 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving noise robustness of automatic speech recognition via parallel data and teacher-student learning
Paper and Code
Jan 11, 2019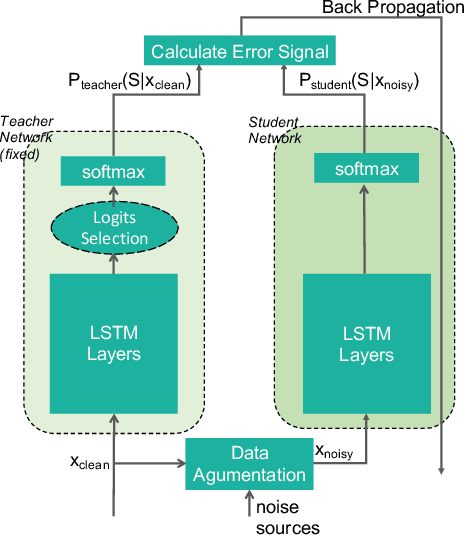
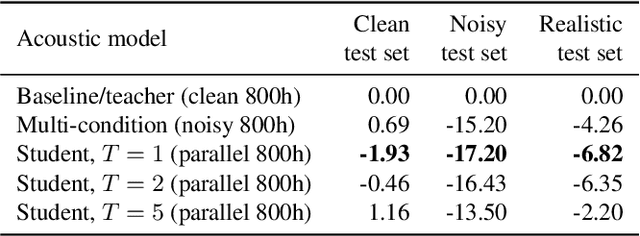
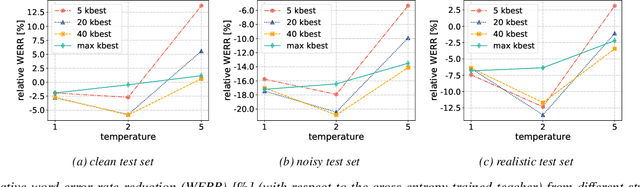
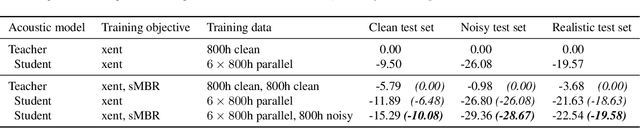
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the k highest values to prevent wrong emphasis of knowledge from the teacher and to reduce bandwidth needed for transferring data. We incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained models apart from cross entropy trained ones. The best sequence trained student model yields relative word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively comparing to a sequence trained teacher.