 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSarcasmMiner: A Dual-Track Post-Training Framework for Robust Audio-Visual Sarcasm Reasoning
Mar 05, 2026Multimodal sarcasm detection requires resolving pragmatic incongruity across textual, acoustic, and visual cues through cross-modal reasoning. To enable robust sarcasm reasoning with foundation models, we propose SarcasmMiner, a reinforcement learning based post-training framework that resists hallucination in multimodal reasoning. We reformulate sarcasm detection as structured reasoning and adopt a dual-track distillation strategy: high-quality teacher trajectories initialize the student model, while the full set of trajectories trains a generative reward model (GenRM) to evaluate reasoning quality. The student is optimized with group relative policy optimization (GRPO) using decoupled rewards for accuracy and reasoning quality. On MUStARD++, SarcasmMiner increases F1 from 59.83% (zero-shot), 68.23% (supervised finetuning) to 70.22%. These findings suggest that reasoning-aware reward modeling enhances both performance and multimodal grounding.
Making Machines Sound Sarcastic: LLM-Enhanced and Retrieval-Guided Sarcastic Speech Synthesis
Oct 08, 2025


Sarcasm is a subtle form of non-literal language that poses significant challenges for speech synthesis due to its reliance on nuanced semantic, contextual, and prosodic cues. While existing speech synthesis research has focused primarily on broad emotional categories, sarcasm remains largely unexplored. In this paper, we propose a Large Language Model (LLM)-enhanced Retrieval-Augmented framework for sarcasm-aware speech synthesis. Our approach combines (1) semantic embeddings from a LoRA-fine-tuned LLaMA 3, which capture pragmatic incongruity and discourse-level cues of sarcasm, and (2) prosodic exemplars retrieved via a Retrieval Augmented Generation (RAG) module, which provide expressive reference patterns of sarcastic delivery. Integrated within a VITS backbone, this dual conditioning enables more natural and contextually appropriate sarcastic speech. Experiments demonstrate that our method outperforms baselines in both objective measures and subjective evaluations, yielding improvements in speech naturalness, sarcastic expressivity, and downstream sarcasm detection.
Spoken in Jest, Detected in Earnest: A Systematic Review of Sarcasm Recognition -- Multimodal Fusion, Challenges, and Future Prospects
Sep 04, 2025



Sarcasm, a common feature of human communication, poses challenges in interpersonal interactions and human-machine interactions. Linguistic research has highlighted the importance of prosodic cues, such as variations in pitch, speaking rate, and intonation, in conveying sarcastic intent. Although previous work has focused on text-based sarcasm detection, the role of speech data in recognizing sarcasm has been underexplored. Recent advancements in speech technology emphasize the growing importance of leveraging speech data for automatic sarcasm recognition, which can enhance social interactions for individuals with neurodegenerative conditions and improve machine understanding of complex human language use, leading to more nuanced interactions. This systematic review is the first to focus on speech-based sarcasm recognition, charting the evolution from unimodal to multimodal approaches. It covers datasets, feature extraction, and classification methods, and aims to bridge gaps across diverse research domains. The findings include limitations in datasets for sarcasm recognition in speech, the evolution of feature extraction techniques from traditional acoustic features to deep learning-based representations, and the progression of classification methods from unimodal approaches to multimodal fusion techniques. In so doing, we identify the need for greater emphasis on cross-cultural and multilingual sarcasm recognition, as well as the importance of addressing sarcasm as a multimodal phenomenon, rather than a text-based challenge.
Evaluating Standard and Dialectal Frisian ASR: Multilingual Fine-tuning and Language Identification for Improved Low-resource Performance
Feb 07, 2025



Automatic Speech Recognition (ASR) performance for low-resource languages is still far behind that of higher-resource languages such as English, due to a lack of sufficient labeled data. State-of-the-art methods deploy self-supervised transfer learning where a model pre-trained on large amounts of data is fine-tuned using little labeled data in a target low-resource language. In this paper, we present and examine a method for fine-tuning an SSL-based model in order to improve the performance for Frisian and its regional dialects (Clay Frisian, Wood Frisian, and South Frisian). We show that Frisian ASR performance can be improved by using multilingual (Frisian, Dutch, English and German) fine-tuning data and an auxiliary language identification task. In addition, our findings show that performance on dialectal speech suffers substantially, and, importantly, that this effect is moderated by the elicitation approach used to collect the dialectal data. Our findings also particularly suggest that relying solely on standard language data for ASR evaluation may underestimate real-world performance, particularly in languages with substantial dialectal variation.
AMuSeD: An Attentive Deep Neural Network for Multimodal Sarcasm Detection Incorporating Bi-modal Data Augmentation
Dec 13, 2024



Detecting sarcasm effectively requires a nuanced understanding of context, including vocal tones and facial expressions. The progression towards multimodal computational methods in sarcasm detection, however, faces challenges due to the scarcity of data. To address this, we present AMuSeD (Attentive deep neural network for MUltimodal Sarcasm dEtection incorporating bi-modal Data augmentation). This approach utilizes the Multimodal Sarcasm Detection Dataset (MUStARD) and introduces a two-phase bimodal data augmentation strategy. The first phase involves generating varied text samples through Back Translation from several secondary languages. The second phase involves the refinement of a FastSpeech 2-based speech synthesis system, tailored specifically for sarcasm to retain sarcastic intonations. Alongside a cloud-based Text-to-Speech (TTS) service, this Fine-tuned FastSpeech 2 system produces corresponding audio for the text augmentations. We also investigate various attention mechanisms for effectively merging text and audio data, finding self-attention to be the most efficient for bimodal integration. Our experiments reveal that this combined augmentation and attention approach achieves a significant F1-score of 81.0% in text-audio modalities, surpassing even models that use three modalities from the MUStARD dataset.
A Functional Trade-off between Prosodic and Semantic Cues in Conveying Sarcasm
Aug 27, 2024



This study investigates the acoustic features of sarcasm and disentangles the interplay between the propensity of an utterance being used sarcastically and the presence of prosodic cues signaling sarcasm. Using a dataset of sarcastic utterances compiled from television shows, we analyze the prosodic features within utterances and key phrases belonging to three distinct sarcasm categories (embedded, propositional, and illocutionary), which vary in the degree of semantic cues present, and compare them to neutral expressions. Results show that in phrases where the sarcastic meaning is salient from the semantics, the prosodic cues are less relevant than when the sarcastic meaning is not evident from the semantics, suggesting a trade-off between prosodic and semantic cues of sarcasm at the phrase level. These findings highlight a lessened reliance on prosodic modulation in semantically dense sarcastic expressions and a nuanced interaction that shapes the communication of sarcastic intent.
Meta Learning Text-to-Speech Synthesis in over 7000 Languages
Jun 10, 2024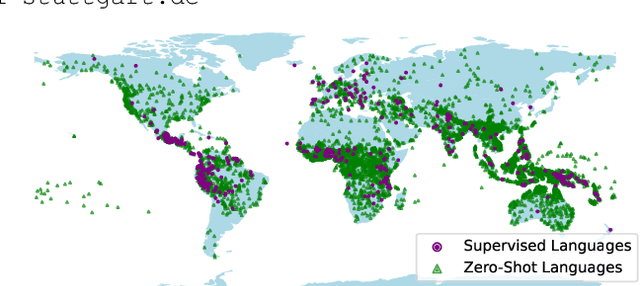
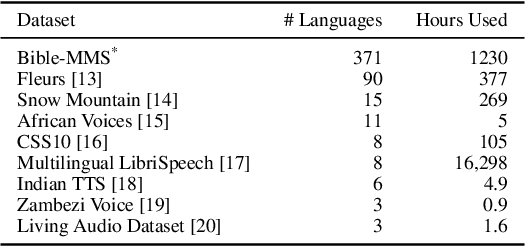
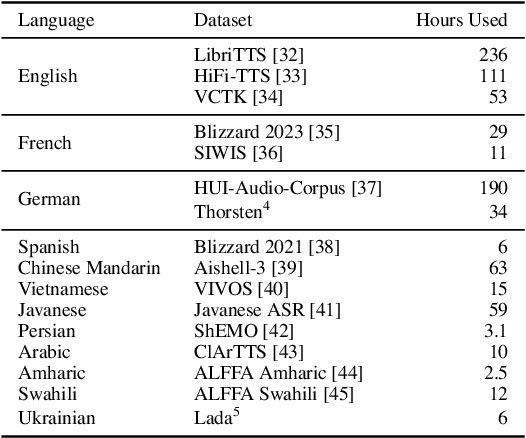
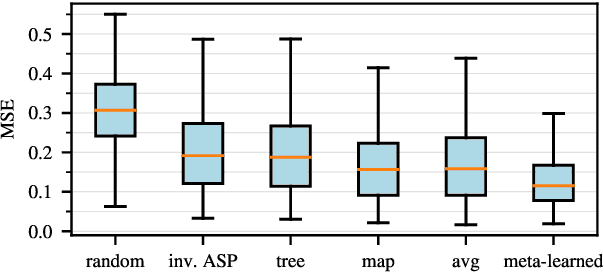
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.
Strategies in Transfer Learning for Low-Resource Speech Synthesis: Phone Mapping, Features Input, and Source Language Selection
Jun 21, 2023



We compare using a PHOIBLE-based phone mapping method and using phonological features input in transfer learning for TTS in low-resource languages. We use diverse source languages (English, Finnish, Hindi, Japanese, and Russian) and target languages (Bulgarian, Georgian, Kazakh, Swahili, Urdu, and Uzbek) to test the language-independence of the methods and enhance the findings' applicability. We use Character Error Rates from automatic speech recognition and predicted Mean Opinion Scores for evaluation. Results show that both phone mapping and features input improve the output quality and the latter performs better, but these effects also depend on the specific language combination. We also compare the recently-proposed Angular Similarity of Phone Frequencies (ASPF) with a family tree-based distance measure as a criterion to select source languages in transfer learning. ASPF proves effective if label-based phone input is used, while the language distance does not have expected effects.
The Effects of Input Type and Pronunciation Dictionary Usage in Transfer Learning for Low-Resource Text-to-Speech
Jun 01, 2023


We compare phone labels and articulatory features as input for cross-lingual transfer learning in text-to-speech (TTS) for low-resource languages (LRLs). Experiments with FastSpeech 2 and the LRL West Frisian show that using articulatory features outperformed using phone labels in both intelligibility and naturalness. For LRLs without pronunciation dictionaries, we propose two novel approaches: a) using a massively multilingual model to convert grapheme-to-phone (G2P) in both training and synthesizing, and b) using a universal phone recognizer to create a makeshift dictionary. Results show that the G2P approach performs largely on par with using a ground-truth dictionary and the phone recognition approach, while performing generally worse, remains a viable option for LRLs less suitable for the G2P approach. Within each approach, using articulatory features as input outperforms using phone labels.
Resource-Efficient Fine-Tuning Strategies for Automatic MOS Prediction in Text-to-Speech for Low-Resource Languages
May 30, 2023



We train a MOS prediction model based on wav2vec 2.0 using the open-access data sets BVCC and SOMOS. Our test with neural TTS data in the low-resource language (LRL) West Frisian shows that pre-training on BVCC before fine-tuning on SOMOS leads to the best accuracy for both fine-tuned and zero-shot prediction. Further fine-tuning experiments show that using more than 30 percent of the total data does not lead to significant improvements. In addition, fine-tuning with data from a single listener shows promising system-level accuracy, supporting the viability of one-participant pilot tests. These findings can all assist the resource-conscious development of TTS for LRLs by progressing towards better zero-shot MOS prediction and informing the design of listening tests, especially in early-stage evaluation.