framework on 1 internal and 4 public benchmark datasets using both automatic (Perplexity) and human (SSA - Sensibleness and Specificity Average) evaluation metrics and establish comparable performance while reducing model parameters by 90%.
DiPCo -- Dinner Party Corpus
Sep 30, 2019
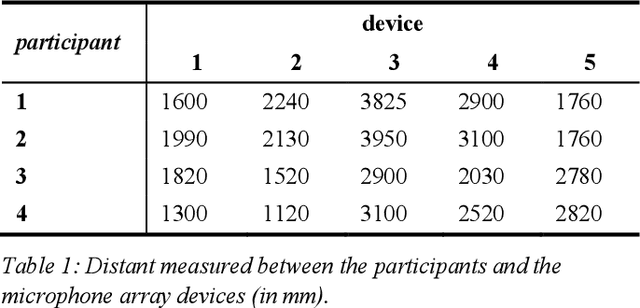
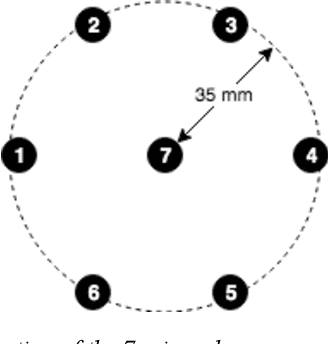

We present a speech data corpus that simulates a "dinner party" scenario taking place in an everyday home environment. The corpus was created by recording multiple groups of four Amazon employee volunteers having a natural conversation in English around a dining table. The participants were recorded by a single-channel close-talk microphone and by five far-field 7-microphone array devices positioned at different locations in the recording room. The dataset contains the audio recordings and human labeled transcripts of a total of 10 sessions with a duration between 15 and 45 minutes. The corpus was created to advance in the field of noise robust and distant speech processing and is intended to serve as a public research and benchmarking data set.
End-to-end Anchored Speech Recognition
Feb 06, 2019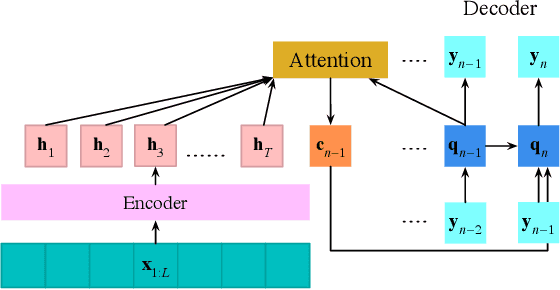
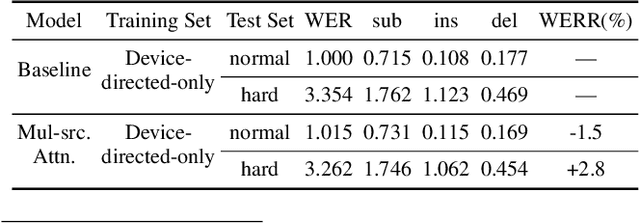

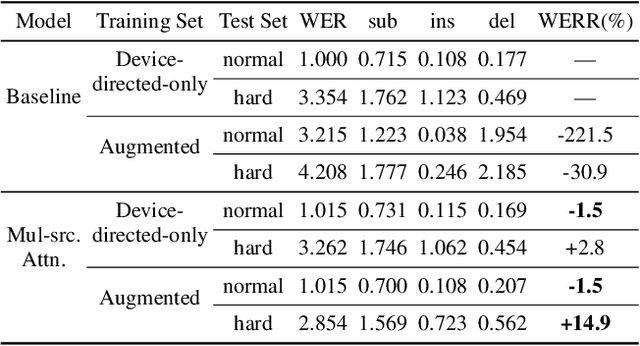
Voice-controlled house-hold devices, like Amazon Echo or Google Home, face the problem of performing speech recognition of device-directed speech in the presence of interfering background speech, i.e., background noise and interfering speech from another person or media device in proximity need to be ignored. We propose two end-to-end models to tackle this problem with information extracted from the "anchored segment". The anchored segment refers to the wake-up word part of an audio stream, which contains valuable speaker information that can be used to suppress interfering speech and background noise. The first method is called "Multi-source Attention" where the attention mechanism takes both the speaker information and decoder state into consideration. The second method directly learns a frame-level mask on top of the encoder output. We also explore a multi-task learning setup where we use the ground truth of the mask to guide the learner. Given that audio data with interfering speech is rare in our training data set, we also propose a way to synthesize "noisy" speech from "clean" speech to mitigate the mismatch between training and test data. Our proposed methods show up to 15% relative reduction in WER for Amazon Alexa live data with interfering background speech without significantly degrading on clean speech.
Improving noise robustness of automatic speech recognition via parallel data and teacher-student learning
Jan 11, 2019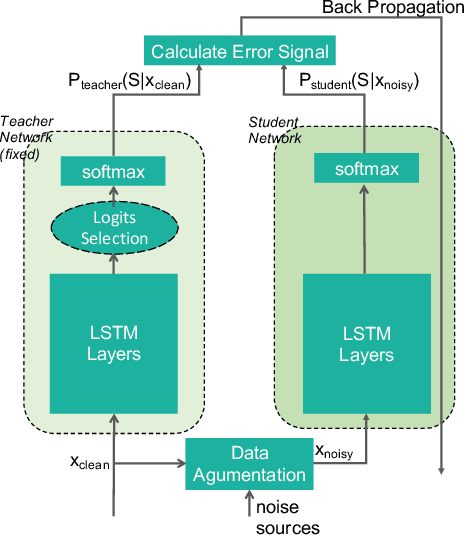
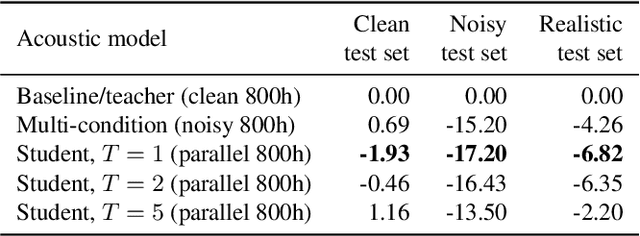
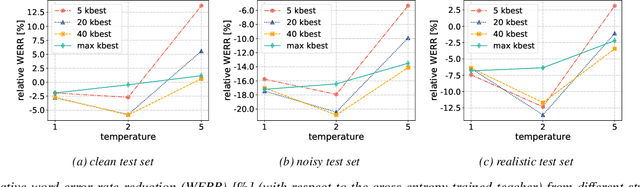
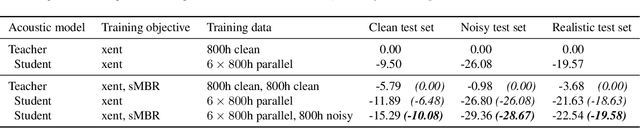
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the k highest values to prevent wrong emphasis of knowledge from the teacher and to reduce bandwidth needed for transferring data. We incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained models apart from cross entropy trained ones. The best sequence trained student model yields relative word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively comparing to a sequence trained teacher.
LSTM-based Whisper Detection
Sep 20, 2018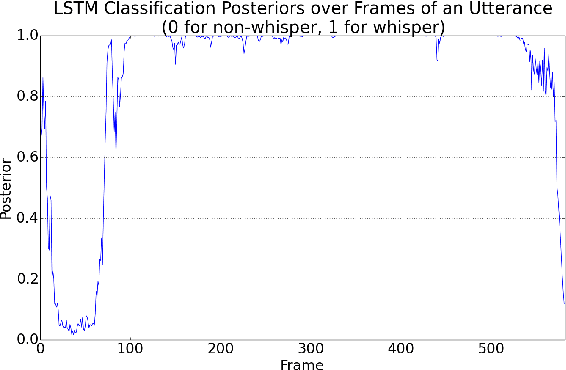

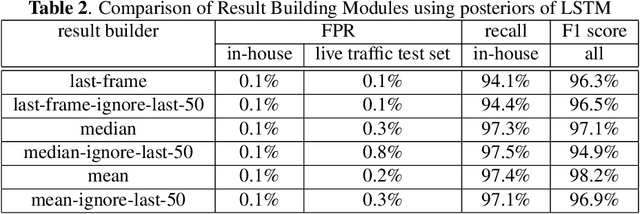
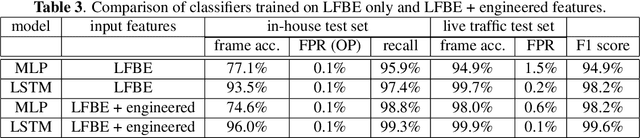
This article presents a whisper speech detector in the far-field domain. The proposed system consists of a long-short term memory (LSTM) neural network trained on log-filterbank energy (LFBE) acoustic features. This model is trained and evaluated on recordings of human interactions with voice-controlled, far-field devices in whisper and normal phonation modes. We compare multiple inference approaches for utterance-level classification by examining trajectories of the LSTM posteriors. In addition, we engineer a set of features based on the signal characteristics inherent to whisper speech, and evaluate their effectiveness in further separating whisper from normal speech. A benchmarking of these features using multilayer perceptrons (MLP) and LSTMs suggests that the proposed features, in combination with LFBE features, can help us further improve our classifiers. We prove that, with enough data, the LSTM model is indeed as capable of learning whisper characteristics from LFBE features alone com- pared to a simpler MLP model that uses both LFBE and features engineered for separating whisper and normal speech. In addition, we prove that the LSTM classifiers accuracy can be further improved with the incorporation of the proposed engineered features.
Device-directed Utterance Detection
Aug 07, 2018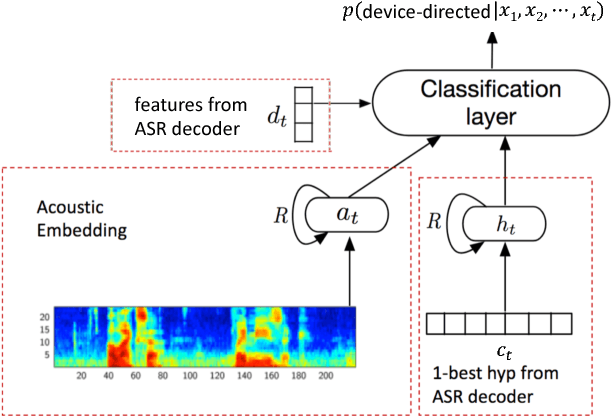
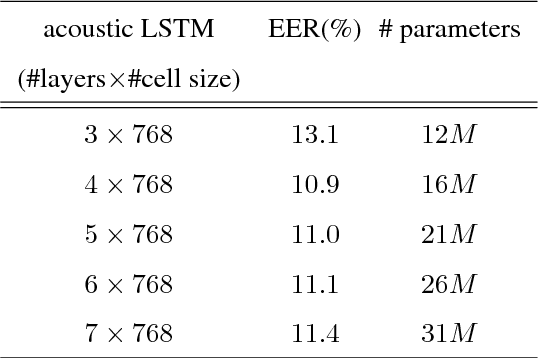
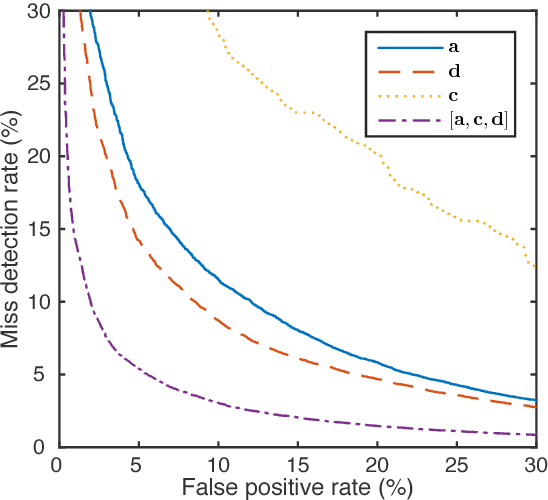
In this work, we propose a classifier for distinguishing device-directed queries from background speech in the context of interactions with voice assistants. Applications include rejection of false wake-ups or unintended interactions as well as enabling wake-word free follow-up queries. Consider the example interaction: $"Computer,~play~music", "Computer,~reduce~the~volume"$. In this interaction, the user needs to repeat the wake-word ($Computer$) for the second query. To allow for more natural interactions, the device could immediately re-enter listening state after the first query (without wake-word repetition) and accept or reject a potential follow-up as device-directed or background speech. The proposed model consists of two long short-term memory (LSTM) neural networks trained on acoustic features and automatic speech recognition (ASR) 1-best hypotheses, respectively. A feed-forward deep neural network (DNN) is then trained to combine the acoustic and 1-best embeddings, derived from the LSTMs, with features from the ASR decoder. Experimental results show that ASR decoder, acoustic embeddings, and 1-best embeddings yield an equal-error-rate (EER) of $9.3~\%$, $10.9~\%$ and $20.1~\%$, respectively. Combination of the features resulted in a $44~\%$ relative improvement and a final EER of $5.2~\%$.