 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
DeepMPCVS: Deep Model Predictive Control for Visual Servoing
May 03, 2021
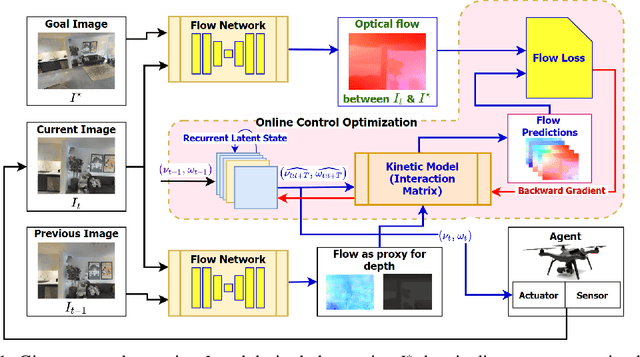
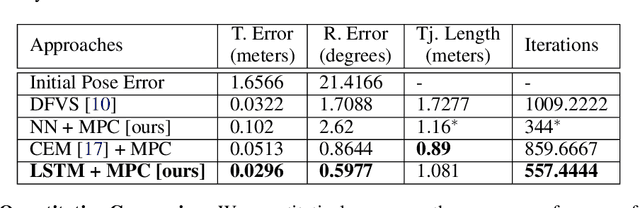

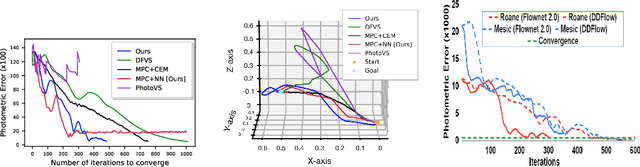
The simplicity of the visual servoing approach makes it an attractive option for tasks dealing with vision-based control of robots in many real-world applications. However, attaining precise alignment for unseen environments pose a challenge to existing visual servoing approaches. While classical approaches assume a perfect world, the recent data-driven approaches face issues when generalizing to novel environments. In this paper, we aim to combine the best of both worlds. We present a deep model predictive visual servoing framework that can achieve precise alignment with optimal trajectories and can generalize to novel environments. Our framework consists of a deep network for optical flow predictions, which are used along with a predictive model to forecast future optical flow. For generating an optimal set of velocities we present a control network that can be trained on the fly without any supervision. Through extensive simulations on photo-realistic indoor settings of the popular Habitat framework, we show significant performance gain due to the proposed formulation vis-a-vis recent state-of-the-art methods. Specifically, we show a faster convergence and an improved performance in trajectory length over recent approaches.
* Accepted at 4th Annual Conference on Robot Learning, CoRL 2020, Cambridge, MA, USA, November 16 - November 18, 2020
Domain Generalization with MixStyle
Apr 05, 2021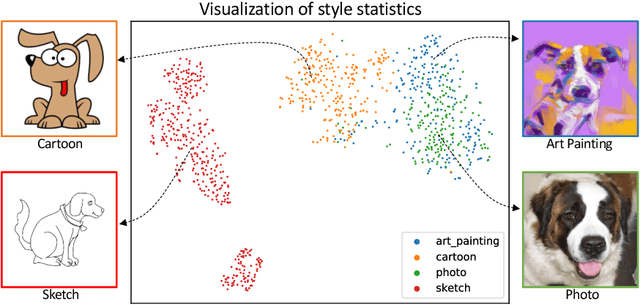
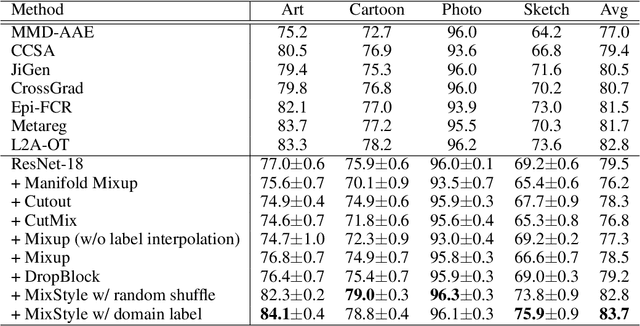
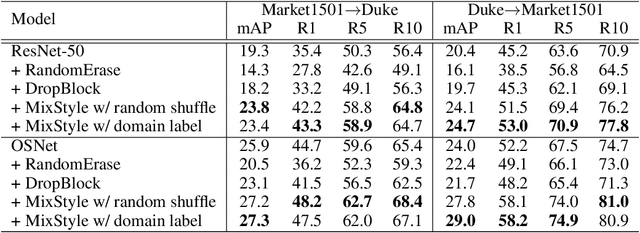
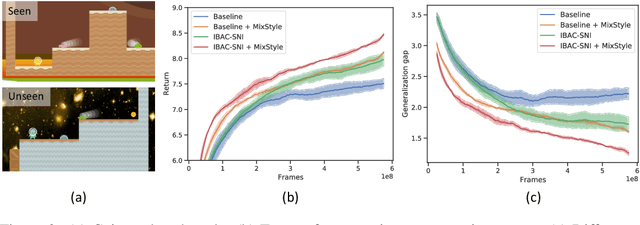
Though convolutional neural networks (CNNs) have demonstrated remarkable ability in learning discriminative features, they often generalize poorly to unseen domains. Domain generalization aims to address this problem by learning from a set of source domains a model that is generalizable to any unseen domain. In this paper, a novel approach is proposed based on probabilistically mixing instance-level feature statistics of training samples across source domains. Our method, termed MixStyle, is motivated by the observation that visual domain is closely related to image style (e.g., photo vs.~sketch images). Such style information is captured by the bottom layers of a CNN where our proposed style-mixing takes place. Mixing styles of training instances results in novel domains being synthesized implicitly, which increase the domain diversity of the source domains, and hence the generalizability of the trained model. MixStyle fits into mini-batch training perfectly and is extremely easy to implement. The effectiveness of MixStyle is demonstrated on a wide range of tasks including category classification, instance retrieval and reinforcement learning.
MAVFI: An End-to-End Fault Analysis Framework with Anomaly Detection and Recovery for Micro Aerial Vehicles
May 27, 2021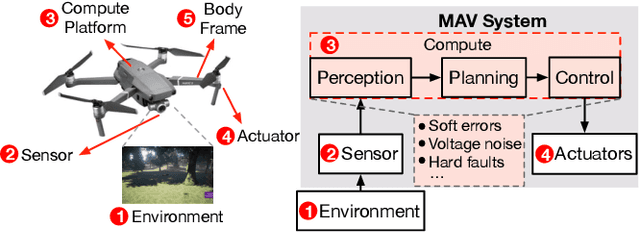

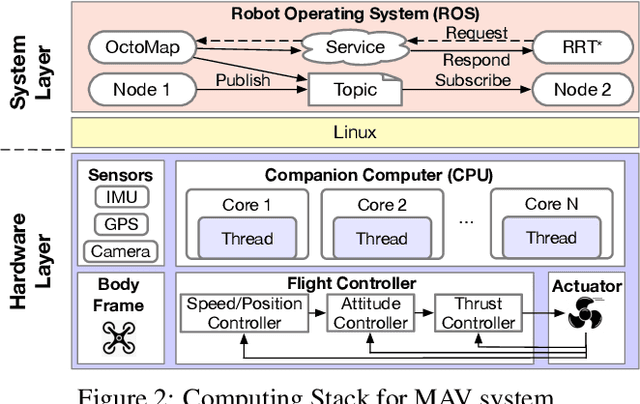
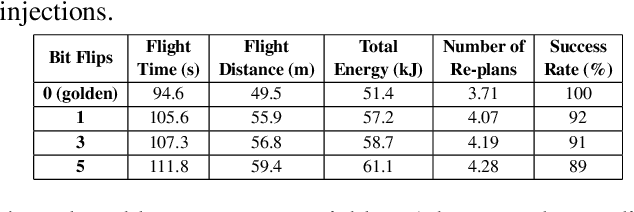
Reliability and safety are critical in autonomous machine services, such as autonomous vehicles and aerial drones. In this paper, we first present an open-source Micro Aerial Vehicles (MAVs) reliability analysis framework, MAVFI, to characterize transient fault's impacts on the end-to-end flight metrics, e.g., flight time, success rate. Based on our framework, it is observed that the end-to-end fault tolerance analysis is essential for characterizing system reliability. We demonstrate the planning and control stages are more vulnerable to transient faults than the visual perception stage in the common "Perception-Planning-Control (PPC)" compute pipeline. Furthermore, to improve the reliability of the MAV system, we propose two low overhead anomaly-based transient fault detection and recovery schemes based on Gaussian statistical models and autoencoder neural networks. We validate our anomaly fault protection schemes with a variety of simulated photo-realistic environments on both Intel i9 CPU and ARM Cortex-A57 on Nvidia TX2 platform. It is demonstrated that the autoencoder-based scheme can improve the system reliability by 100% recovering failure cases with less than 0.0062% computational overhead in best-case scenarios. In addition, MAVFI framework can be used for other ROS-based cyber-physical applications and is open-sourced at https://github.com/harvard-edge/MAVBench/tree/mavfi
Dual Attention GANs for Semantic Image Synthesis
Aug 29, 2020

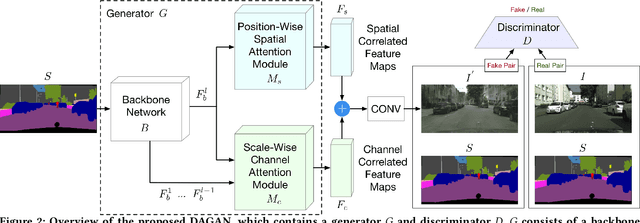
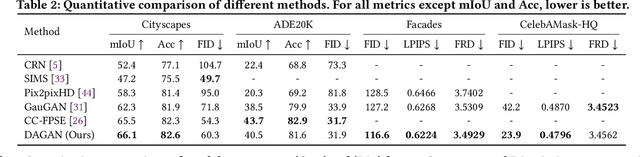
In this paper, we focus on the semantic image synthesis task that aims at transferring semantic label maps to photo-realistic images. Existing methods lack effective semantic constraints to preserve the semantic information and ignore the structural correlations in both spatial and channel dimensions, leading to unsatisfactory blurry and artifact-prone results. To address these limitations, we propose a novel Dual Attention GAN (DAGAN) to synthesize photo-realistic and semantically-consistent images with fine details from the input layouts without imposing extra training overhead or modifying the network architectures of existing methods. We also propose two novel modules, i.e., position-wise Spatial Attention Module (SAM) and scale-wise Channel Attention Module (CAM), to capture semantic structure attention in spatial and channel dimensions, respectively. Specifically, SAM selectively correlates the pixels at each position by a spatial attention map, leading to pixels with the same semantic label being related to each other regardless of their spatial distances. Meanwhile, CAM selectively emphasizes the scale-wise features at each channel by a channel attention map, which integrates associated features among all channel maps regardless of their scales. We finally sum the outputs of SAM and CAM to further improve feature representation. Extensive experiments on four challenging datasets show that DAGAN achieves remarkably better results than state-of-the-art methods, while using fewer model parameters. The source code and trained models are available at https://github.com/Ha0Tang/DAGAN.
Photometric Multi-View Mesh Refinement for High-Resolution Satellite Images
May 12, 2020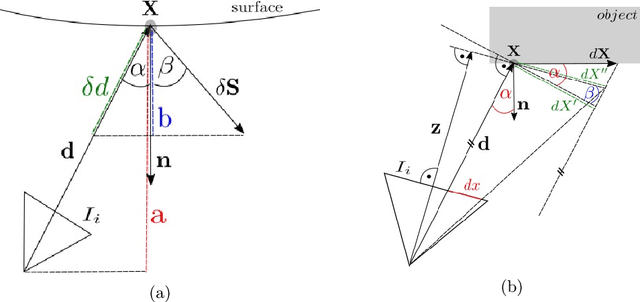
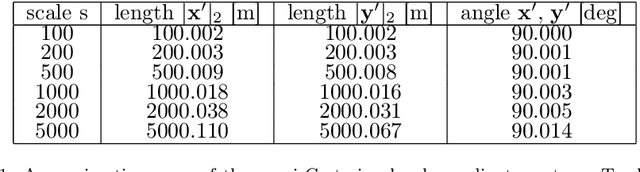

Modern high-resolution satellite sensors collect optical imagery with ground sampling distances (GSDs) of 30-50cm, which has sparked a renewed interest in photogrammetric 3D surface reconstruction from satellite data. State-of-the-art reconstruction methods typically generate 2.5D elevation data. Here, we present an approach to recover full 3D surface meshes from multi-view satellite imagery. The proposed method takes as input a coarse initial mesh and refines it by iteratively updating all vertex positions to maximize the photo-consistency between images. Photo-consistency is measured in image space, by transferring texture from one image to another via the surface. We derive the equations to propagate changes in texture similarity through the rational function model (RFM), often also referred to as rational polynomial coefficient (RPC) model. Furthermore, we devise a hierarchical scheme to optimize the surface with gradient descent. In experiments with two different datasets, we show that the refinement improves the initial digital elevation models (DEMs) generated with conventional dense image matching. Moreover, we demonstrate that our method is able to reconstruct true 3D geometry, such as facade structures, if off-nadir views are available.
NeuTex: Neural Texture Mapping for Volumetric Neural Rendering
Mar 01, 2021
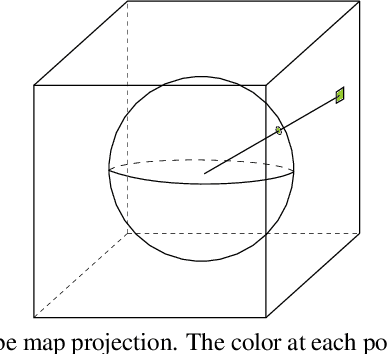
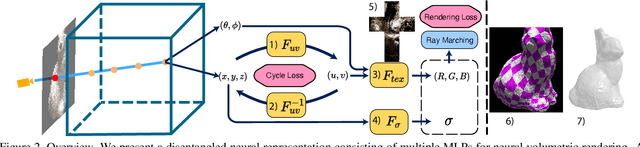
Recent work has demonstrated that volumetric scene representations combined with differentiable volume rendering can enable photo-realistic rendering for challenging scenes that mesh reconstruction fails on. However, these methods entangle geometry and appearance in a "black-box" volume that cannot be edited. Instead, we present an approach that explicitly disentangles geometry--represented as a continuous 3D volume--from appearance--represented as a continuous 2D texture map. We achieve this by introducing a 3D-to-2D texture mapping (or surface parameterization) network into volumetric representations. We constrain this texture mapping network using an additional 2D-to-3D inverse mapping network and a novel cycle consistency loss to make 3D surface points map to 2D texture points that map back to the original 3D points. We demonstrate that this representation can be reconstructed using only multi-view image supervision and generates high-quality rendering results. More importantly, by separating geometry and texture, we allow users to edit appearance by simply editing 2D texture maps.
Spectral Distribution Aware Image Generation
Dec 30, 2020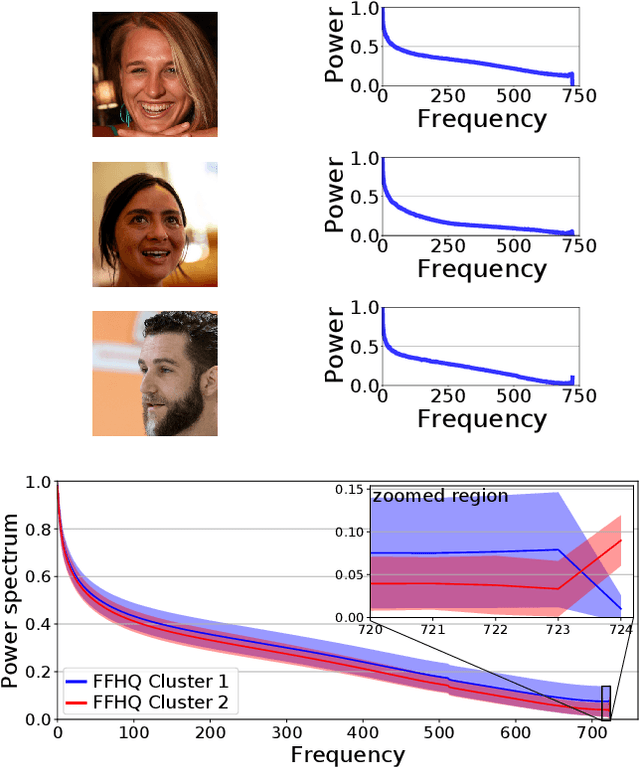
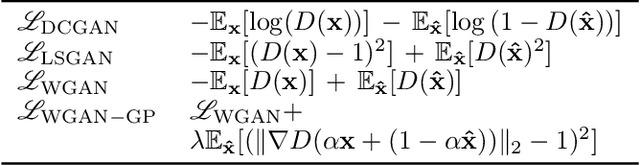
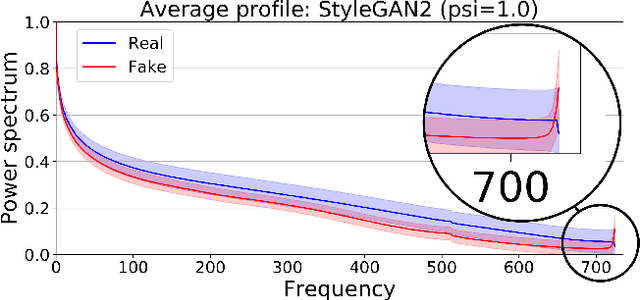
Recent advances in deep generative models for photo-realistic images have led to high quality visual results. Such models learn to generate data from a given training distribution such that generated images can not be easily distinguished from real images by the human eye. Yet, recent work on the detection of such fake images pointed out that they are actually easily distinguishable by artifacts in their frequency spectra. In this paper, we propose to generate images according to the frequency distribution of the real data by employing a spectral discriminator. The proposed discriminator is lightweight, modular and works stably with different commonly used GAN losses. We show that the resulting models can better generate images with realistic frequency spectra, which are thus harder to detect by this cue.
Correction of Chromatic Aberration from a Single Image Using Keypoints
Feb 08, 2020

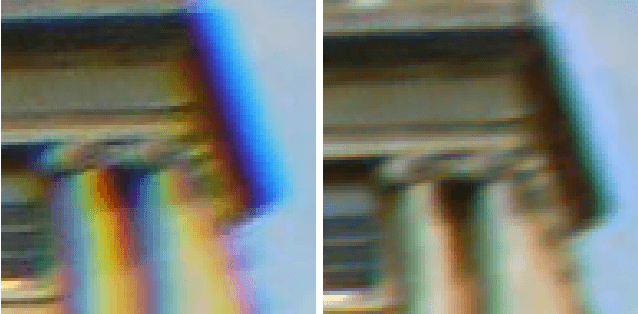
In this paper, we propose a method to correct for chromatic aberration in a single photograph. Our method replicates what a user would do in a photo editing program to account for this defect. We find matching keypoints in each colour channel then align them as a user would.
Lifespan Age Transformation Synthesis
Mar 21, 2020

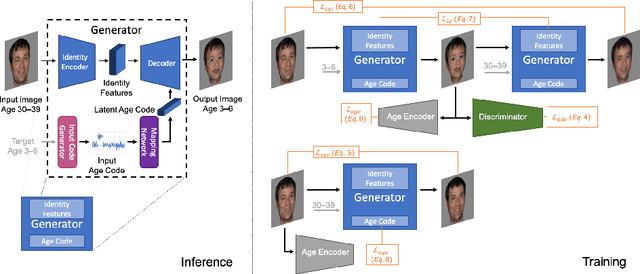
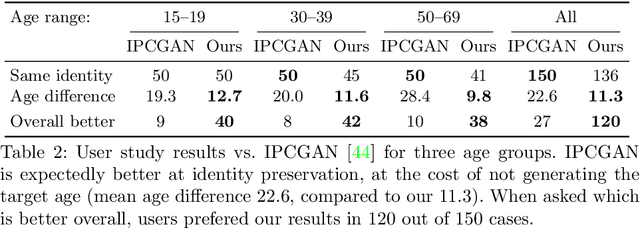
We address the problem of single photo age progression and regression-the prediction of how a person might look in the future, or how they looked in the past. Most existing aging methods are limited to changing the texture, overlooking transformations in head shape that occur during the human aging and growth process. This limits the applicability of previous methods to aging of adults to slightly older adults, and application of those methods to photos of children does not produce quality results. We propose a novel multi-domain image-to-image generative adversarial network architecture, whose learned latent space models a continuous bi-directional aging process. The network is trained on the FFHQ dataset, which we labeled for ages, gender, and semantic segmentation. Fixed age classes are used as anchors to approximate continuous age transformation. Our framework can predict a full head portrait for ages 0-70 from a single photo, modifying both texture and shape of the head. We demonstrate results on a wide variety of photos and datasets, and show significant improvement over the state of the art.
Resolution Dependent GAN Interpolation for Controllable Image Synthesis Between Domains
Oct 20, 2020
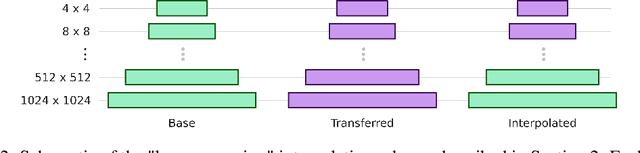


GANs can generate photo-realistic images from the domain of their training data. However, those wanting to use them for creative purposes often want to generate imagery from a truly novel domain, a task which GANs are inherently unable to do. It is also desirable to have a level of control so that there is a degree of artistic direction rather than purely curation of random results. Here we present a method for interpolating between generative models of the StyleGAN architecture in a resolution dependent manner. This allows us to generate images from an entirely novel domain and do this with a degree of control over the nature of the output.