 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Multi-Person Audio/Visual Automatic Speech Recognition
May 11, 2022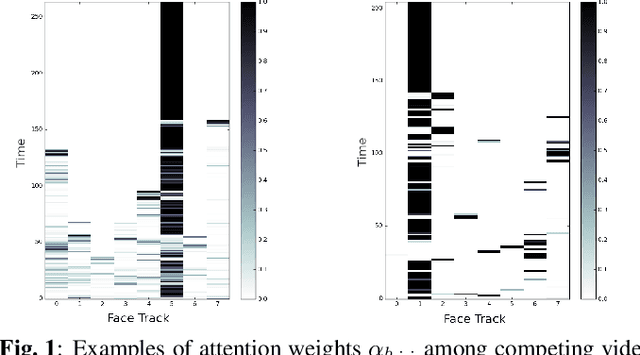

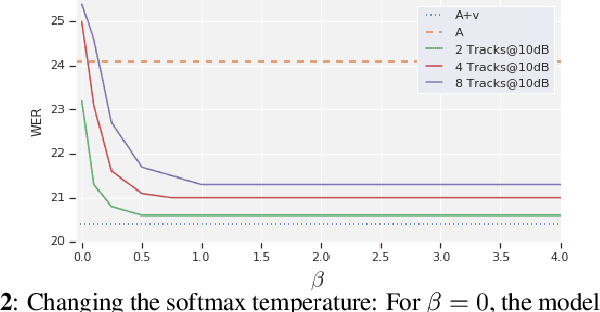
Traditionally, audio-visual automatic speech recognition has been studied under the assumption that the speaking face on the visual signal is the face matching the audio. However, in a more realistic setting, when multiple faces are potentially on screen one needs to decide which face to feed to the A/V ASR system. The present work takes the recent progress of A/V ASR one step further and considers the scenario where multiple people are simultaneously on screen (multi-person A/V ASR). We propose a fully differentiable A/V ASR model that is able to handle multiple face tracks in a video. Instead of relying on two separate models for speaker face selection and audio-visual ASR on a single face track, we introduce an attention layer to the ASR encoder that is able to soft-select the appropriate face video track. Experiments carried out on an A/V system trained on over 30k hours of YouTube videos illustrate that the proposed approach can automatically select the proper face tracks with minor WER degradation compared to an oracle selection of the speaking face while still showing benefits of employing the visual signal instead of the audio alone.
Recurrent Neural Network Transducer for Audio-Visual Speech Recognition
Nov 08, 2019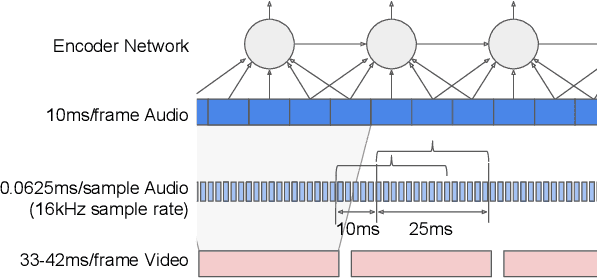
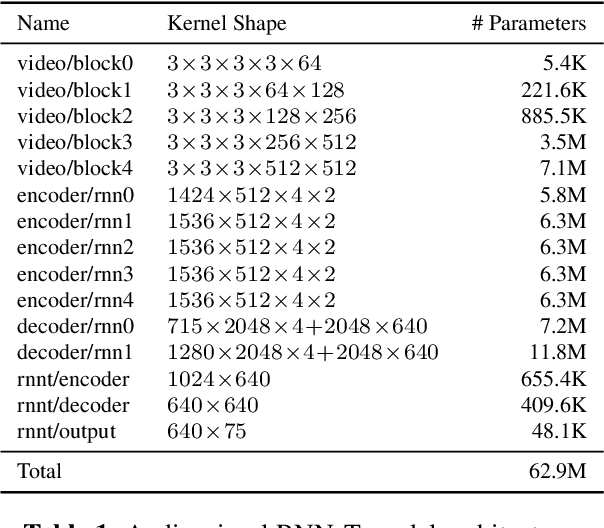
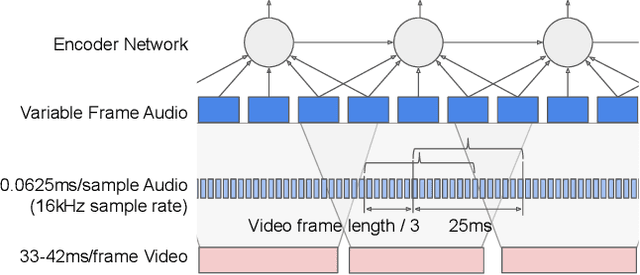

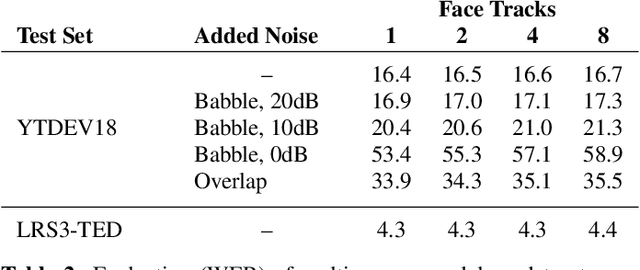
This work presents a large-scale audio-visual speech recognition system based on a recurrent neural network transducer (RNN-T) architecture. To support the development of such a system, we built a large audio-visual (A/V) dataset of segmented utterances extracted from YouTube public videos, leading to 31k hours of audio-visual training content. The performance of an audio-only, visual-only, and audio-visual system are compared on two large-vocabulary test sets: a set of utterance segments from public YouTube videos called YTDEV18 and the publicly available LRS3-TED set. To highlight the contribution of the visual modality, we also evaluated the performance of our system on the YTDEV18 set artificially corrupted with background noise and overlapping speech. To the best of our knowledge, our system significantly improves the state-of-the-art on the LRS3-TED set.
Approximated Infomax Early Stopping: Revisiting Gaussian RBMs on Natural Images
Jan 06, 2014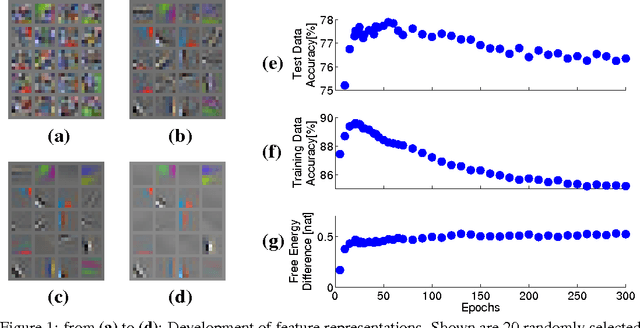

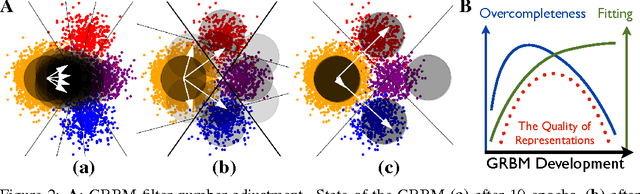
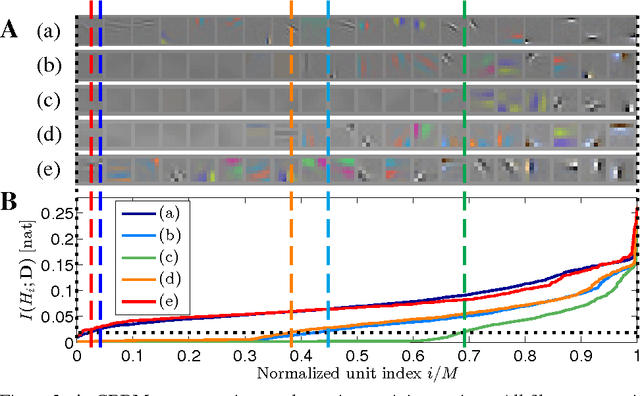
We pursue an early stopping technique that helps Gaussian Restricted Boltzmann Machines (GRBMs) to gain good natural image representations in terms of overcompleteness and data fitting. GRBMs are widely considered as an unsuitable model for natural images because they gain non-overcomplete representations which include uniform filters that do not represent useful image features. We have recently found that GRBMs once gain and subsequently lose useful filters during their training, contrary to this common perspective. We attribute this phenomenon to a tradeoff between overcompleteness of GRBM representations and data fitting. To gain GRBM representations that are overcomplete and fit data well, we propose a measure for GRBM representation quality, approximated mutual information, and an early stopping technique based on this measure. The proposed method boosts performance of classifiers trained on GRBM representations.
Auto-pooling: Learning to Improve Invariance of Image Features from Image Sequences
Mar 18, 2013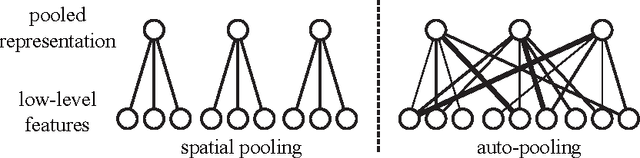
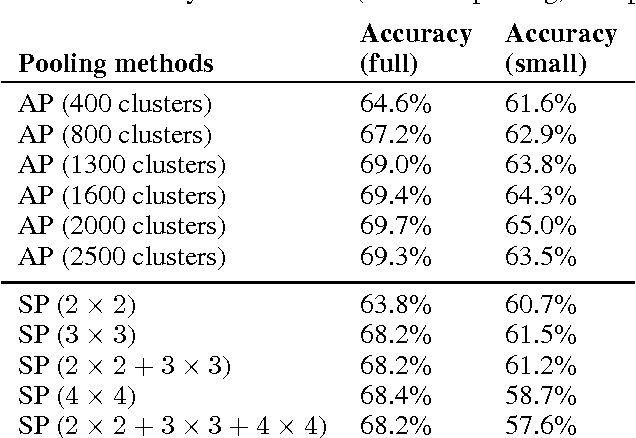
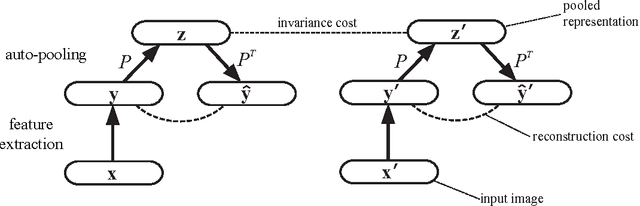
Learning invariant representations from images is one of the hardest challenges facing computer vision. Spatial pooling is widely used to create invariance to spatial shifting, but it is restricted to convolutional models. In this paper, we propose a novel pooling method that can learn soft clustering of features from image sequences. It is trained to improve the temporal coherence of features, while keeping the information loss at minimum. Our method does not use spatial information, so it can be used with non-convolutional models too. Experiments on images extracted from natural videos showed that our method can cluster similar features together. When trained by convolutional features, auto-pooling outperformed traditional spatial pooling on an image classification task, even though it does not use the spatial topology of features.
Apprenticeship Learning for Model Parameters of Partially Observable Environments
Jun 27, 2012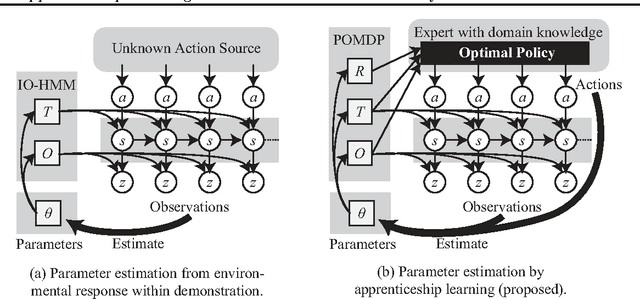
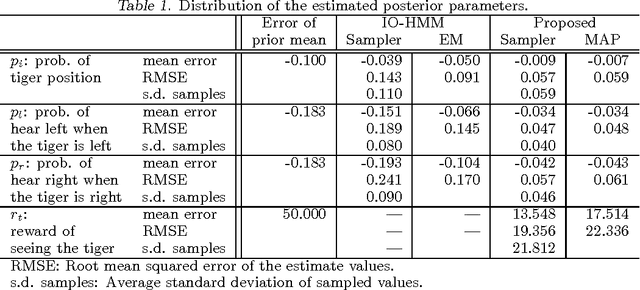
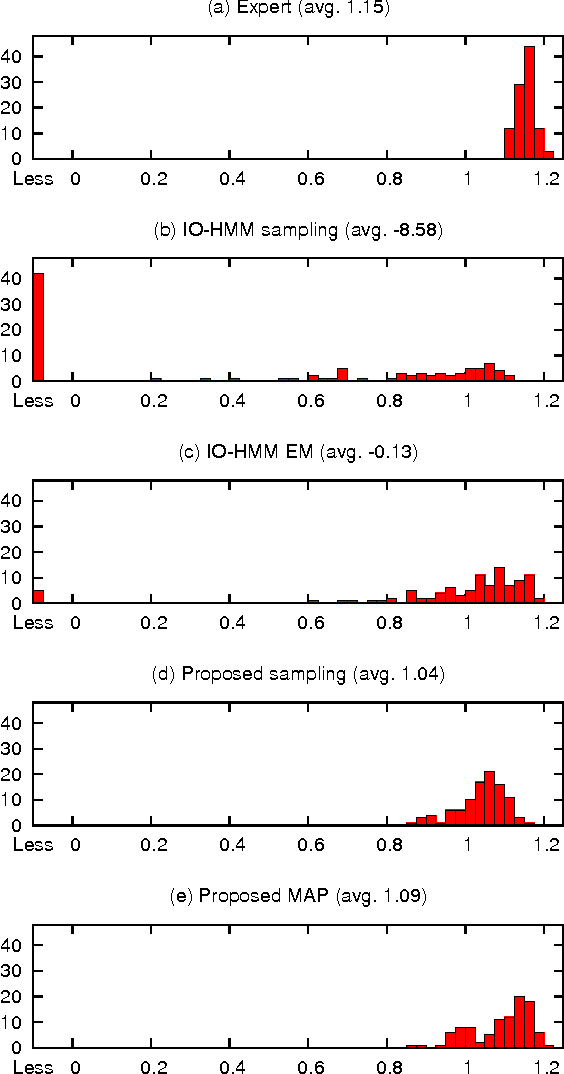
We consider apprenticeship learning, i.e., having an agent learn a task by observing an expert demonstrating the task in a partially observable environment when the model of the environment is uncertain. This setting is useful in applications where the explicit modeling of the environment is difficult, such as a dialogue system. We show that we can extract information about the environment model by inferring action selection process behind the demonstration, under the assumption that the expert is choosing optimal actions based on knowledge of the true model of the target environment. Proposed algorithms can achieve more accurate estimates of POMDP parameters and better policies from a short demonstration, compared to methods that learns only from the reaction from the environment.
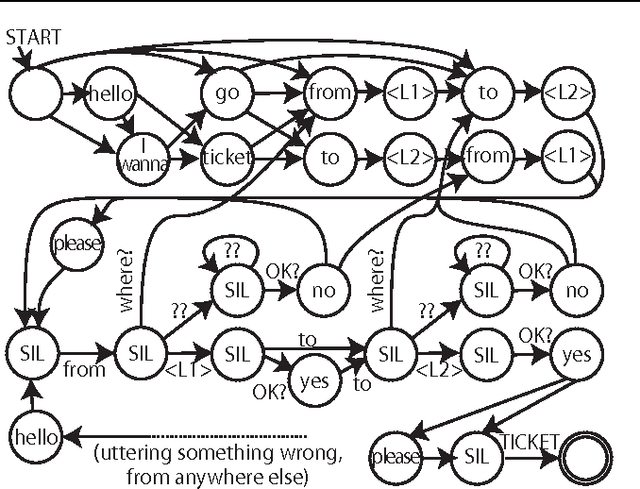
Restricted Collapsed Draw: Accurate Sampling for Hierarchical Chinese Restaurant Process Hidden Markov Models
Jun 02, 2011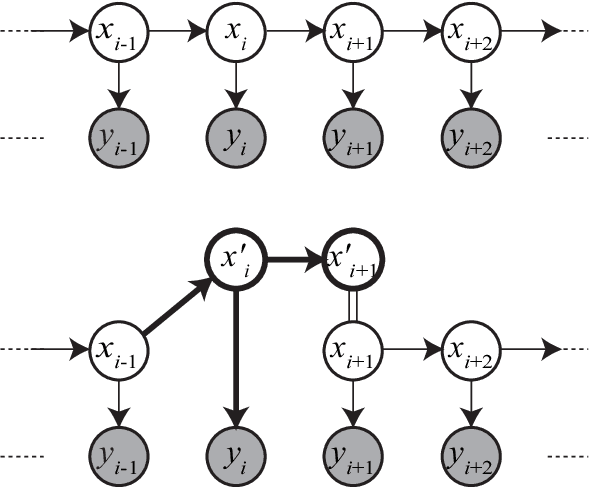
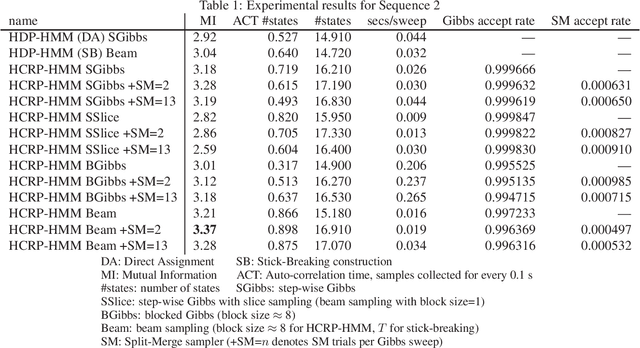
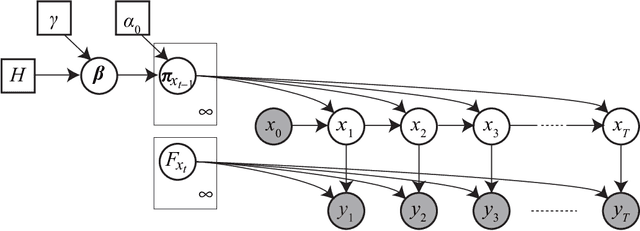
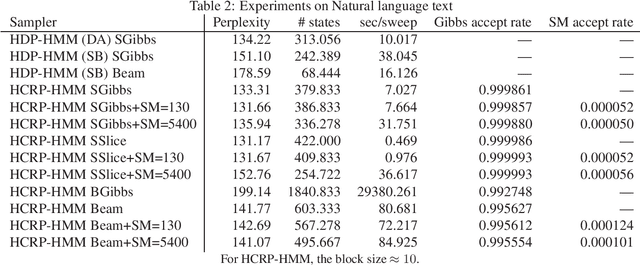
We propose a restricted collapsed draw (RCD) sampler, a general Markov chain Monte Carlo sampler of simultaneous draws from a hierarchical Chinese restaurant process (HCRP) with restriction. Models that require simultaneous draws from a hierarchical Dirichlet process with restriction, such as infinite Hidden markov models (iHMM), were difficult to enjoy benefits of \markerg{the} HCRP due to combinatorial explosion in calculating distributions of coupled draws. By constructing a proposal of seating arrangements (partitioning) and stochastically accepts the proposal by the Metropolis-Hastings algorithm, the RCD sampler makes accurate sampling for complex combination of draws while retaining efficiency of HCRP representation. Based on the RCD sampler, we developed a series of sophisticated sampling algorithms for iHMMs, including blocked Gibbs sampling, beam sampling, and split-merge sampling, that outperformed conventional iHMM samplers in experiments