 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Automatic Generation and Simplification of Children's Stories
Oct 27, 2023



With recent advances in large language models (LLMs), the concept of automatically generating children's educational materials has become increasingly realistic. Working toward the goal of age-appropriate simplicity in generated educational texts, we first examine the ability of several popular LLMs to generate stories with properly adjusted lexical and readability levels. We find that, in spite of the growing capabilities of LLMs, they do not yet possess the ability to limit their vocabulary to levels appropriate for younger age groups. As a second experiment, we explore the ability of state-of-the-art lexical simplification models to generalize to the domain of children's stories and, thus, create an efficient pipeline for their automatic generation. In order to test these models, we develop a dataset of child-directed lexical simplification instances, with examples taken from the LLM-generated stories in our first experiment. We find that, while the strongest-performing current lexical simplification models do not perform as well on material designed for children due to their reliance on large language models behind the scenes, some models that still achieve fairly strong results on general data can mimic or even improve their performance on children-directed data with proper fine-tuning, which we conduct using our newly created child-directed simplification dataset.
Neural Machine Translation for the Indigenous Languages of the Americas: An Introduction
Jun 11, 2023Neural models have drastically advanced state of the art for machine translation (MT) between high-resource languages. Traditionally, these models rely on large amounts of training data, but many language pairs lack these resources. However, an important part of the languages in the world do not have this amount of data. Most languages from the Americas are among them, having a limited amount of parallel and monolingual data, if any. Here, we present an introduction to the interested reader to the basic challenges, concepts, and techniques that involve the creation of MT systems for these languages. Finally, we discuss the recent advances and findings and open questions, product of an increased interest of the NLP community in these languages.
Ethical Considerations for Machine Translation of Indigenous Languages: Giving a Voice to the Speakers
May 31, 2023


In recent years machine translation has become very successful for high-resource language pairs. This has also sparked new interest in research on the automatic translation of low-resource languages, including Indigenous languages. However, the latter are deeply related to the ethnic and cultural groups that speak (or used to speak) them. The data collection, modeling and deploying machine translation systems thus result in new ethical questions that must be addressed. Motivated by this, we first survey the existing literature on ethical considerations for the documentation, translation, and general natural language processing for Indigenous languages. Afterward, we conduct and analyze an interview study to shed light on the positions of community leaders, teachers, and language activists regarding ethical concerns for the automatic translation of their languages. Our results show that the inclusion, at different degrees, of native speakers and community members is vital to performing better and more ethical research on Indigenous languages.
An Investigation of Noise in Morphological Inflection
May 26, 2023



With a growing focus on morphological inflection systems for languages where high-quality data is scarce, training data noise is a serious but so far largely ignored concern. We aim at closing this gap by investigating the types of noise encountered within a pipeline for truly unsupervised morphological paradigm completion and its impact on morphological inflection systems: First, we propose an error taxonomy and annotation pipeline for inflection training data. Then, we compare the effect of different types of noise on multiple state-of-the-art inflection models. Finally, we propose a novel character-level masked language modeling (CMLM) pretraining objective and explore its impact on the models' resistance to noise. Our experiments show that various architectures are impacted differently by separate types of noise, but encoder-decoders tend to be more robust to noise than models trained with a copy bias. CMLM pretraining helps transformers, but has lower impact on LSTMs.
Meeting the Needs of Low-Resource Languages: The Value of Automatic Alignments via Pretrained Models
Feb 15, 2023Large multilingual models have inspired a new class of word alignment methods, which work well for the model's pretraining languages. However, the languages most in need of automatic alignment are low-resource and, thus, not typically included in the pretraining data. In this work, we ask: How do modern aligners perform on unseen languages, and are they better than traditional methods? We contribute gold-standard alignments for Bribri--Spanish, Guarani--Spanish, Quechua--Spanish, and Shipibo-Konibo--Spanish. With these, we evaluate state-of-the-art aligners with and without model adaptation to the target language. Finally, we also evaluate the resulting alignments extrinsically through two downstream tasks: named entity recognition and part-of-speech tagging. We find that although transformer-based methods generally outperform traditional models, the two classes of approach remain competitive with each other.
Mind the Knowledge Gap: A Survey of Knowledge-enhanced Dialogue Systems
Dec 20, 2022



Many dialogue systems (DSs) lack characteristics humans have, such as emotion perception, factuality, and informativeness. Enhancing DSs with knowledge alleviates this problem, but, as many ways of doing so exist, keeping track of all proposed methods is difficult. Here, we present the first survey of knowledge-enhanced DSs. We define three categories of systems - internal, external, and hybrid - based on the knowledge they use. We survey the motivation for enhancing DSs with knowledge, used datasets, and methods for knowledge search, knowledge encoding, and knowledge incorporation. Finally, we propose how to improve existing systems based on theories from linguistics and cognitive science.
A Major Obstacle for NLP Research: Let's Talk about Time Allocation!
Nov 30, 2022The field of natural language processing (NLP) has grown over the last few years: conferences have become larger, we have published an incredible amount of papers, and state-of-the-art research has been implemented in a large variety of customer-facing products. However, this paper argues that we have been less successful than we should have been and reflects on where and how the field fails to tap its full potential. Specifically, we demonstrate that, in recent years, subpar time allocation has been a major obstacle for NLP research. We outline multiple concrete problems together with their negative consequences and, importantly, suggest remedies to improve the status quo. We hope that this paper will be a starting point for discussions around which common practices are -- or are not -- beneficial for NLP research.
Match the Script, Adapt if Multilingual: Analyzing the Effect of Multilingual Pretraining on Cross-lingual Transferability
Mar 21, 2022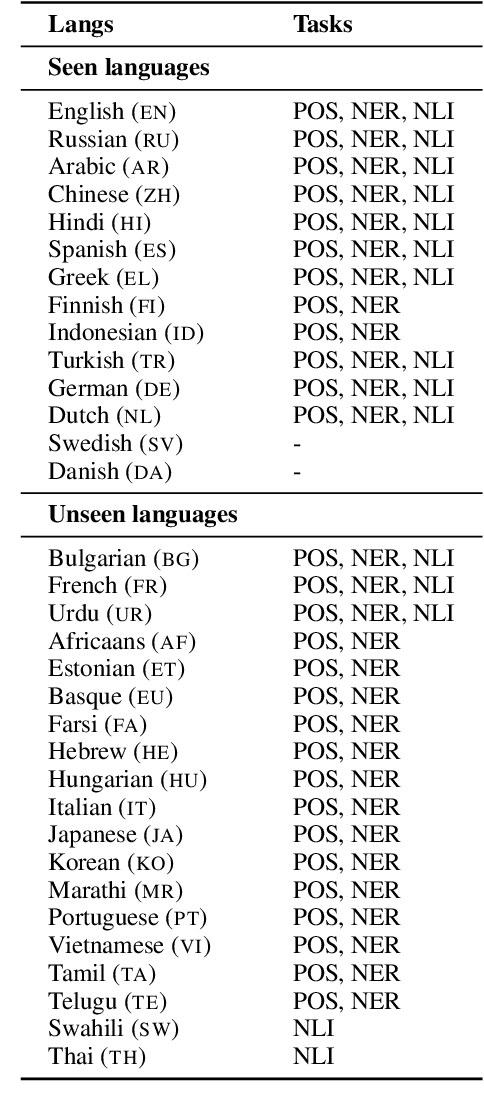
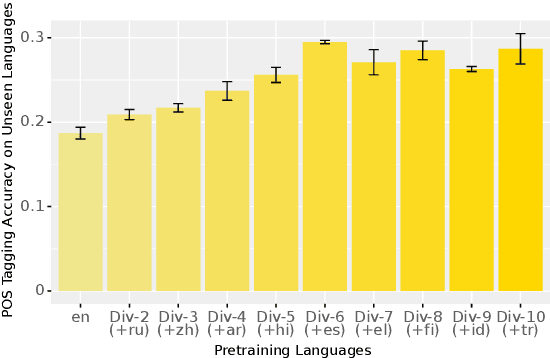
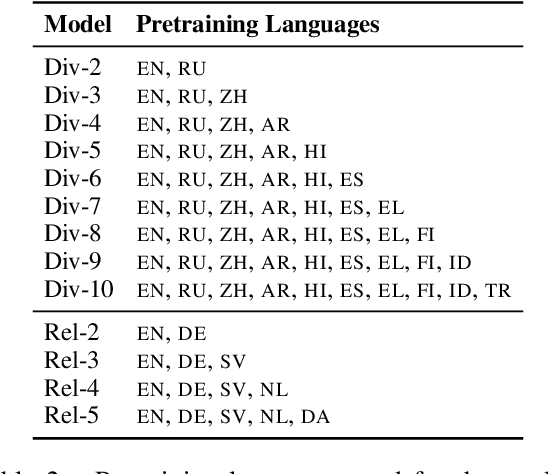
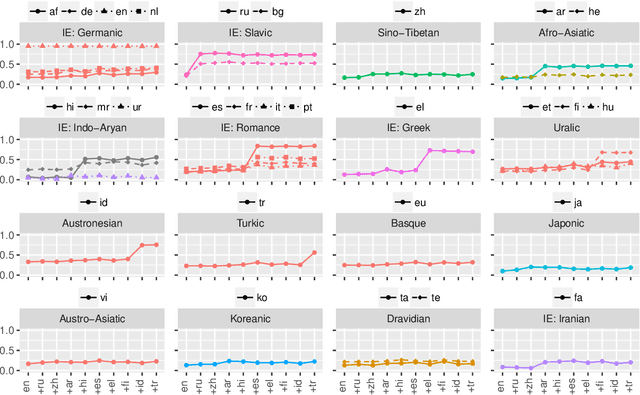
Pretrained multilingual models enable zero-shot learning even for unseen languages, and that performance can be further improved via adaptation prior to finetuning. However, it is unclear how the number of pretraining languages influences a model's zero-shot learning for languages unseen during pretraining. To fill this gap, we ask the following research questions: (1) How does the number of pretraining languages influence zero-shot performance on unseen target languages? (2) Does the answer to that question change with model adaptation? (3) Do the findings for our first question change if the languages used for pretraining are all related? Our experiments on pretraining with related languages indicate that choosing a diverse set of languages is crucial. Without model adaptation, surprisingly, increasing the number of pretraining languages yields better results up to adding related languages, after which performance plateaus. In contrast, with model adaptation via continued pretraining, pretraining on a larger number of languages often gives further improvement, suggesting that model adaptation is crucial to exploit additional pretraining languages.
BPE vs. Morphological Segmentation: A Case Study on Machine Translation of Four Polysynthetic Languages
Mar 16, 2022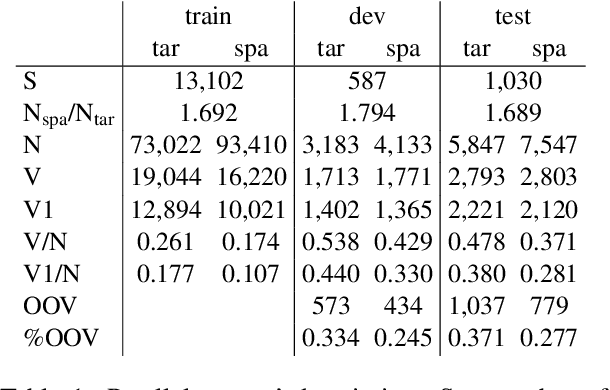
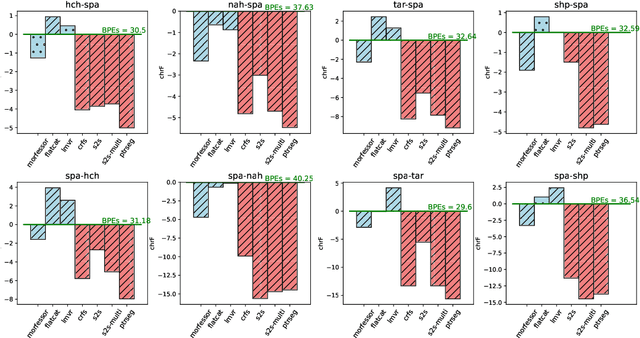
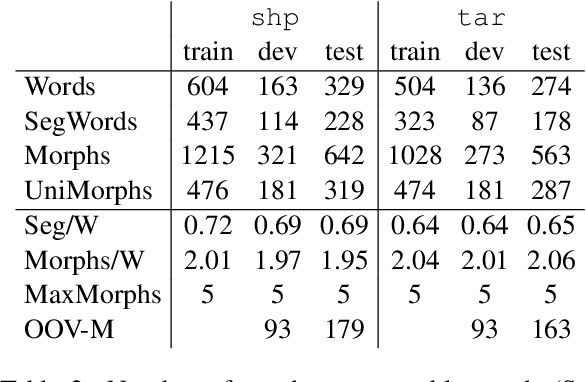
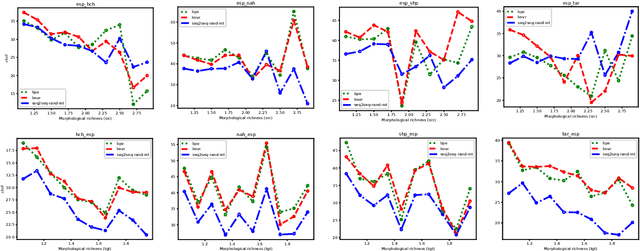
Morphologically-rich polysynthetic languages present a challenge for NLP systems due to data sparsity, and a common strategy to handle this issue is to apply subword segmentation. We investigate a wide variety of supervised and unsupervised morphological segmentation methods for four polysynthetic languages: Nahuatl, Raramuri, Shipibo-Konibo, and Wixarika. Then, we compare the morphologically inspired segmentation methods against Byte-Pair Encodings (BPEs) as inputs for machine translation (MT) when translating to and from Spanish. We show that for all language pairs except for Nahuatl, an unsupervised morphological segmentation algorithm outperforms BPEs consistently and that, although supervised methods achieve better segmentation scores, they under-perform in MT challenges. Finally, we contribute two new morphological segmentation datasets for Raramuri and Shipibo-Konibo, and a parallel corpus for Raramuri--Spanish.
Morphological Processing of Low-Resource Languages: Where We Are and What's Next
Mar 16, 2022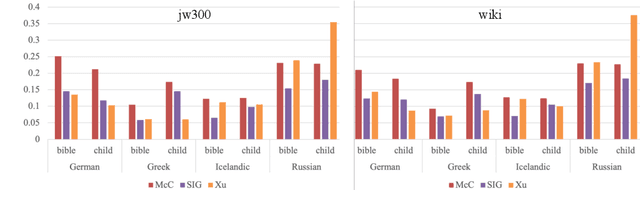
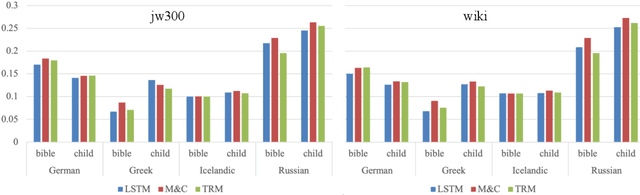
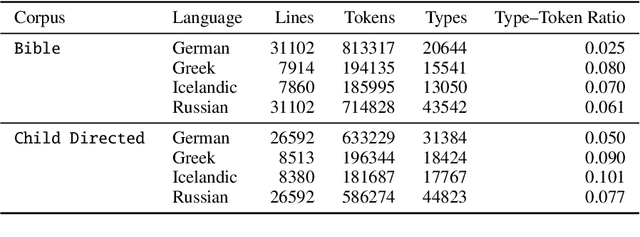
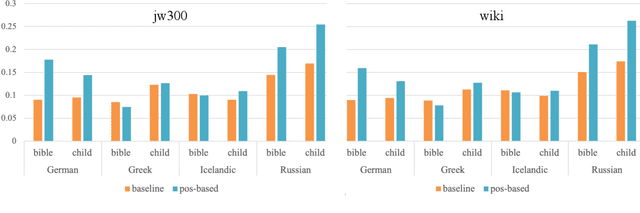
Automatic morphological processing can aid downstream natural language processing applications, especially for low-resource languages, and assist language documentation efforts for endangered languages. Having long been multilingual, the field of computational morphology is increasingly moving towards approaches suitable for languages with minimal or no annotated resources. First, we survey recent developments in computational morphology with a focus on low-resource languages. Second, we argue that the field is ready to tackle the logical next challenge: understanding a language's morphology from raw text alone. We perform an empirical study on a truly unsupervised version of the paradigm completion task and show that, while existing state-of-the-art models bridged by two newly proposed models we devise perform reasonably, there is still much room for improvement. The stakes are high: solving this task will increase the language coverage of morphological resources by a number of magnitudes.