 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Data Driven Inverse Text Normalization using Data Augmentation
Paper and Code
Jul 20, 2022
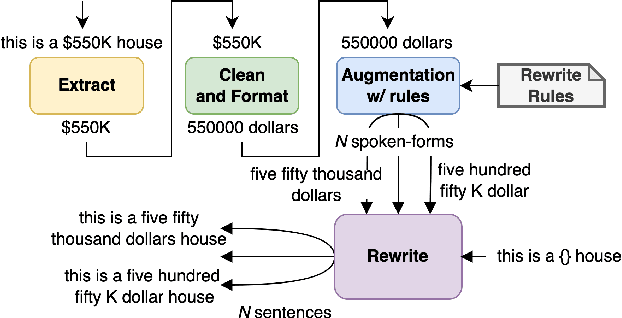

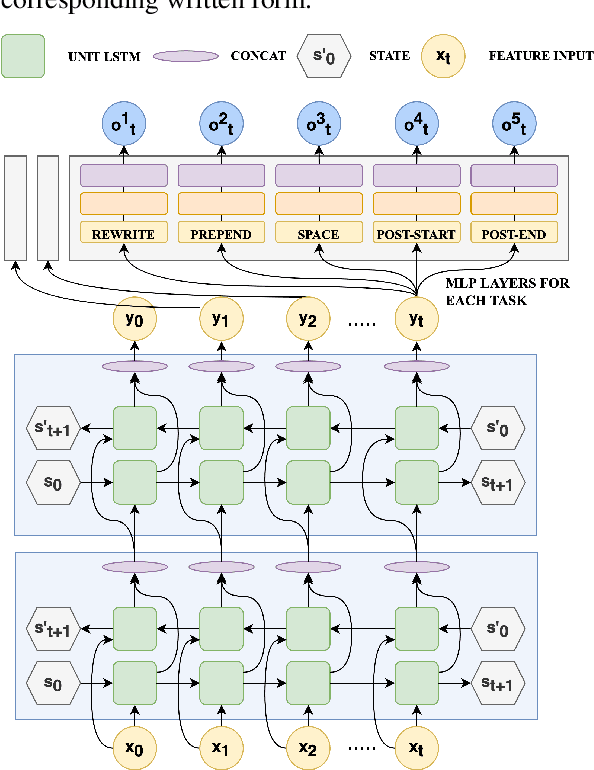
Inverse text normalization (ITN) is used to convert the spoken form output of an automatic speech recognition (ASR) system to a written form. Traditional handcrafted ITN rules can be complex to transcribe and maintain. Meanwhile neural modeling approaches require quality large-scale spoken-written pair examples in the same or similar domain as the ASR system (in-domain data), to train. Both these approaches require costly and complex annotations. In this paper, we present a data augmentation technique that effectively generates rich spoken-written numeric pairs from out-of-domain textual data with minimal human annotation. We empirically demonstrate that ITN model trained using our data augmentation technique consistently outperform ITN model trained using only in-domain data across all numeric surfaces like cardinal, currency, and fraction, by an overall accuracy of 14.44%.