 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
AVFormer: Injecting Vision into Frozen Speech Models for Zero-Shot AV-ASR
Mar 29, 2023
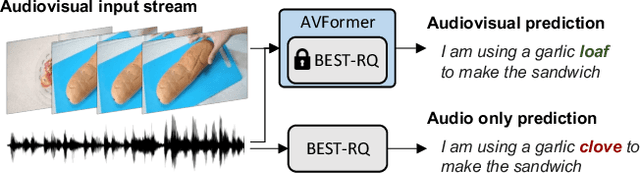
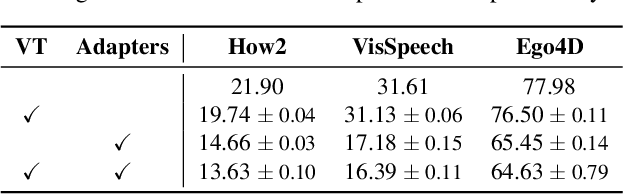
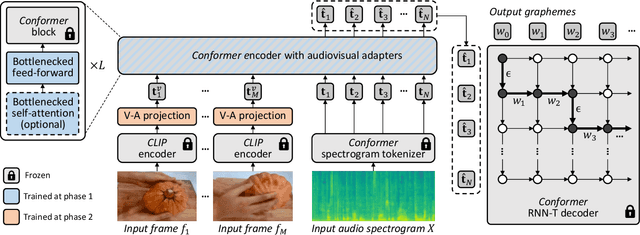

Audiovisual automatic speech recognition (AV-ASR) aims to improve the robustness of a speech recognition system by incorporating visual information. Training fully supervised multimodal models for this task from scratch, however is limited by the need for large labelled audiovisual datasets (in each downstream domain of interest). We present AVFormer, a simple method for augmenting audio-only models with visual information, at the same time performing lightweight domain adaptation. We do this by (i) injecting visual embeddings into a frozen ASR model using lightweight trainable adaptors. We show that these can be trained on a small amount of weakly labelled video data with minimum additional training time and parameters. (ii) We also introduce a simple curriculum scheme during training which we show is crucial to enable the model to jointly process audio and visual information effectively; and finally (iii) we show that our model achieves state of the art zero-shot results on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (LibriSpeech). Qualitative results show that our model effectively leverages visual information for robust speech recognition.
Variable Attention Masking for Configurable Transformer Transducer Speech Recognition
Nov 02, 2022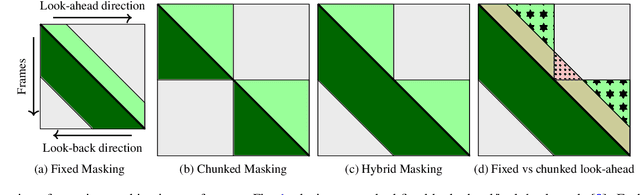
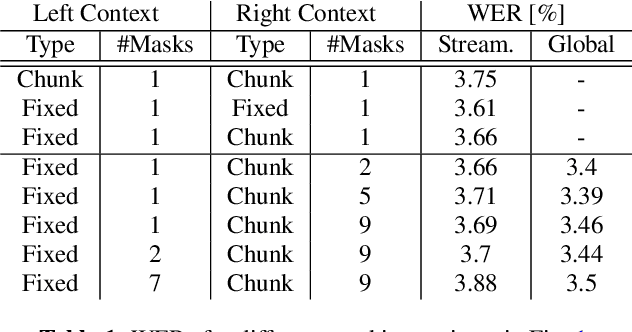
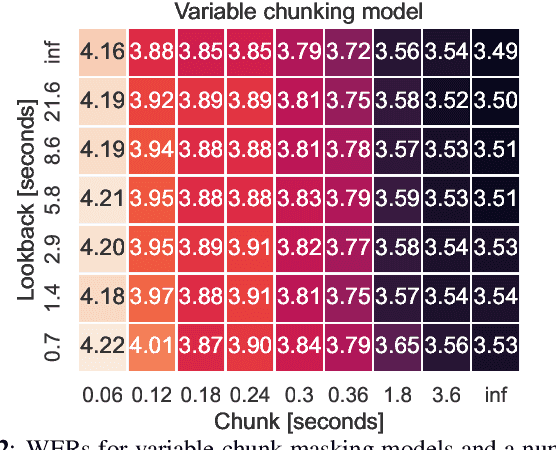
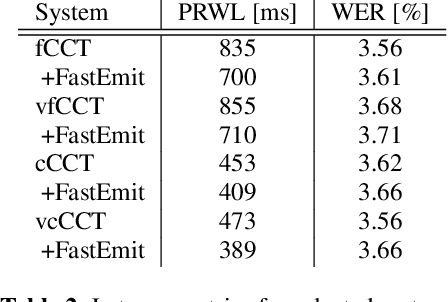
This work studies the use of attention masking in transformer transducer based speech recognition for building a single configurable model for different deployment scenarios. We present a comprehensive set of experiments comparing fixed masking, where the same attention mask is applied at every frame, with chunked masking, where the attention mask for each frame is determined by chunk boundaries, in terms of recognition accuracy and latency. We then explore the use of variable masking, where the attention masks are sampled from a target distribution at training time, to build models that can work in different configurations. Finally, we investigate how a single configurable model can be used to perform both first pass streaming recognition and second pass acoustic rescoring. Experiments show that chunked masking achieves a better accuracy vs latency trade-off compared to fixed masking, both with and without FastEmit. We also show that variable masking improves the accuracy by up to 8% relative in the acoustic re-scoring scenario.
HK-LegiCoST: Leveraging Non-Verbatim Transcripts for Speech Translation
Jun 20, 2023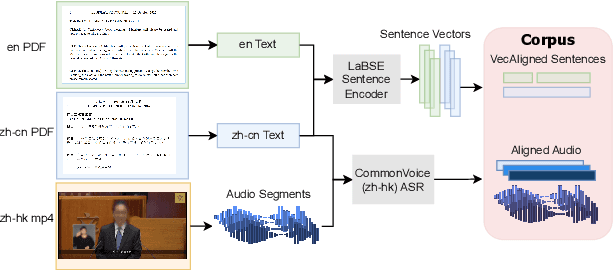
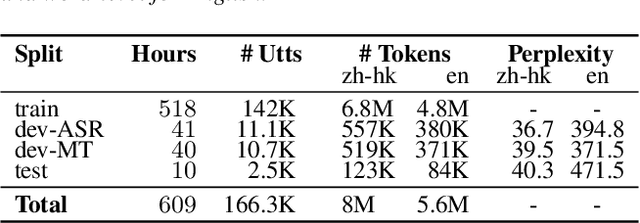
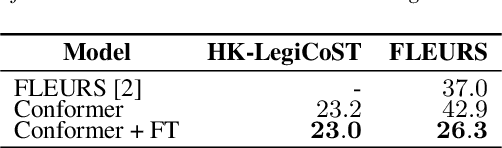

We introduce HK-LegiCoST, a new three-way parallel corpus of Cantonese-English translations, containing 600+ hours of Cantonese audio, its standard traditional Chinese transcript, and English translation, segmented and aligned at the sentence level. We describe the notable challenges in corpus preparation: segmentation, alignment of long audio recordings, and sentence-level alignment with non-verbatim transcripts. Such transcripts make the corpus suitable for speech translation research when there are significant differences between the spoken and written forms of the source language. Due to its large size, we are able to demonstrate competitive speech translation baselines on HK-LegiCoST and extend them to promising cross-corpus results on the FLEURS Cantonese subset. These results deliver insights into speech recognition and translation research in languages for which non-verbatim or ``noisy'' transcription is common due to various factors, including vernacular and dialectal speech.
Structured State Space Decoder for Speech Recognition and Synthesis
Oct 31, 2022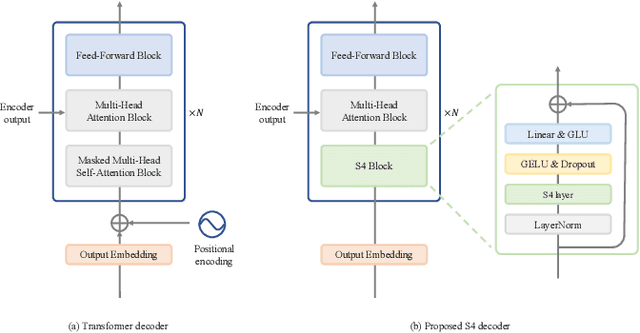
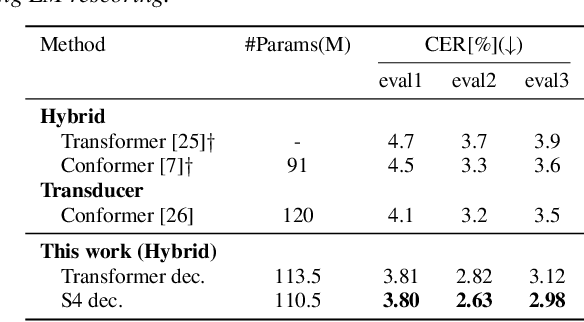
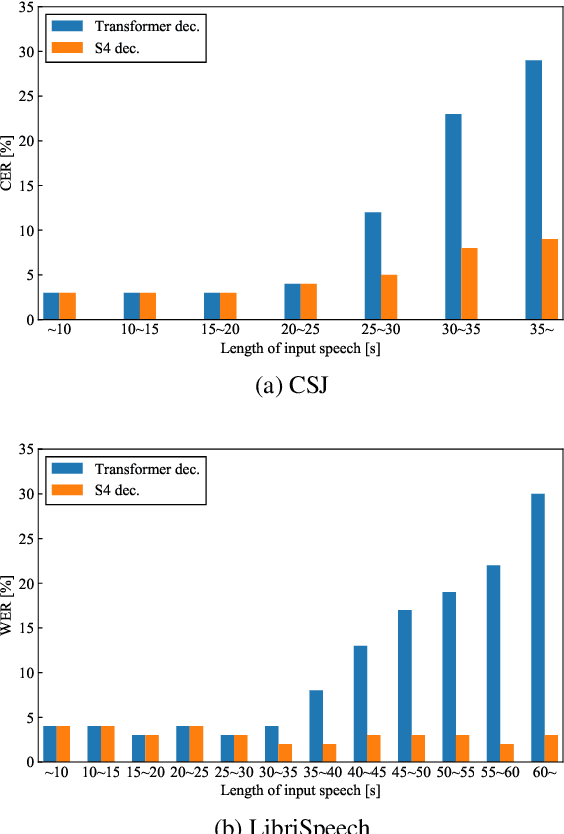
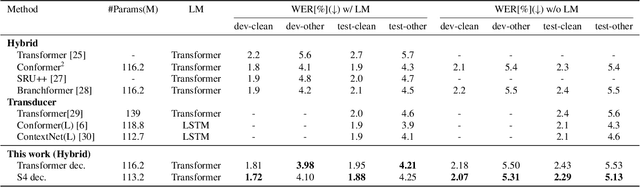
Automatic speech recognition (ASR) systems developed in recent years have shown promising results with self-attention models (e.g., Transformer and Conformer), which are replacing conventional recurrent neural networks. Meanwhile, a structured state space model (S4) has been recently proposed, producing promising results for various long-sequence modeling tasks, including raw speech classification. The S4 model can be trained in parallel, same as the Transformer model. In this study, we applied S4 as a decoder for ASR and text-to-speech (TTS) tasks by comparing it with the Transformer decoder. For the ASR task, our experimental results demonstrate that the proposed model achieves a competitive word error rate (WER) of 1.88%/4.25% on LibriSpeech test-clean/test-other set and a character error rate (CER) of 3.80%/2.63%/2.98% on the CSJ eval1/eval2/eval3 set. Furthermore, the proposed model is more robust than the standard Transformer model, particularly for long-form speech on both the datasets. For the TTS task, the proposed method outperforms the Transformer baseline.
Leveraging supplementary text data to kick-start automatic speech recognition system development with limited transcriptions
Feb 09, 2023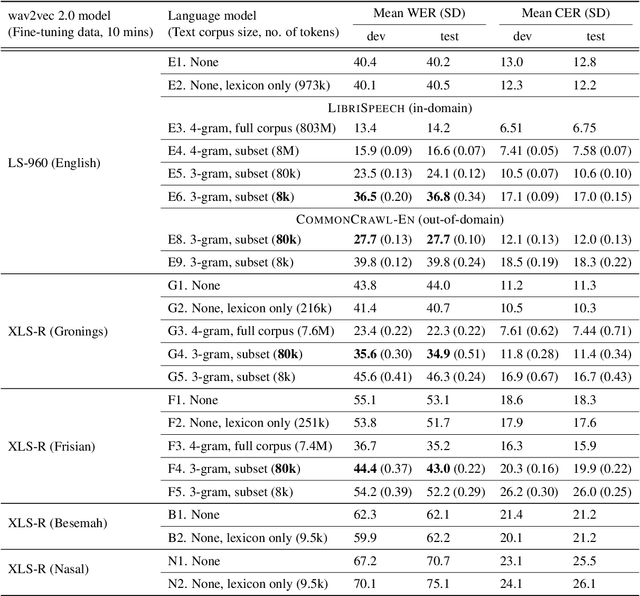
Recent research using pre-trained transformer models suggests that just 10 minutes of transcribed speech may be enough to fine-tune such a model for automatic speech recognition (ASR) -- at least if we can also leverage vast amounts of text data (803 million tokens). But is that much text data necessary? We study the use of different amounts of text data, both for creating a lexicon that constrains ASR decoding to possible words (e.g. *dogz vs. dogs), and for training larger language models that bias the system toward probable word sequences (e.g. too dogs vs. two dogs). We perform experiments using 10 minutes of transcribed speech from English (for replicating prior work) and two additional pairs of languages differing in the availability of supplemental text data: Gronings and Frisian (~7.5M token corpora available), and Besemah and Nasal (only small lexica available). For all languages, we found that using only a lexicon did not appreciably improve ASR performance. For Gronings and Frisian, we found that lexica and language models derived from 'novel-length' 80k token subcorpora reduced the word error rate (WER) to 39% on average. Our findings suggest that where a text corpus in the upper tens of thousands of tokens or more is available, fine-tuning a transformer model with just tens of minutes of transcribed speech holds some promise towards obtaining human-correctable transcriptions near the 30% WER rule-of-thumb.
LyricWhiz: Robust Multilingual Zero-shot Lyrics Transcription by Whispering to ChatGPT
Jun 29, 2023

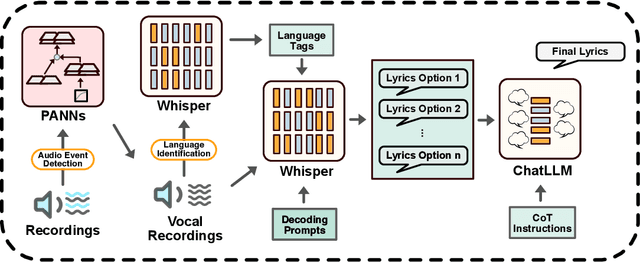
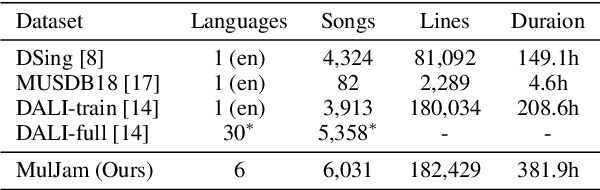
We introduce LyricWhiz, a robust, multilingual, and zero-shot automatic lyrics transcription method achieving state-of-the-art performance on various lyrics transcription datasets, even in challenging genres such as rock and metal. Our novel, training-free approach utilizes Whisper, a weakly supervised robust speech recognition model, and GPT-4, today's most performant chat-based large language model. In the proposed method, Whisper functions as the "ear" by transcribing the audio, while GPT-4 serves as the "brain," acting as an annotator with a strong performance for contextualized output selection and correction. Our experiments show that LyricWhiz significantly reduces Word Error Rate compared to existing methods in English and can effectively transcribe lyrics across multiple languages. Furthermore, we use LyricWhiz to create the first publicly available, large-scale, multilingual lyrics transcription dataset with a CC-BY-NC-SA copyright license, based on MTG-Jamendo, and offer a human-annotated subset for noise level estimation and evaluation. We anticipate that our proposed method and dataset will advance the development of multilingual lyrics transcription, a challenging and emerging task.
Improving Hypernasality Estimation with Automatic Speech Recognition in Cleft Palate Speech
Aug 10, 2022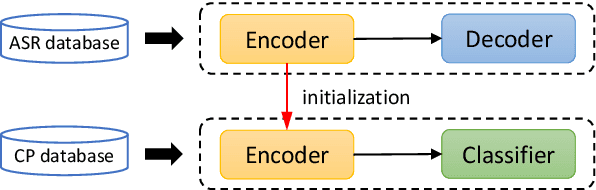
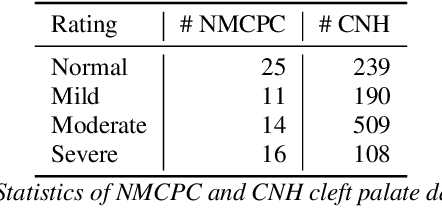
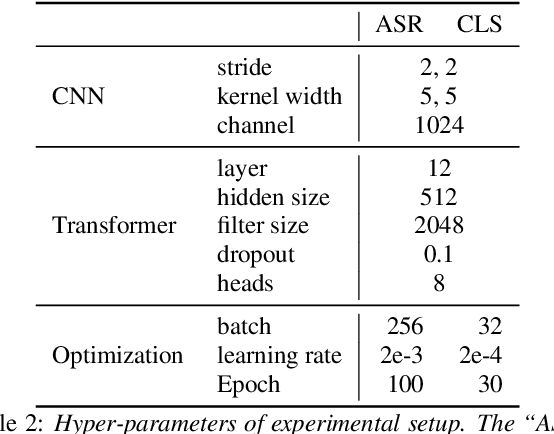
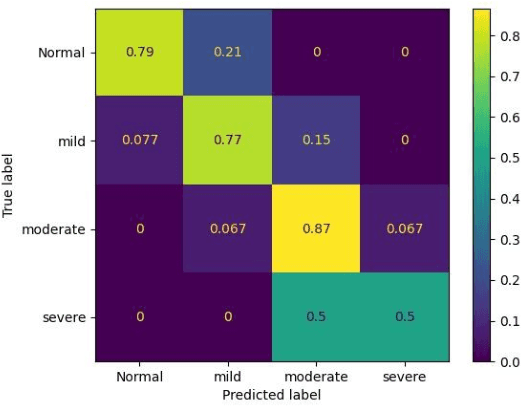
Hypernasality is an abnormal resonance in human speech production, especially in patients with craniofacial anomalies such as cleft palate. In clinical application, hypernasality estimation is crucial in cleft palate diagnosis, as its results determine the subsequent surgery and additional speech therapy. Therefore, designing an automatic hypernasality assessment method will facilitate speech-language pathologists to make precise diagnoses. Existing methods for hypernasality estimation only conduct acoustic analysis based on low-resource cleft palate dataset, by using statistical or neural network-based features. In this paper, we propose a novel approach that uses automatic speech recognition model to improve hypernasality estimation. Specifically, we first pre-train an encoder-decoder framework in an automatic speech recognition (ASR) objective by using speech-to-text dataset, and then fine-tune ASR encoder on the cleft palate dataset for hypernasality estimation. Benefiting from such design, our model for hypernasality estimation can enjoy the advantages of ASR model: 1) compared with low-resource cleft palate dataset, the ASR task usually includes large-scale speech data in the general domain, which enables better model generalization; 2) the text annotations in ASR dataset guide model to extract better acoustic features. Experimental results on two cleft palate datasets demonstrate that our method achieves superior performance compared with previous approaches.
TrustSER: On the Trustworthiness of Fine-tuning Pre-trained Speech Embeddings For Speech Emotion Recognition
May 18, 2023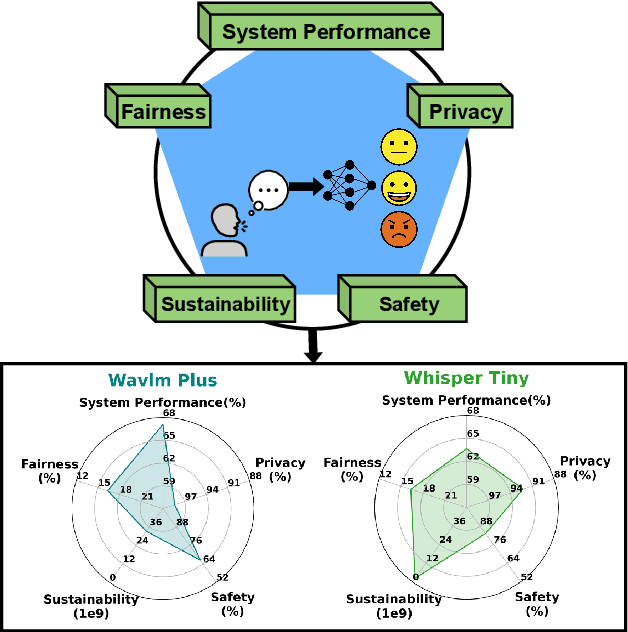


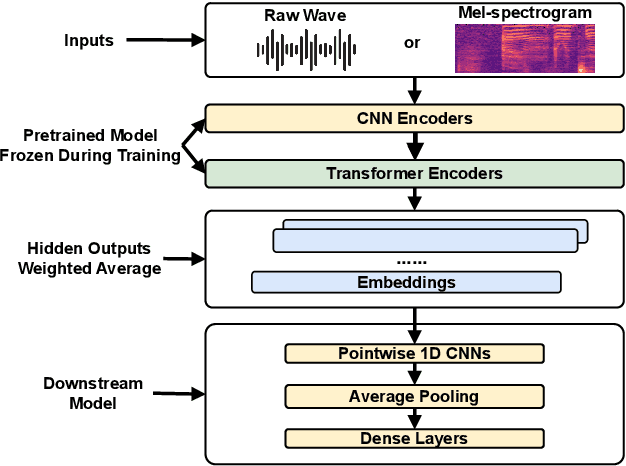
Recent studies have explored the use of pre-trained embeddings for speech emotion recognition (SER), achieving comparable performance to conventional methods that rely on low-level knowledge-inspired acoustic features. These embeddings are often generated from models trained on large-scale speech datasets using self-supervised or weakly-supervised learning objectives. Despite the significant advancements made in SER through the use of pre-trained embeddings, there is a limited understanding of the trustworthiness of these methods, including privacy breaches, unfair performance, vulnerability to adversarial attacks, and computational cost, all of which may hinder the real-world deployment of these systems. In response, we introduce TrustSER, a general framework designed to evaluate the trustworthiness of SER systems using deep learning methods, with a focus on privacy, safety, fairness, and sustainability, offering unique insights into future research in the field of SER. Our code is publicly available under: https://github.com/usc-sail/trust-ser.
Strategies in Transfer Learning for Low-Resource Speech Synthesis: Phone Mapping, Features Input, and Source Language Selection
Jun 21, 2023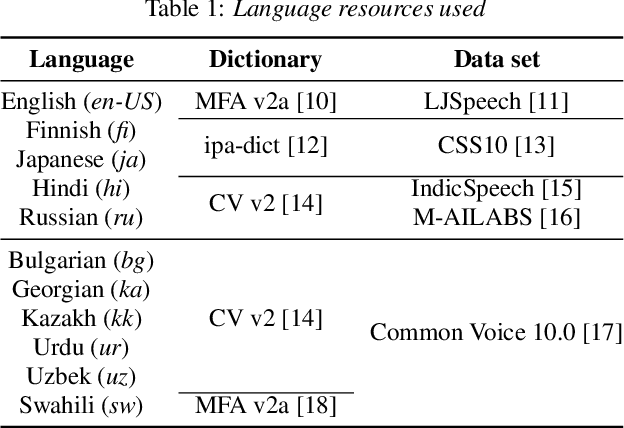
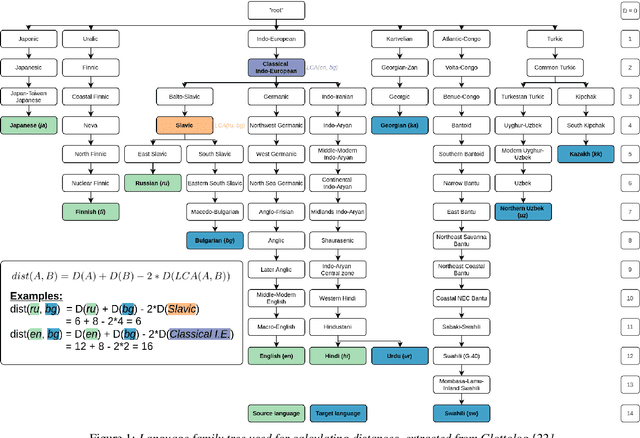

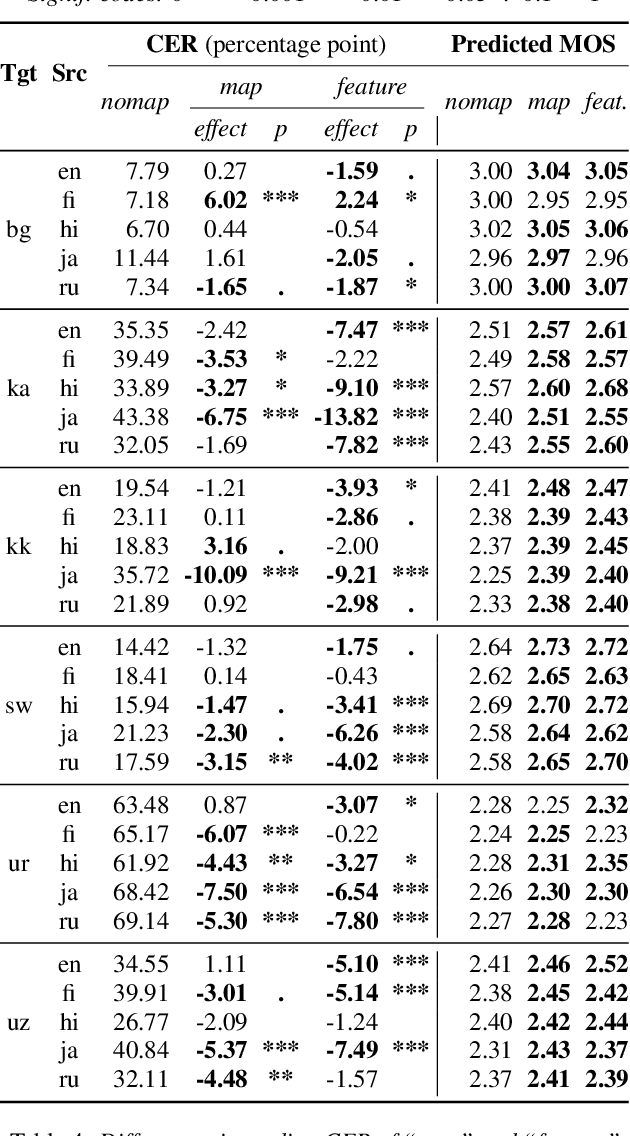
We compare using a PHOIBLE-based phone mapping method and using phonological features input in transfer learning for TTS in low-resource languages. We use diverse source languages (English, Finnish, Hindi, Japanese, and Russian) and target languages (Bulgarian, Georgian, Kazakh, Swahili, Urdu, and Uzbek) to test the language-independence of the methods and enhance the findings' applicability. We use Character Error Rates from automatic speech recognition and predicted Mean Opinion Scores for evaluation. Results show that both phone mapping and features input improve the output quality and the latter performs better, but these effects also depend on the specific language combination. We also compare the recently-proposed Angular Similarity of Phone Frequencies (ASPF) with a family tree-based distance measure as a criterion to select source languages in transfer learning. ASPF proves effective if label-based phone input is used, while the language distance does not have expected effects.
Representation Learning With Hidden Unit Clustering For Low Resource Speech Applications
Jul 14, 2023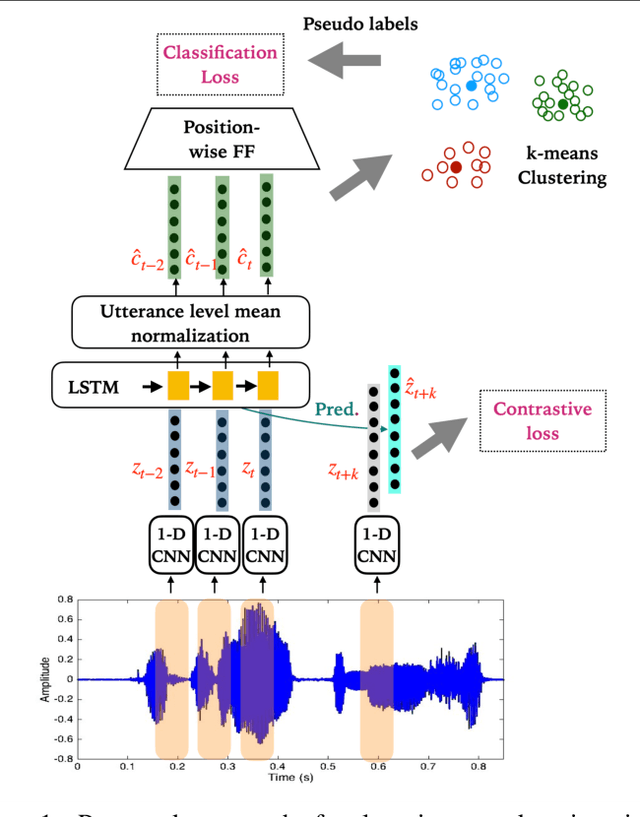
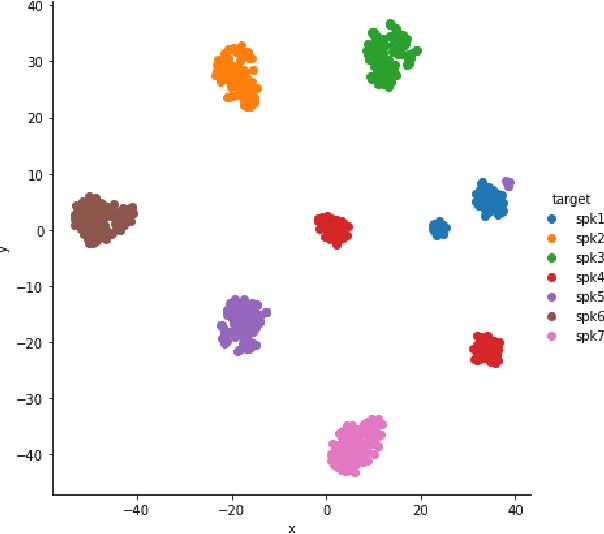
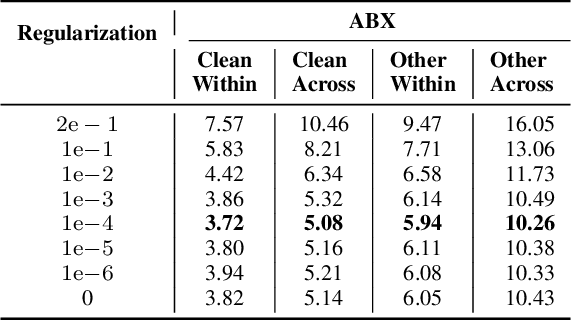
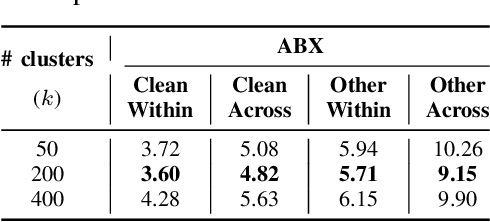
The representation learning of speech, without textual resources, is an area of significant interest for many low resource speech applications. In this paper, we describe an approach to self-supervised representation learning from raw audio using a hidden unit clustering (HUC) framework. The input to the model consists of audio samples that are windowed and processed with 1-D convolutional layers. The learned "time-frequency" representations from the convolutional neural network (CNN) module are further processed with long short term memory (LSTM) layers which generate a contextual vector representation for every windowed segment. The HUC framework, allowing the categorization of the representations into a small number of phoneme-like units, is used to train the model for learning semantically rich speech representations. The targets consist of phoneme-like pseudo labels for each audio segment and these are generated with an iterative k-means algorithm. We explore techniques that improve the speaker invariance of the learned representations and illustrate the effectiveness of the proposed approach on two settings, i) completely unsupervised speech applications on the sub-tasks described as part of the ZeroSpeech 2021 challenge and ii) semi-supervised automatic speech recognition (ASR) applications on the TIMIT dataset and on the GramVaani challenge Hindi dataset. In these experiments, we achieve state-of-art results for various ZeroSpeech tasks. Further, on the ASR experiments, the HUC representations are shown to improve significantly over other established benchmarks based on Wav2vec, HuBERT and Best-RQ.