 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Transferable Time Series Classifier with Cross-Domain Pre-training from Language Model
Mar 19, 2024
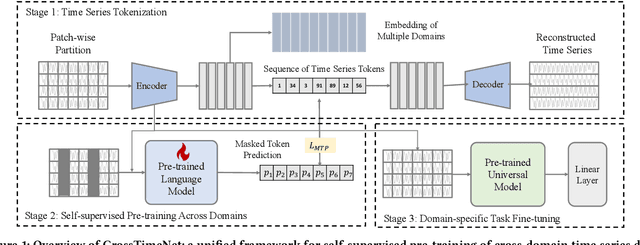
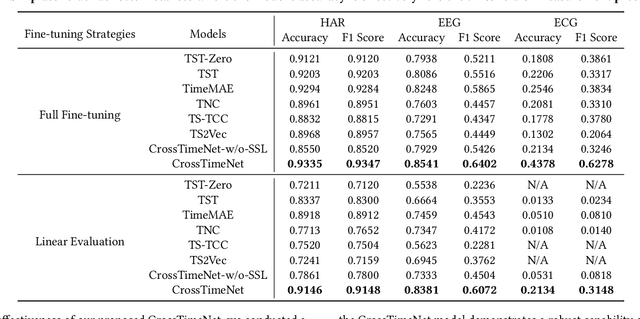
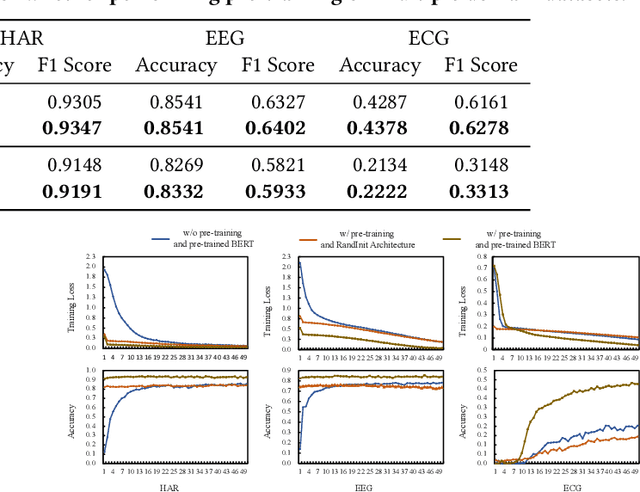
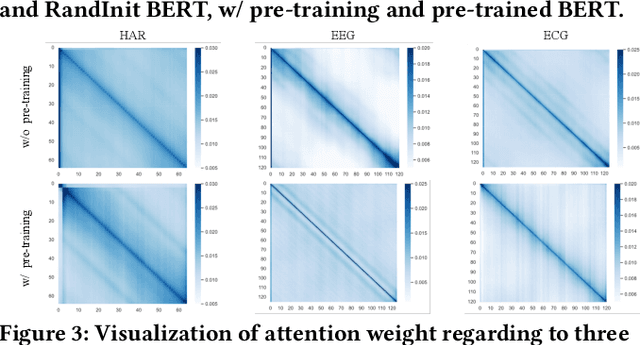
Advancements in self-supervised pre-training (SSL) have significantly advanced the field of learning transferable time series representations, which can be very useful in enhancing the downstream task. Despite being effective, most existing works struggle to achieve cross-domain SSL pre-training, missing valuable opportunities to integrate patterns and features from different domains. The main challenge lies in the significant differences in the characteristics of time-series data across different domains, such as variations in the number of channels and temporal resolution scales. To address this challenge, we propose CrossTimeNet, a novel cross-domain SSL learning framework to learn transferable knowledge from various domains to largely benefit the target downstream task. One of the key characteristics of CrossTimeNet is the newly designed time series tokenization module, which could effectively convert the raw time series into a sequence of discrete tokens based on a reconstruction optimization process. Besides, we highlight that predicting a high proportion of corrupted tokens can be very helpful for extracting informative patterns across different domains during SSL pre-training, which has been largely overlooked in past years. Furthermore, unlike previous works, our work treats the pre-training language model (PLM) as the initialization of the encoder network, investigating the feasibility of transferring the knowledge learned by the PLM to the time series area. Through these efforts, the path to cross-domain pre-training of a generic time series model can be effectively paved. We conduct extensive experiments in a real-world scenario across various time series classification domains. The experimental results clearly confirm CrossTimeNet's superior performance.
Vision-language models for decoding provider attention during neonatal resuscitation
Apr 01, 2024Neonatal resuscitations demand an exceptional level of attentiveness from providers, who must process multiple streams of information simultaneously. Gaze strongly influences decision making; thus, understanding where a provider is looking during neonatal resuscitations could inform provider training, enhance real-time decision support, and improve the design of delivery rooms and neonatal intensive care units (NICUs). Current approaches to quantifying neonatal providers' gaze rely on manual coding or simulations, which limit scalability and utility. Here, we introduce an automated, real-time, deep learning approach capable of decoding provider gaze into semantic classes directly from first-person point-of-view videos recorded during live resuscitations. Combining state-of-the-art, real-time segmentation with vision-language models (CLIP), our low-shot pipeline attains 91\% classification accuracy in identifying gaze targets without training. Upon fine-tuning, the performance of our gaze-guided vision transformer exceeds 98\% accuracy in gaze classification, approaching human-level precision. This system, capable of real-time inference, enables objective quantification of provider attention dynamics during live neonatal resuscitation. Our approach offers a scalable solution that seamlessly integrates with existing infrastructure for data-scarce gaze analysis, thereby offering new opportunities for understanding and refining clinical decision making.
Is Mamba Effective for Time Series Forecasting?
Mar 17, 2024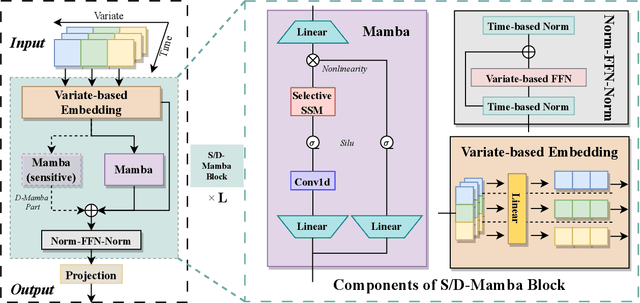
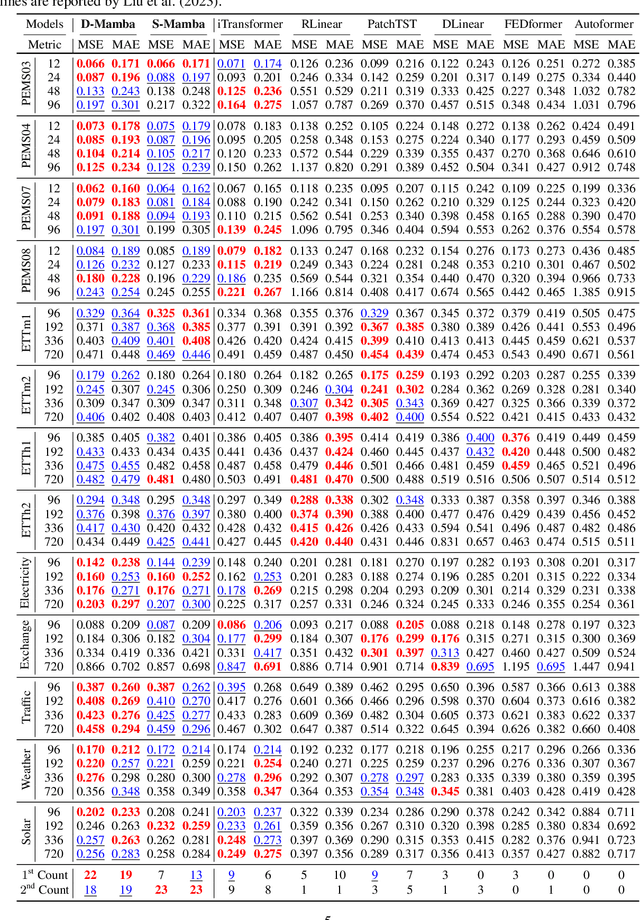
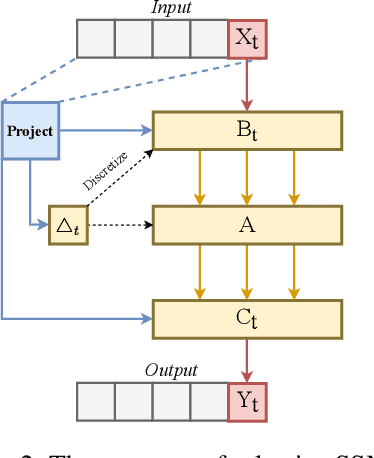
In the realm of time series forecasting (TSF), the Transformer has consistently demonstrated robust performance due to its ability to focus on the global context and effectively capture long-range dependencies within time, as well as discern correlations between multiple variables. However, due to the inefficiencies of the Transformer model and questions surrounding its ability to capture dependencies, ongoing efforts to refine the Transformer architecture persist. Recently, state space models (SSMs), e.g. Mamba, have gained traction due to their ability to capture complex dependencies in sequences, similar to the Transformer, while maintaining near-linear complexity. In text and image tasks, Mamba-based models can improve performance and cost savings, creating a win-win situation. This has piqued our interest in exploring SSM's potential in TSF tasks. In this paper, we introduce two straightforward SSM-based models for TSF, S-Mamba and D-Mamba, both employing the Mamba Block to extract variate correlations. Remarkably, S-Mamba and D-Mamba achieve superior performance while saving GPU memory and training time. Furthermore, we conduct extensive experiments to delve deeper into the potential of Mamba compared to the Transformer in the TSF, aiming to explore a new research direction for this field. Our code is available at https://github.com/wzhwzhwzh0921/S-D-Mamba.
Reliable Feature Selection for Adversarially Robust Cyber-Attack Detection
Apr 05, 2024The growing cybersecurity threats make it essential to use high-quality data to train Machine Learning (ML) models for network traffic analysis, without noisy or missing data. By selecting the most relevant features for cyber-attack detection, it is possible to improve both the robustness and computational efficiency of the models used in a cybersecurity system. This work presents a feature selection and consensus process that combines multiple methods and applies them to several network datasets. Two different feature sets were selected and were used to train multiple ML models with regular and adversarial training. Finally, an adversarial evasion robustness benchmark was performed to analyze the reliability of the different feature sets and their impact on the susceptibility of the models to adversarial examples. By using an improved dataset with more data diversity, selecting the best time-related features and a more specific feature set, and performing adversarial training, the ML models were able to achieve a better adversarially robust generalization. The robustness of the models was significantly improved without their generalization to regular traffic flows being affected, without increases of false alarms, and without requiring too many computational resources, which enables a reliable detection of suspicious activity and perturbed traffic flows in enterprise computer networks.
PointInfinity: Resolution-Invariant Point Diffusion Models
Apr 04, 2024We present PointInfinity, an efficient family of point cloud diffusion models. Our core idea is to use a transformer-based architecture with a fixed-size, resolution-invariant latent representation. This enables efficient training with low-resolution point clouds, while allowing high-resolution point clouds to be generated during inference. More importantly, we show that scaling the test-time resolution beyond the training resolution improves the fidelity of generated point clouds and surfaces. We analyze this phenomenon and draw a link to classifier-free guidance commonly used in diffusion models, demonstrating that both allow trading off fidelity and variability during inference. Experiments on CO3D show that PointInfinity can efficiently generate high-resolution point clouds (up to 131k points, 31 times more than Point-E) with state-of-the-art quality.
Time Series Compression using Quaternion Valued Neural Networks and Quaternion Backpropagation
Mar 18, 2024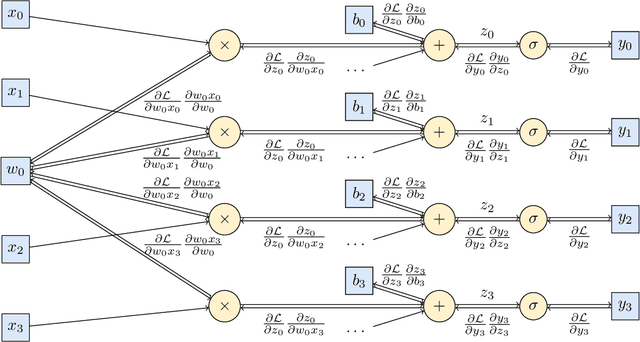
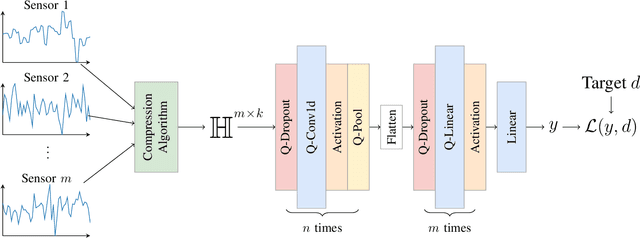
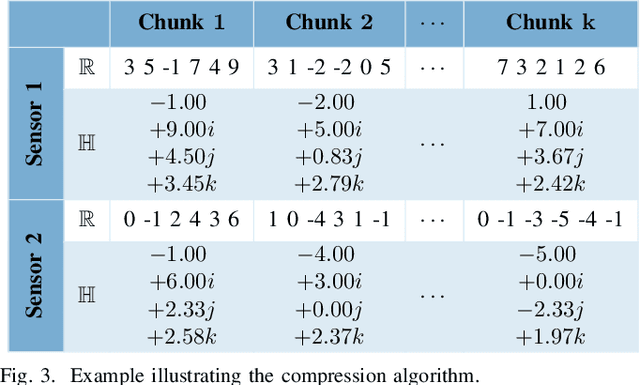
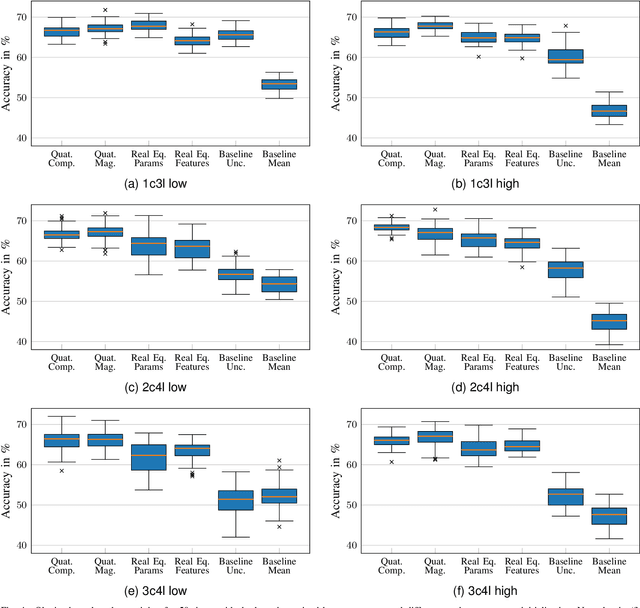
We propose a novel quaternionic time-series compression methodology where we divide a long time-series into segments of data, extract the min, max, mean and standard deviation of these chunks as representative features and encapsulate them in a quaternion, yielding a quaternion valued time-series. This time-series is processed using quaternion valued neural network layers, where we aim to preserve the relation between these features through the usage of the Hamilton product. To train this quaternion neural network, we derive quaternion backpropagation employing the GHR calculus, which is required for a valid product and chain rule in quaternion space. Furthermore, we investigate the connection between the derived update rules and automatic differentiation. We apply our proposed compression method on the Tennessee Eastman Dataset, where we perform fault classification using the compressed data in two settings: a fully supervised one and in a semi supervised, contrastive learning setting. Both times, we were able to outperform real valued counterparts as well as two baseline models: one with the uncompressed time-series as the input and the other with a regular downsampling using the mean. Further, we could improve the classification benchmark set by SimCLR-TS from 81.43% to 83.90%.
RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS
Mar 20, 2024
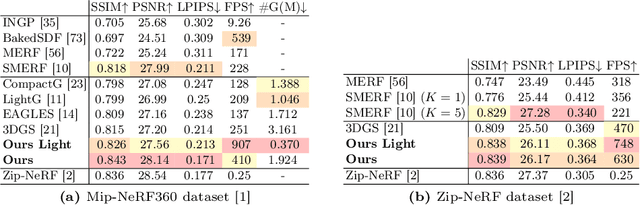
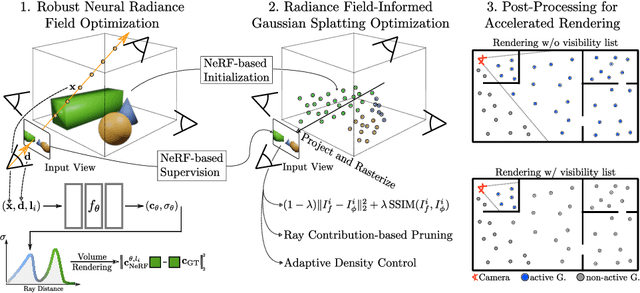

Recent advances in view synthesis and real-time rendering have achieved photorealistic quality at impressive rendering speeds. While Radiance Field-based methods achieve state-of-the-art quality in challenging scenarios such as in-the-wild captures and large-scale scenes, they often suffer from excessively high compute requirements linked to volumetric rendering. Gaussian Splatting-based methods, on the other hand, rely on rasterization and naturally achieve real-time rendering but suffer from brittle optimization heuristics that underperform on more challenging scenes. In this work, we present RadSplat, a lightweight method for robust real-time rendering of complex scenes. Our main contributions are threefold. First, we use radiance fields as a prior and supervision signal for optimizing point-based scene representations, leading to improved quality and more robust optimization. Next, we develop a novel pruning technique reducing the overall point count while maintaining high quality, leading to smaller and more compact scene representations with faster inference speeds. Finally, we propose a novel test-time filtering approach that further accelerates rendering and allows to scale to larger, house-sized scenes. We find that our method enables state-of-the-art synthesis of complex captures at 900+ FPS.
Agnostic Tomography of Stabilizer Product States
Apr 04, 2024We define a quantum learning task called agnostic tomography, where given copies of an arbitrary state $\rho$ and a class of quantum states $\mathcal{C}$, the goal is to output a succinct description of a state that approximates $\rho$ at least as well as any state in $\mathcal{C}$ (up to some small error $\varepsilon$). This task generalizes ordinary quantum tomography of states in $\mathcal{C}$ and is more challenging because the learning algorithm must be robust to perturbations of $\rho$. We give an efficient agnostic tomography algorithm for the class $\mathcal{C}$ of $n$-qubit stabilizer product states. Assuming $\rho$ has fidelity at least $\tau$ with a stabilizer product state, the algorithm runs in time $n^{O(1 + \log(1/\tau))} / \varepsilon^2$. This runtime is quasipolynomial in all parameters, and polynomial if $\tau$ is a constant.
Correlation and Spectral Density Functions in Mode-Stirred Reverberation -- II. Spectral Moments, Sampling, Noise, EMI and Understirring
Apr 04, 2024In part I, spectral moments and kurtosis were established as parameters in analytic models of correlation and spectral density functions for dynamic reverberation fields. In this part II, several practical limitations affecting the accuracy of estimating these parameters from measured stir sweep data are investigated. For sampled fields, the contributions of finite differencing and aliasing are evaluated. Finite differencing results in a negative bias that depends, to leading order, quadratically on the product of the sampling time interval and the stir bandwidth. Numerical estimates of moments extracted directly from sampled stir sweeps show good agreement with values obtained by an autocovariance method. The effects of data decimation and noise-to-stir ratios of RMS amplitudes are determined and experimentally verified. In addition, the dependencies on the noise-to-stir-bandwidth ratio, EMI, and unstirred energy are characterized.
* 13 pages, 11 figures
A Ground Mobile Robot for Autonomous Terrestrial Laser Scanning-Based Field Phenotyping
Apr 05, 2024Traditional field phenotyping methods are often manual, time-consuming, and destructive, posing a challenge for breeding progress. To address this bottleneck, robotics and automation technologies offer efficient sensing tools to monitor field evolution and crop development throughout the season. This study aimed to develop an autonomous ground robotic system for LiDAR-based field phenotyping in plant breeding trials. A Husky platform was equipped with a high-resolution three-dimensional (3D) laser scanner to collect in-field terrestrial laser scanning (TLS) data without human intervention. To automate the TLS process, a 3D ray casting analysis was implemented for optimal TLS site planning, and a route optimization algorithm was utilized to minimize travel distance during data collection. The platform was deployed in two cotton breeding fields for evaluation, where it autonomously collected TLS data. The system provided accurate pose information through RTK-GNSS positioning and sensor fusion techniques, with average errors of less than 0.6 cm for location and 0.38$^{\circ}$ for heading. The achieved localization accuracy allowed point cloud registration with mean point errors of approximately 2 cm, comparable to traditional TLS methods that rely on artificial targets and manual sensor deployment. This work presents an autonomous phenotyping platform that facilitates the quantitative assessment of plant traits under field conditions of both large agricultural fields and small breeding trials to contribute to the advancement of plant phenomics and breeding programs.