 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Byte-level Representation for End-to-end ASR
Jun 14, 2024We propose a novel approach to optimizing a byte-level representation for end-to-end automatic speech recognition (ASR). Byte-level representation is often used by large scale multilingual ASR systems when the character set of the supported languages is large. The compactness and universality of byte-level representation allow the ASR models to use smaller output vocabularies and therefore, provide more flexibility. UTF-8 is a commonly used byte-level representation for multilingual ASR, but it is not designed to optimize machine learning tasks directly. By using auto-encoder and vector quantization, we show that we can optimize a byte-level representation for ASR and achieve better accuracy. Our proposed framework can incorporate information from different modalities, and provides an error correction mechanism. In an English/Mandarin dictation task, we show that a bilingual ASR model built with this approach can outperform UTF-8 representation by 5% relative in error rate.
Personalization of CTC-based End-to-End Speech Recognition Using Pronunciation-Driven Subword Tokenization
Oct 16, 2023



Recent advances in deep learning and automatic speech recognition have improved the accuracy of end-to-end speech recognition systems, but recognition of personal content such as contact names remains a challenge. In this work, we describe our personalization solution for an end-to-end speech recognition system based on connectionist temporal classification. Building on previous work, we present a novel method for generating additional subword tokenizations for personal entities from their pronunciations. We show that using this technique in combination with two established techniques, contextual biasing and wordpiece prior normalization, we are able to achieve personal named entity accuracy on par with a competitive hybrid system.
Variable Attention Masking for Configurable Transformer Transducer Speech Recognition
Nov 02, 2022



This work studies the use of attention masking in transformer transducer based speech recognition for building a single configurable model for different deployment scenarios. We present a comprehensive set of experiments comparing fixed masking, where the same attention mask is applied at every frame, with chunked masking, where the attention mask for each frame is determined by chunk boundaries, in terms of recognition accuracy and latency. We then explore the use of variable masking, where the attention masks are sampled from a target distribution at training time, to build models that can work in different configurations. Finally, we investigate how a single configurable model can be used to perform both first pass streaming recognition and second pass acoustic rescoring. Experiments show that chunked masking achieves a better accuracy vs latency trade-off compared to fixed masking, both with and without FastEmit. We also show that variable masking improves the accuracy by up to 8% relative in the acoustic re-scoring scenario.
Online Automatic Speech Recognition with Listen, Attend and Spell Model
Aug 12, 2020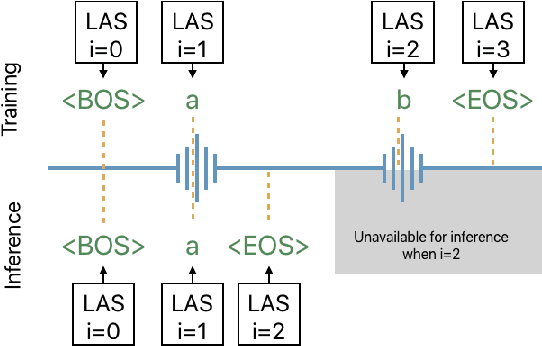
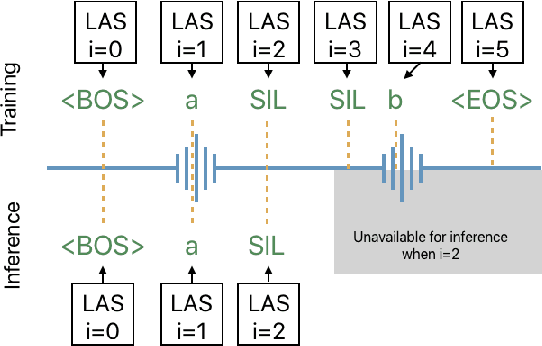
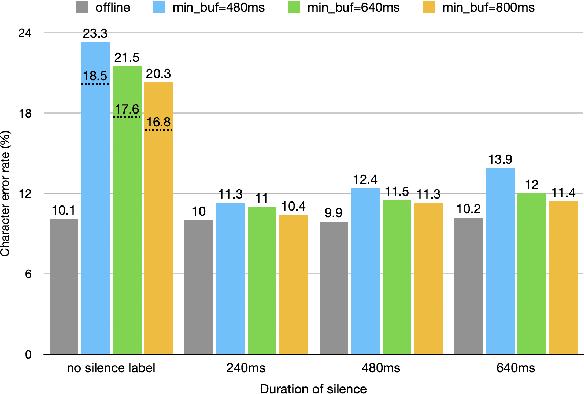
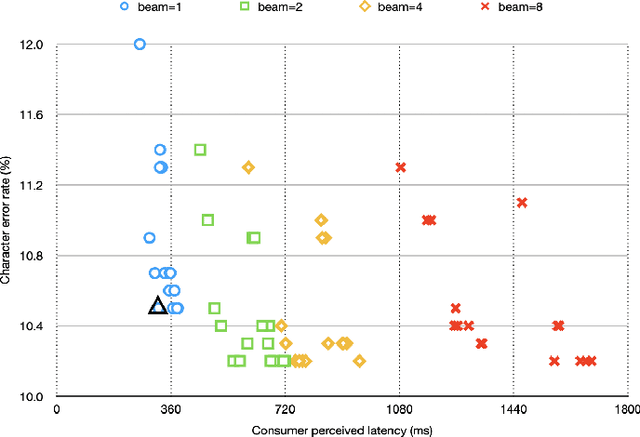
The Listen, Attend and Spell (LAS) model and other attention-based automatic speech recognition (ASR) models have known limitations when operated in a fully online mode. In this paper, we analyze the online operation of LAS models to demonstrate that these limitations stem from the handling of silence regions and the reliability of online attention mechanism at the edge of input buffers. We propose a novel and simple technique that can achieve fully online recognition while meeting accuracy and latency targets. For the Mandarin dictation task, our proposed approach can achieve a character error rate in online operation that is within 4% relative to an offline LAS model. The proposed online LAS model operates at 12% lower latency relative to a conventional neural network hidden Markov model hybrid of comparable accuracy. We have validated the proposed method through a production scale deployment, which, to the best of our knowledge, is the first such deployment of a fully online LAS model.
Multimodal Representation Learning using Deep Multiset Canonical Correlation
Apr 03, 2019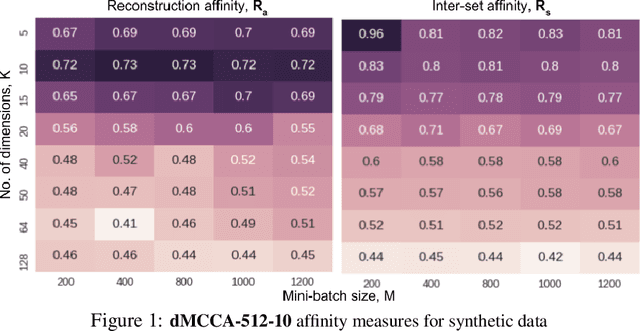
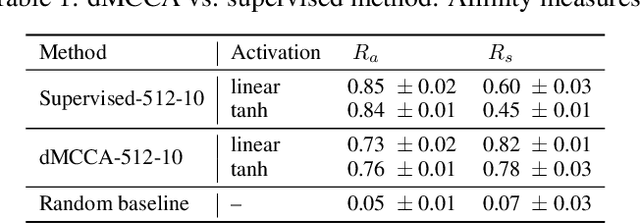
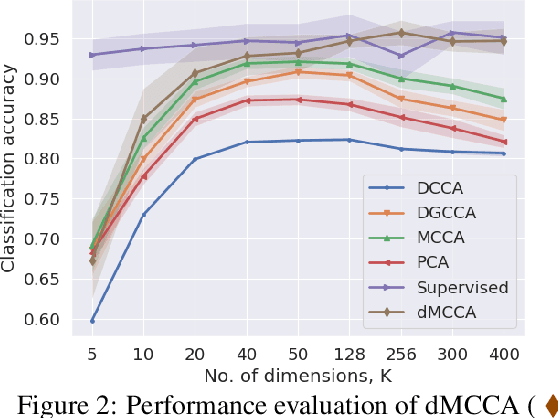
We propose Deep Multiset Canonical Correlation Analysis (dMCCA) as an extension to representation learning using CCA when the underlying signal is observed across multiple (more than two) modalities. We use deep learning framework to learn non-linear transformations from different modalities to a shared subspace such that the representations maximize the ratio of between- and within-modality covariance of the observations. Unlike linear discriminant analysis, we do not need class information to learn these representations, and we show that this model can be trained for complex data using mini-batches. Using synthetic data experiments, we show that dMCCA can effectively recover the common signal across the different modalities corrupted by multiplicative and additive noise. We also analyze the sensitivity of our model to recover the correlated components with respect to mini-batch size and dimension of the embeddings. Performance evaluation on noisy handwritten datasets shows that our model outperforms other CCA-based approaches and is comparable to deep neural network models trained end-to-end on this dataset.