 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Attention GANs for Semantic Image Synthesis
Paper and Code


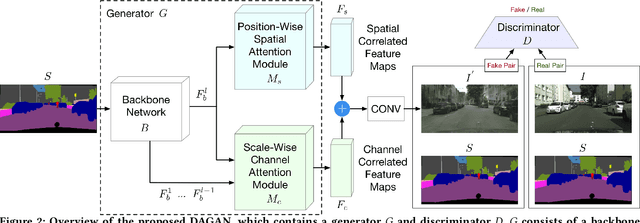
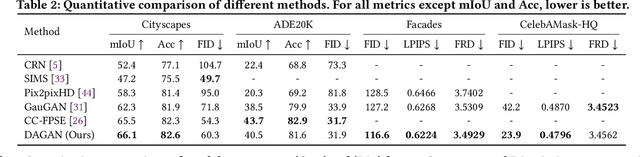
In this paper, we focus on the semantic image synthesis task that aims at transferring semantic label maps to photo-realistic images. Existing methods lack effective semantic constraints to preserve the semantic information and ignore the structural correlations in both spatial and channel dimensions, leading to unsatisfactory blurry and artifact-prone results. To address these limitations, we propose a novel Dual Attention GAN (DAGAN) to synthesize photo-realistic and semantically-consistent images with fine details from the input layouts without imposing extra training overhead or modifying the network architectures of existing methods. We also propose two novel modules, i.e., position-wise Spatial Attention Module (SAM) and scale-wise Channel Attention Module (CAM), to capture semantic structure attention in spatial and channel dimensions, respectively. Specifically, SAM selectively correlates the pixels at each position by a spatial attention map, leading to pixels with the same semantic label being related to each other regardless of their spatial distances. Meanwhile, CAM selectively emphasizes the scale-wise features at each channel by a channel attention map, which integrates associated features among all channel maps regardless of their scales. We finally sum the outputs of SAM and CAM to further improve feature representation. Extensive experiments on four challenging datasets show that DAGAN achieves remarkably better results than state-of-the-art methods, while using fewer model parameters. The source code and trained models are available at https://github.com/Ha0Tang/DAGAN.