 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
SHREC 2020 track: 6D Object Pose Estimation
Oct 19, 2020

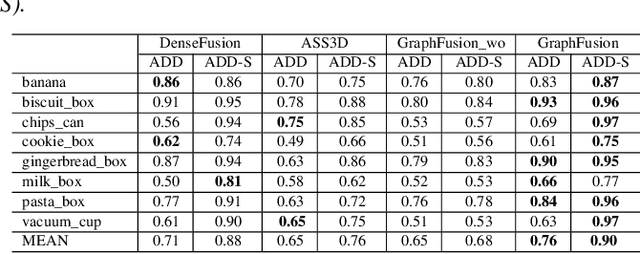
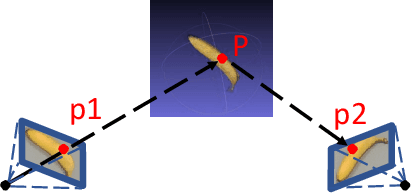
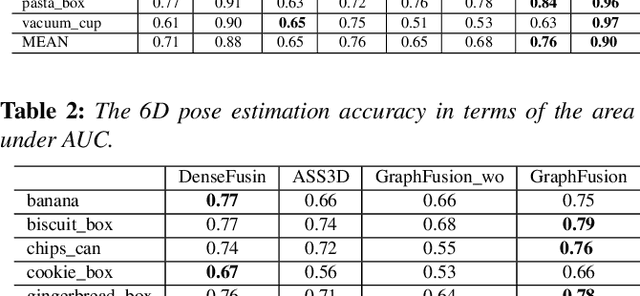
6D pose estimation is crucial for augmented reality, virtual reality, robotic manipulation and visual navigation. However, the problem is challenging due to the variety of objects in the real world. They have varying 3D shape and their appearances in captured images are affected by sensor noise, changing lighting conditions and occlusions between objects. Different pose estimation methods have different strengths and weaknesses, depending on feature representations and scene contents. At the same time, existing 3D datasets that are used for data-driven methods to estimate 6D poses have limited view angles and low resolution. To address these issues, we organize the Shape Retrieval Challenge benchmark on 6D pose estimation and create a physically accurate simulator that is able to generate photo-realistic color-and-depth image pairs with corresponding ground truth 6D poses. From captured color and depth images, we use this simulator to generate a 3D dataset which has 400 photo-realistic synthesized color-and-depth image pairs with various view angles for training, and another 100 captured and synthetic images for testing. Five research groups register in this track and two of them submitted their results. Data-driven methods are the current trend in 6D object pose estimation and our evaluation results show that approaches which fully exploit the color and geometric features are more robust for 6D pose estimation of reflective and texture-less objects and occlusion. This benchmark and comparative evaluation results have the potential to further enrich and boost the research of 6D object pose estimation and its applications.
DVG-Face: Dual Variational Generation for Heterogeneous Face Recognition
Sep 20, 2020

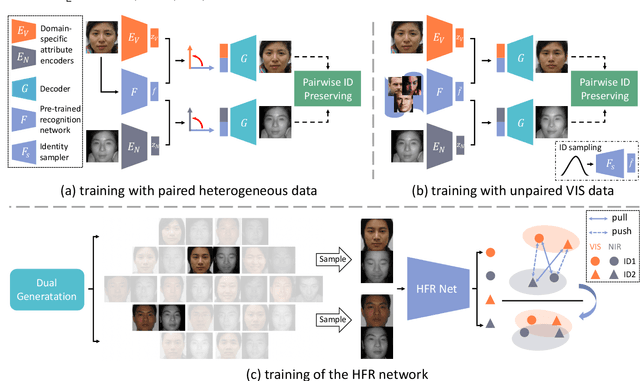
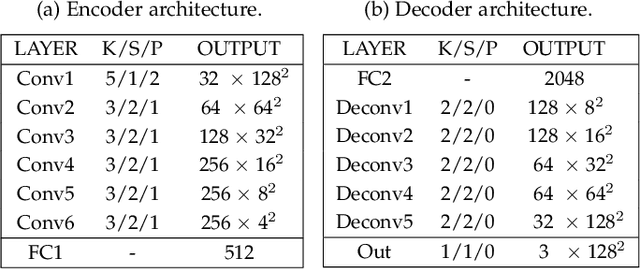
Heterogeneous Face Recognition (HFR) refers to matching cross-domain faces, playing a crucial role in public security. Nevertheless, HFR is confronted with the challenges from large domain discrepancy and insufficient heterogeneous data. In this paper, we formulate HFR as a dual generation problem, and tackle it via a novel Dual Variational Generation (DVG-Face) framework. Specifically, a dual variational generator is elaborately designed to learn the joint distribution of paired heterogeneous images. However, the small-scale paired heterogeneous training data may limit the identity diversity of sampling. With this in mind, we propose to integrate abundant identity information of large-scale VIS images into the joint distribution. Furthermore, a pairwise identity preserving loss is imposed on the generated paired heterogeneous images to ensure their identity consistency. As a consequence, massive new diverse paired heterogeneous images with the same identity can be generated from noises. The identity consistency and diversity properties allow us to employ these generated images to train the HFR network via a contrastive learning mechanism, yielding both domain invariant and discriminative embedding features. Concretely, the generated paired heterogeneous images are regarded as positive pairs, and the images obtained from different samplings are considered as negative pairs. Our method achieves superior performances over state-of-the-art methods on seven databases belonging to five HFR tasks, including NIR-VIS, Sketch-Photo, Profile-Frontal Photo, Thermal-VIS, and ID-Camera. The related code will be released at https://github.com/BradyFU.
A Split-face Study of Novel Robotic Prototype vs Human Operator in Skin Rejuvenation Using Q-switched Nd:Yag Laser: Accuracy, Efficacy and Safety
Jun 05, 2021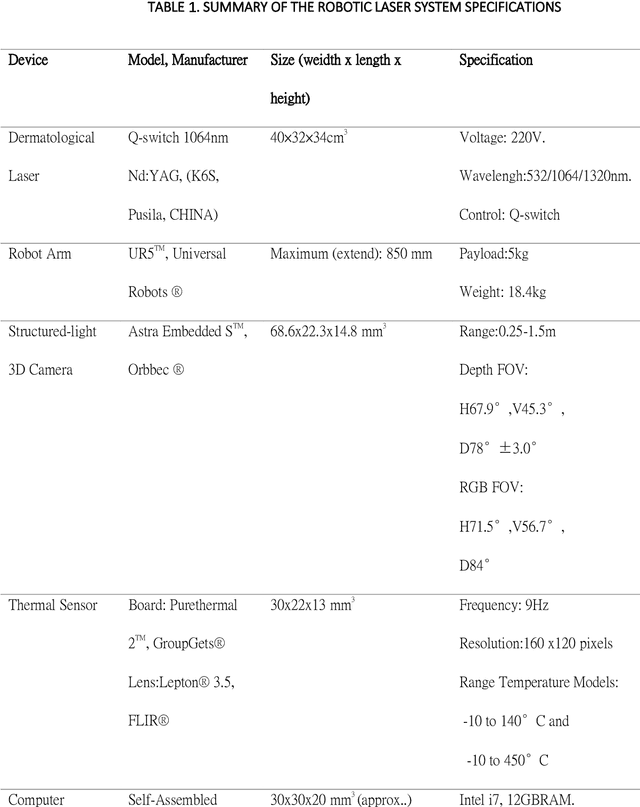
Background: Robotic technologies involved in skin laser are emerging. Objective: To compare the accuracy, efficacy and safety of novel robotic prototype with human operator in laser operation performance for skin photo-rejuvenation. Methods: Seventeen subjects were enrolled in a prospective, comparative split-face trial. Q-switch 1064nm laser conducted by the robotic prototype was provided on the right side of the face and that by the professional practitioner on the left. Each subject underwent a single time, one-pass, non-overlapped treatment on an equal size area of the forehead and cheek. Objective assessments included: treatment duration, laser irradiation shots, laser coverage percentage, VISIA parameters, skin temperature and the VAS pain scale. Results: Average time taken by robotic manipulator was longer than human operator; the average number of irradiation shots of both sides had no significant differences. Laser coverage rate of robotic manipulator (60.2 +-15.1%) was greater than that of human operator (43.6 +-12.9%). The VISIA parameters showed no significant differences between robotic manipulator and human operator. No short or long-term side effects were observed with maximum VAS score of 1 point. Limitations: Only one section of laser treatment was performed. Conclusion: Laser operation by novel robotic prototype is more reliable, stable and accurate than human operation.
Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control
Jun 03, 2021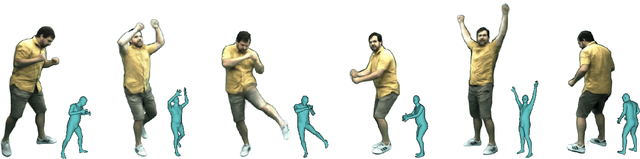
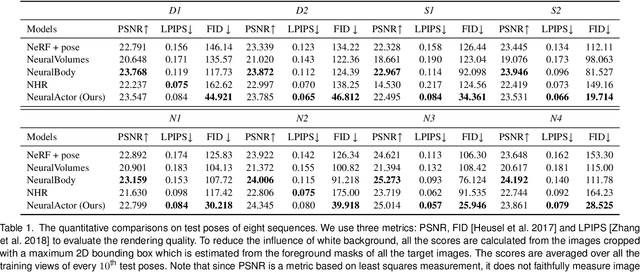
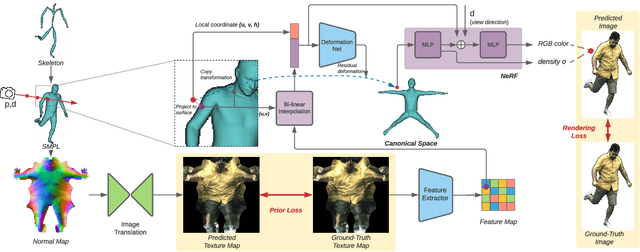
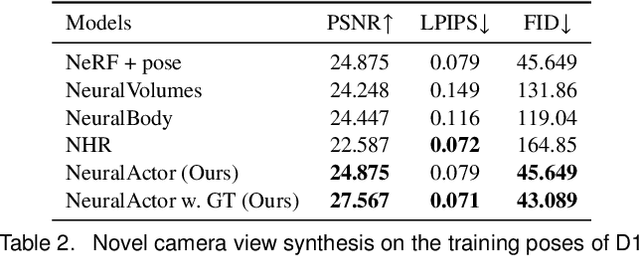
We propose Neural Actor (NA), a new method for high-quality synthesis of humans from arbitrary viewpoints and under arbitrary controllable poses. Our method is built upon recent neural scene representation and rendering works which learn representations of geometry and appearance from only 2D images. While existing works demonstrated compelling rendering of static scenes and playback of dynamic scenes, photo-realistic reconstruction and rendering of humans with neural implicit methods, in particular under user-controlled novel poses, is still difficult. To address this problem, we utilize a coarse body model as the proxy to unwarp the surrounding 3D space into a canonical pose. A neural radiance field learns pose-dependent geometric deformations and pose- and view-dependent appearance effects in the canonical space from multi-view video input. To synthesize novel views of high fidelity dynamic geometry and appearance, we leverage 2D texture maps defined on the body model as latent variables for predicting residual deformations and the dynamic appearance. Experiments demonstrate that our method achieves better quality than the state-of-the-arts on playback as well as novel pose synthesis, and can even generalize well to new poses that starkly differ from the training poses. Furthermore, our method also supports body shape control of the synthesized results.
Diverse Semantic Image Synthesis via Probability Distribution Modeling
Mar 11, 2021
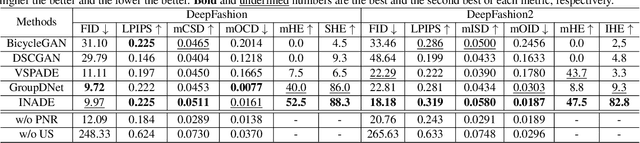
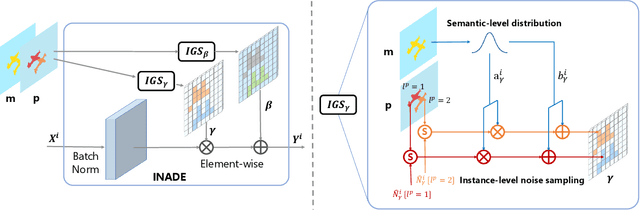
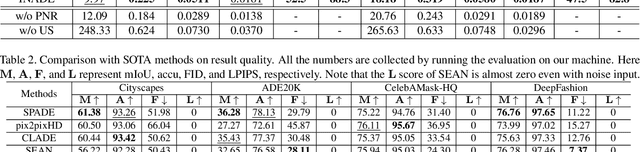
Semantic image synthesis, translating semantic layouts to photo-realistic images, is a one-to-many mapping problem. Though impressive progress has been recently made, diverse semantic synthesis that can efficiently produce semantic-level multimodal results, still remains a challenge. In this paper, we propose a novel diverse semantic image synthesis framework from the perspective of semantic class distributions, which naturally supports diverse generation at semantic or even instance level. We achieve this by modeling class-level conditional modulation parameters as continuous probability distributions instead of discrete values, and sampling per-instance modulation parameters through instance-adaptive stochastic sampling that is consistent across the network. Moreover, we propose prior noise remapping, through linear perturbation parameters encoded from paired references, to facilitate supervised training and exemplar-based instance style control at test time. Extensive experiments on multiple datasets show that our method can achieve superior diversity and comparable quality compared to state-of-the-art methods. Code will be available at \url{https://github.com/tzt101/INADE.git}
ChangeSim: Towards End-to-End Online Scene Change Detection in Industrial Indoor Environments
Mar 09, 2021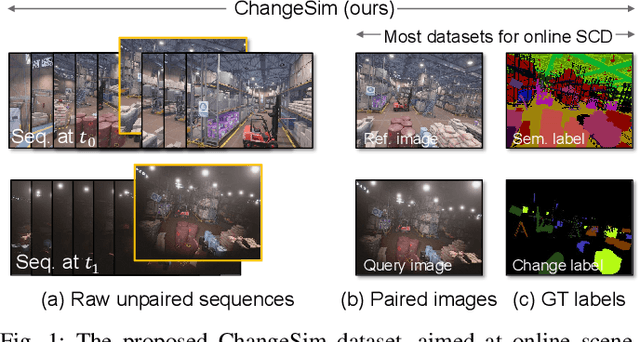

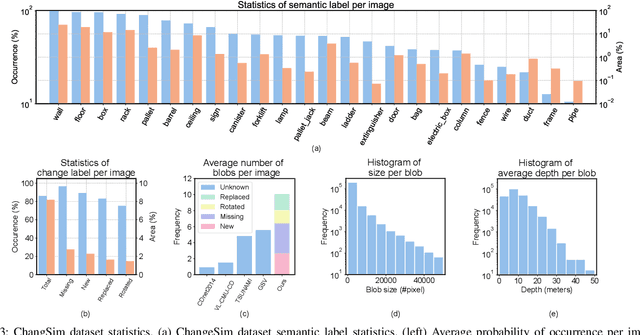

We present a challenging dataset, ChangeSim, aimed at online scene change detection (SCD) and more. The data is collected in photo-realistic simulation environments with the presence of environmental non-targeted variations, such as air turbidity and light condition changes, as well as targeted object changes in industrial indoor environments. By collecting data in simulations, multi-modal sensor data and precise ground truth labels are obtainable such as the RGB image, depth image, semantic segmentation, change segmentation, camera poses, and 3D reconstructions. While the previous online SCD datasets evaluate models given well-aligned image pairs, ChangeSim also provides raw unpaired sequences that present an opportunity to develop an online SCD model in an end-to-end manner, considering both pairing and detection. Experiments show that even the latest pair-based SCD models suffer from the bottleneck of the pairing process, and it gets worse when the environment contains the non-targeted variations. Our dataset is available at http://sammica.github.io/ChangeSim/.
Intrinsic Autoencoders for Joint Neural Rendering and Intrinsic Image Decomposition
Jul 01, 2020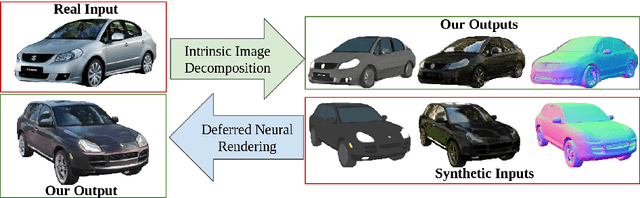

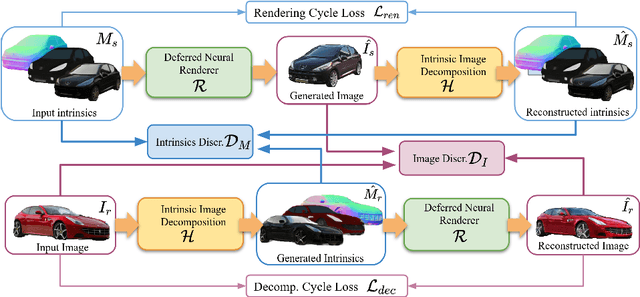
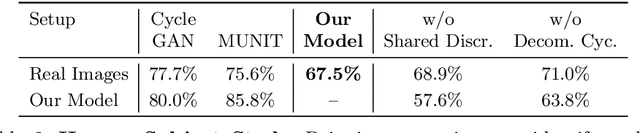
Neural rendering techniques promise efficient photo-realistic image synthesis while at the same time providing rich control over scene parameters by learning the physical image formation process. While several supervised methods have been proposed for this task, acquiring a dataset of images with accurately aligned 3D models is very difficult. The main contribution of this work is to lift this restriction by training a neural rendering algorithm from unpaired data. More specifically, we propose an autoencoder for joint generation of realistic images from synthetic 3D models while simultaneously decomposing real images into their intrinsic shape and appearance properties. In contrast to a traditional graphics pipeline, our approach does not require to specify all scene properties, such as material parameters and lighting by hand. Instead, we learn photo-realistic deferred rendering from a small set of 3D models and a larger set of unaligned real images, both of which are easy to acquire in practice. Simultaneously, we obtain accurate intrinsic decompositions of real images while not requiring paired ground truth. Our experiments confirm that a joint treatment of rendering and decomposition is indeed beneficial and that our approach outperforms state-of-the-art image-to-image translation baselines both qualitatively and quantitatively.
Semantics Disentangling for Text-to-Image Generation
Apr 02, 2019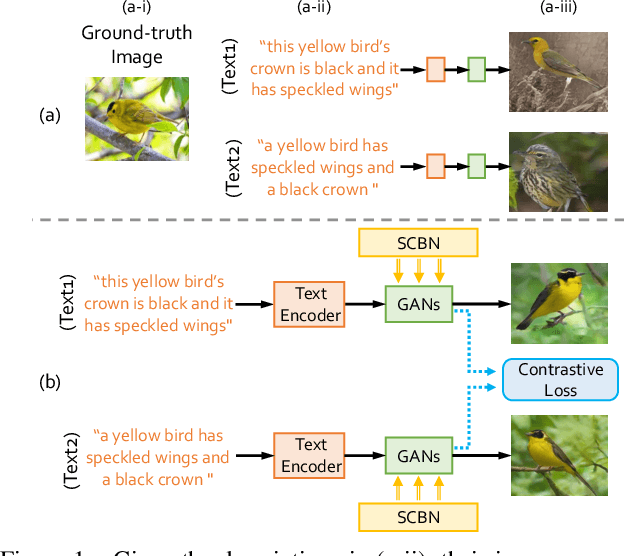
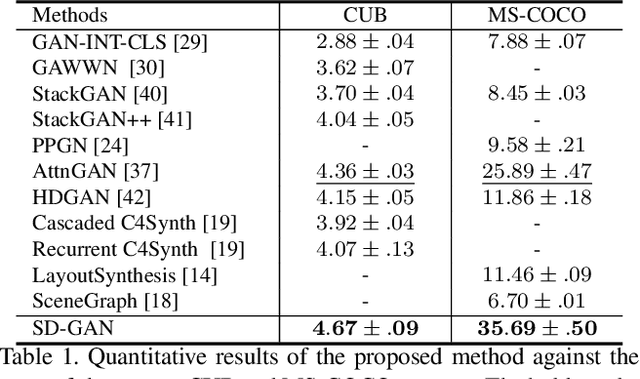
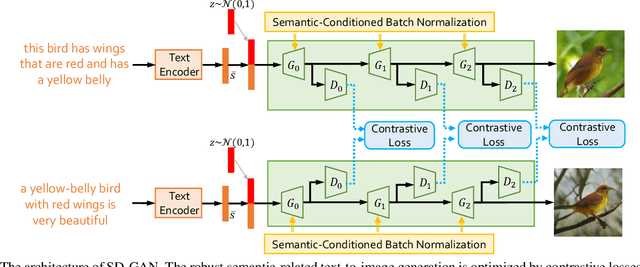
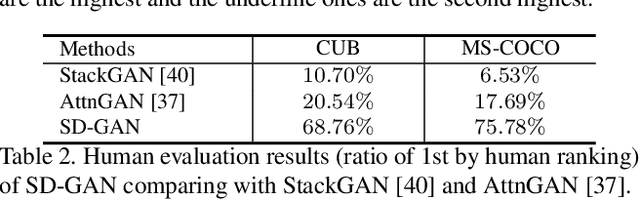
Synthesizing photo-realistic images from text descriptions is a challenging problem. Previous studies have shown remarkable progresses on visual quality of the generated images. In this paper, we consider semantics from the input text descriptions in helping render photo-realistic images. However, diverse linguistic expressions pose challenges in extracting consistent semantics even they depict the same thing. To this end, we propose a novel photo-realistic text-to-image generation model that implicitly disentangles semantics to both fulfill the high-level semantic consistency and low-level semantic diversity. To be specific, we design (1) a Siamese mechanism in the discriminator to learn consistent high-level semantics, and (2) a visual-semantic embedding strategy by semantic-conditioned batch normalization to find diverse low-level semantics. Extensive experiments and ablation studies on CUB and MS-COCO datasets demonstrate the superiority of the proposed method in comparison to state-of-the-art methods.
Disentangled Lifespan Face Synthesis
Aug 13, 2021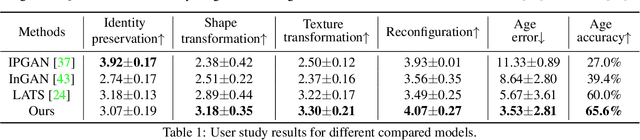
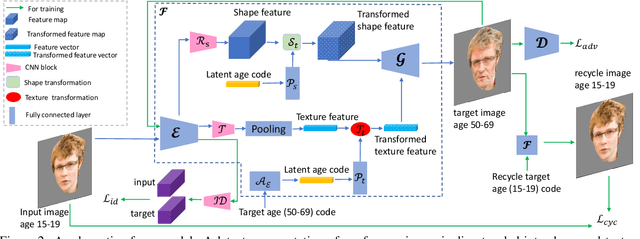
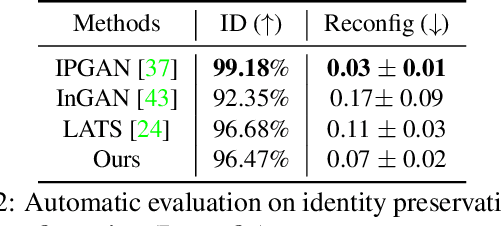

A lifespan face synthesis (LFS) model aims to generate a set of photo-realistic face images of a person's whole life, given only one snapshot as reference. The generated face image given a target age code is expected to be age-sensitive reflected by bio-plausible transformations of shape and texture, while being identity preserving. This is extremely challenging because the shape and texture characteristics of a face undergo separate and highly nonlinear transformations w.r.t. age. Most recent LFS models are based on generative adversarial networks (GANs) whereby age code conditional transformations are applied to a latent face representation. They benefit greatly from the recent advancements of GANs. However, without explicitly disentangling their latent representations into the texture, shape and identity factors, they are fundamentally limited in modeling the nonlinear age-related transformation on texture and shape whilst preserving identity. In this work, a novel LFS model is proposed to disentangle the key face characteristics including shape, texture and identity so that the unique shape and texture age transformations can be modeled effectively. This is achieved by extracting shape, texture and identity features separately from an encoder. Critically, two transformation modules, one conditional convolution based and the other channel attention based, are designed for modeling the nonlinear shape and texture feature transformations respectively. This is to accommodate their rather distinct aging processes and ensure that our synthesized images are both age-sensitive and identity preserving. Extensive experiments show that our LFS model is clearly superior to the state-of-the-art alternatives. Codes and demo are available on our project website: \url{https://senhe.github.io/projects/iccv_2021_lifespan_face}.