 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Readability for Automatic Speech Recognition Transcription
Paper and Code

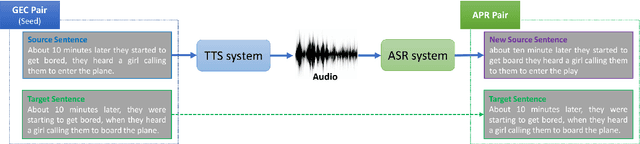
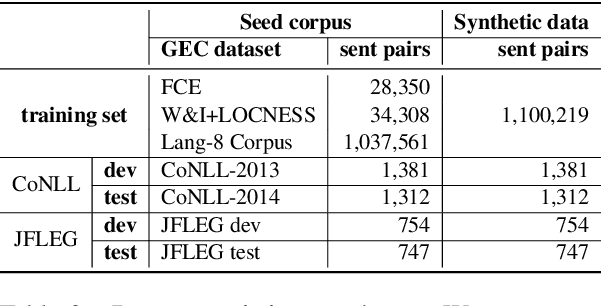
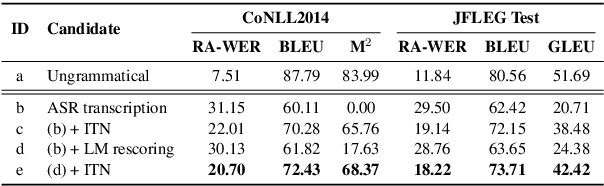
Modern Automatic Speech Recognition (ASR) systems can achieve high performance in terms of recognition accuracy. However, a perfectly accurate transcript still can be challenging to read due to grammatical errors, disfluency, and other errata common in spoken communication. Many downstream tasks and human readers rely on the output of the ASR system; therefore, errors introduced by the speaker and ASR system alike will be propagated to the next task in the pipeline. In this work, we propose a novel NLP task called ASR post-processing for readability (APR) that aims to transform the noisy ASR output into a readable text for humans and downstream tasks while maintaining the semantic meaning of the speaker. In addition, we describe a method to address the lack of task-specific data by synthesizing examples for the APR task using the datasets collected for Grammatical Error Correction (GEC) followed by text-to-speech (TTS) and ASR. Furthermore, we propose metrics borrowed from similar tasks to evaluate performance on the APR task. We compare fine-tuned models based on several open-sourced and adapted pre-trained models with the traditional pipeline method. Our results suggest that finetuned models improve the performance on the APR task significantly, hinting at the potential benefits of using APR systems. We hope that the read, understand, and rewrite approach of our work can serve as a basis that many NLP tasks and human readers can benefit from.