 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill and Align Decomposition for Enhanced Claim Verification
Feb 25, 2026Complex claim verification requires decomposing sentences into verifiable subclaims, yet existing methods struggle to align decomposition quality with verification performance. We propose a reinforcement learning (RL) approach that jointly optimizes decomposition quality and verifier alignment using Group Relative Policy Optimization (GRPO). Our method integrates: (i) structured sequential reasoning; (ii) supervised finetuning on teacher-distilled exemplars; and (iii) a multi-objective reward balancing format compliance, verifier alignment, and decomposition quality. Across six evaluation settings, our trained 8B decomposer improves downstream verification performance to (71.75%) macro-F1, outperforming prompt-based approaches ((+1.99), (+6.24)) and existing RL methods ((+5.84)). Human evaluation confirms the high quality of the generated subclaims. Our framework enables smaller language models to achieve state-of-the-art claim verification by jointly optimising for verification accuracy and decomposition quality.
Meeting the Needs of Low-Resource Languages: The Value of Automatic Alignments via Pretrained Models
Feb 15, 2023Large multilingual models have inspired a new class of word alignment methods, which work well for the model's pretraining languages. However, the languages most in need of automatic alignment are low-resource and, thus, not typically included in the pretraining data. In this work, we ask: How do modern aligners perform on unseen languages, and are they better than traditional methods? We contribute gold-standard alignments for Bribri--Spanish, Guarani--Spanish, Quechua--Spanish, and Shipibo-Konibo--Spanish. With these, we evaluate state-of-the-art aligners with and without model adaptation to the target language. Finally, we also evaluate the resulting alignments extrinsically through two downstream tasks: named entity recognition and part-of-speech tagging. We find that although transformer-based methods generally outperform traditional models, the two classes of approach remain competitive with each other.
Revisiting Syllables in Language Modelling and their Application on Low-Resource Machine Translation
Oct 05, 2022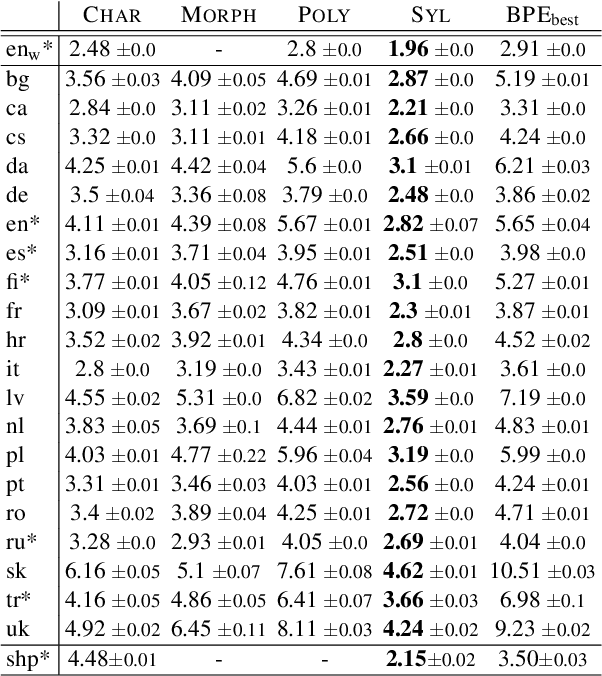

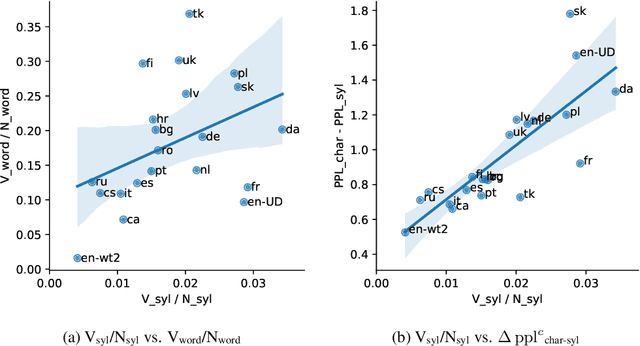
Language modelling and machine translation tasks mostly use subword or character inputs, but syllables are seldom used. Syllables provide shorter sequences than characters, require less-specialised extracting rules than morphemes, and their segmentation is not impacted by the corpus size. In this study, we first explore the potential of syllables for open-vocabulary language modelling in 21 languages. We use rule-based syllabification methods for six languages and address the rest with hyphenation, which works as a syllabification proxy. With a comparable perplexity, we show that syllables outperform characters and other subwords. Moreover, we study the importance of syllables on neural machine translation for a non-related and low-resource language-pair (Spanish--Shipibo-Konibo). In pairwise and multilingual systems, syllables outperform unsupervised subwords, and further morphological segmentation methods, when translating into a highly synthetic language with a transparent orthography (Shipibo-Konibo). Finally, we perform some human evaluation, and discuss limitations and opportunities.
Building an Endangered Language Resource in the Classroom: Universal Dependencies for Kakataibo
Jun 21, 2022
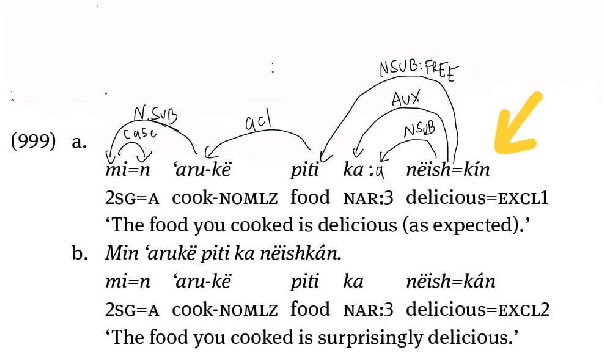
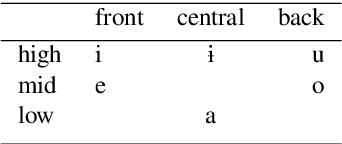
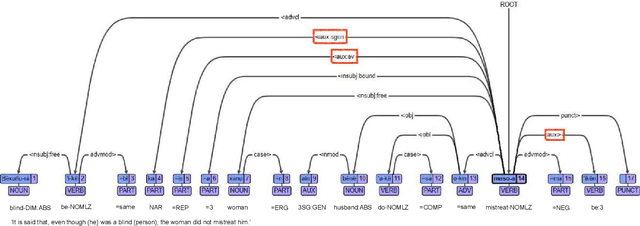
In this paper, we launch a new Universal Dependencies treebank for an endangered language from Amazonia: Kakataibo, a Panoan language spoken in Peru. We first discuss the collaborative methodology implemented, which proved effective to create a treebank in the context of a Computational Linguistic course for undergraduates. Then, we describe the general details of the treebank and the language-specific considerations implemented for the proposed annotation. We finally conduct some experiments on part-of-speech tagging and syntactic dependency parsing. We focus on monolingual and transfer learning settings, where we study the impact of a Shipibo-Konibo treebank, another Panoan language resource.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Quantifying Synthesis and Fusion and their Impact on Machine Translation
May 06, 2022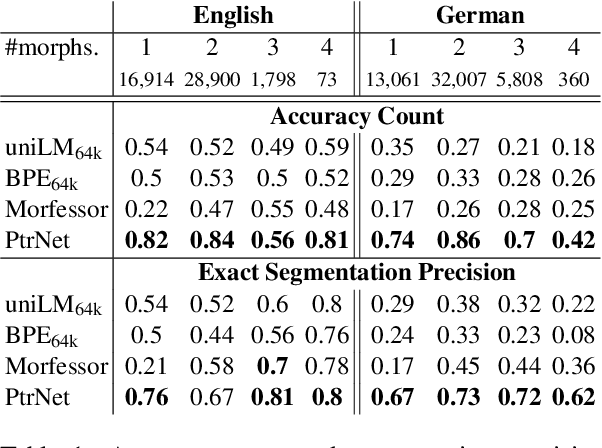
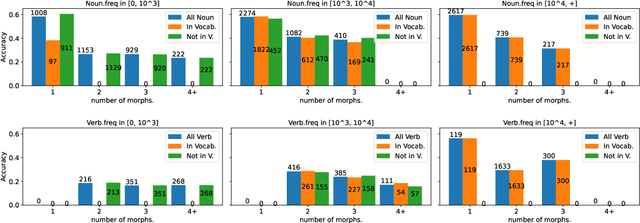

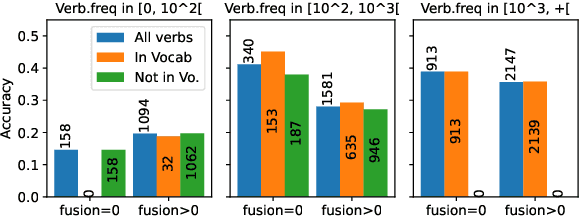
Theoretical work in morphological typology offers the possibility of measuring morphological diversity on a continuous scale. However, literature in Natural Language Processing (NLP) typically labels a whole language with a strict type of morphology, e.g. fusional or agglutinative. In this work, we propose to reduce the rigidity of such claims, by quantifying morphological typology at the word and segment level. We consider Payne (2017)'s approach to classify morphology using two indices: synthesis (e.g. analytic to polysynthetic) and fusion (agglutinative to fusional). For computing synthesis, we test unsupervised and supervised morphological segmentation methods for English, German and Turkish, whereas for fusion, we propose a semi-automatic method using Spanish as a case study. Then, we analyse the relationship between machine translation quality and the degree of synthesis and fusion at word (nouns and verbs for English-Turkish, and verbs in English-Spanish) and segment level (previous language pairs plus English-German in both directions). We complement the word-level analysis with human evaluation, and overall, we observe a consistent impact of both indexes on machine translation quality.
BPE vs. Morphological Segmentation: A Case Study on Machine Translation of Four Polysynthetic Languages
Mar 16, 2022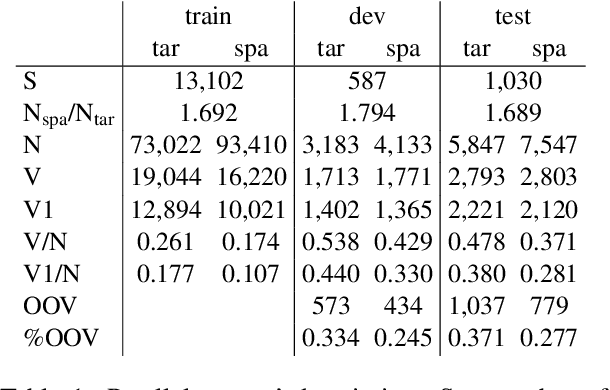
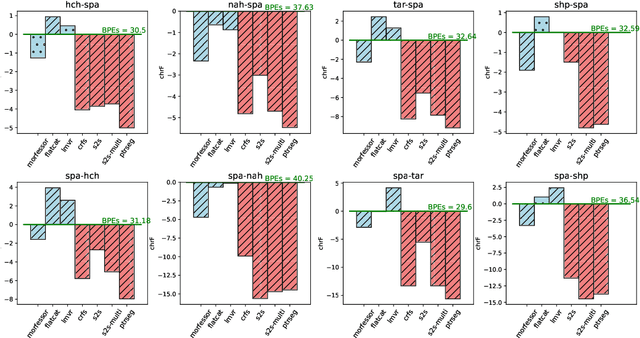
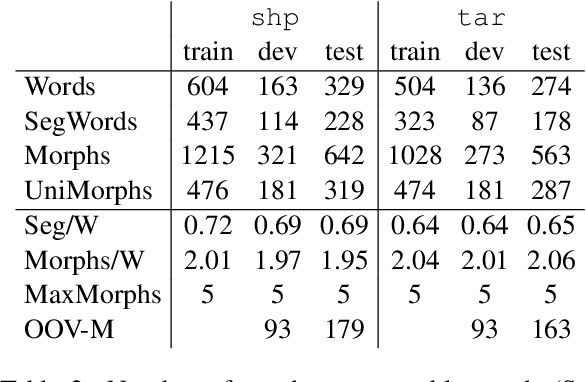
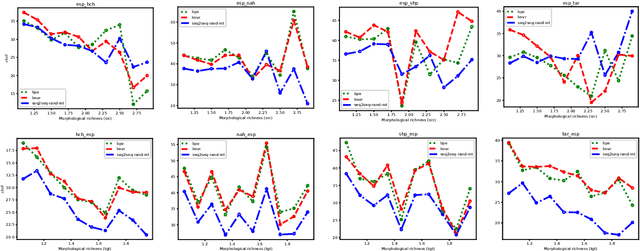
Morphologically-rich polysynthetic languages present a challenge for NLP systems due to data sparsity, and a common strategy to handle this issue is to apply subword segmentation. We investigate a wide variety of supervised and unsupervised morphological segmentation methods for four polysynthetic languages: Nahuatl, Raramuri, Shipibo-Konibo, and Wixarika. Then, we compare the morphologically inspired segmentation methods against Byte-Pair Encodings (BPEs) as inputs for machine translation (MT) when translating to and from Spanish. We show that for all language pairs except for Nahuatl, an unsupervised morphological segmentation algorithm outperforms BPEs consistently and that, although supervised methods achieve better segmentation scores, they under-perform in MT challenges. Finally, we contribute two new morphological segmentation datasets for Raramuri and Shipibo-Konibo, and a parallel corpus for Raramuri--Spanish.
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
Apr 18, 2021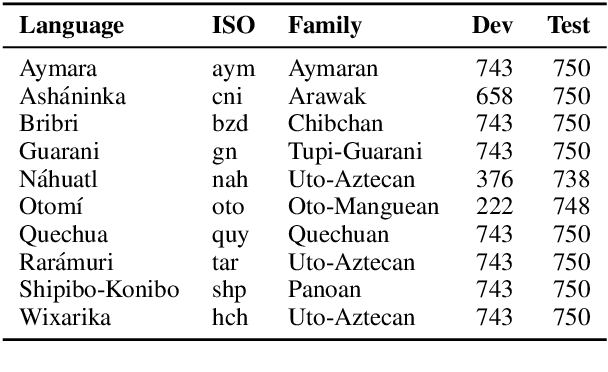

Pretrained multilingual models are able to perform cross-lingual transfer in a zero-shot setting, even for languages unseen during pretraining. However, prior work evaluating performance on unseen languages has largely been limited to low-level, syntactic tasks, and it remains unclear if zero-shot learning of high-level, semantic tasks is possible for unseen languages. To explore this question, we present AmericasNLI, an extension of XNLI (Conneau et al., 2018) to 10 indigenous languages of the Americas. We conduct experiments with XLM-R, testing multiple zero-shot and translation-based approaches. Additionally, we explore model adaptation via continued pretraining and provide an analysis of the dataset by considering hypothesis-only models. We find that XLM-R's zero-shot performance is poor for all 10 languages, with an average performance of 38.62%. Continued pretraining offers improvements, with an average accuracy of 44.05%. Surprisingly, training on poorly translated data by far outperforms all other methods with an accuracy of 48.72%.
Revisiting Neural Language Modelling with Syllables
Oct 24, 2020
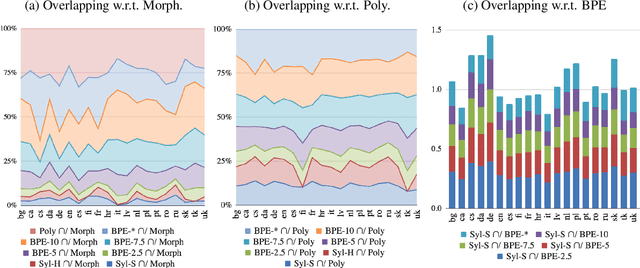
Language modelling is regularly analysed at word, subword or character units, but syllables are seldom used. Syllables provide shorter sequences than characters, they can be extracted with rules, and their segmentation typically requires less specialised effort than identifying morphemes. We reconsider syllables for an open-vocabulary generation task in 20 languages. We use rule-based syllabification methods for five languages and address the rest with a hyphenation tool, which behaviour as syllable proxy is validated. With a comparable perplexity, we show that syllables outperform characters, annotated morphemes and unsupervised subwords. Finally, we also study the overlapping of syllables concerning other subword pieces and discuss some limitations and opportunities.
Efficient strategies for hierarchical text classification: External knowledge and auxiliary tasks
May 22, 2020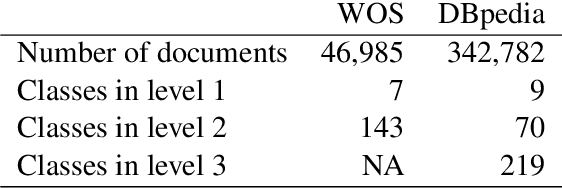
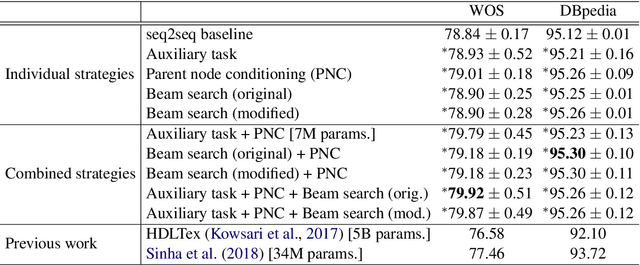
In hierarchical text classification, we perform a sequence of inference steps to predict the category of a document from top to bottom of a given class taxonomy. Most of the studies have focused on developing novels neural network architectures to deal with the hierarchical structure, but we prefer to look for efficient ways to strengthen a baseline model. We first define the task as a sequence-to-sequence problem. Afterwards, we propose an auxiliary synthetic task of bottom-up-classification. Then, from external dictionaries, we retrieve textual definitions for the classes of all the hierarchy's layers, and map them into the word vector space. We use the class-definition embeddings as an additional input to condition the prediction of the next layer and in an adapted beam search. Whereas the modified search did not provide large gains, the combination of the auxiliary task and the additional input of class-definitions significantly enhance the classification accuracy. With our efficient approaches, we outperform previous studies, using a drastically reduced number of parameters, in two well-known English datasets.