 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartially Observed Structural Causal Models
May 05, 2026Here we introduce Partially Observed Structural Causal Models (POSCMs) that formalize causal systems where latent contexts co-determine both the interaction structure and downstream mechanisms on observed variables. POSCMs provide an extension of structural causal models (SCMs), as a self-contained causal modeling framework for endogenous graphs, allowing for an intervention hierarchy spanning node- and edge-level context and endogenous variable interventions. To enable surgical edge interventions, we adopt a Kolmogorov-Arnold-Sprecher edge-functional decomposition, an existence theorem for representing each node mechanism as a sum of univariate functions of its parents, yielding an explicit parametrization of dyadic functional contributions. We provide an identifiability theory that clarifies which intervention families would suffice to disentangle structure formation from mechanisms. We empirically validate these predictions in a biophysically detailed virtual human retina simulator, constructing intervention protocols that (i) reproduce the non-identifiability predicted when context is latent and no context-level interventions are available, (ii) exhibit structure-mechanism confounding under latent edges when only node interventions are observed, and (iii) recover synaptic input-output relationships via targeted node interventions, consistent with our positive kernel identifiability result. Our work generalizes SCMs in a way that allows it to work in a world closer to the one we live in.
Zero-Ablation Overstates Register Content Dependence in DINO Vision Transformers
Apr 15, 2026Zero-ablation -- replacing token activations with zero vectors -- is widely used to probe token function in vision transformers. Register zeroing in DINOv2+registers and DINOv3 produces large drops (up to $-36.6$\,pp classification, $-30.9$\,pp segmentation), suggesting registers are functionally indispensable. However, three replacement controls -- mean-substitution, noise-substitution, and cross-image register-shuffling -- preserve performance across classification, correspondence, and segmentation, remaining within ${\sim}1$\,pp of the unmodified baseline. Per-patch cosine similarity shows these replacements genuinely perturb internal representations, while zeroing causes disproportionately large perturbations, consistent with why it alone degrades tasks. We conclude that zero-ablation overstates dependence on exact register content. In the frozen-feature evaluations we test, performance depends on plausible register-like activations rather than on exact image-specific values. Registers nevertheless buffer dense features from \texttt{[CLS]} dependence and are associated with compressed patch geometry. These findings, including the replacement-control results, replicate at ViT-B scale.
Vision-language models for decoding provider attention during neonatal resuscitation
Apr 01, 2024Neonatal resuscitations demand an exceptional level of attentiveness from providers, who must process multiple streams of information simultaneously. Gaze strongly influences decision making; thus, understanding where a provider is looking during neonatal resuscitations could inform provider training, enhance real-time decision support, and improve the design of delivery rooms and neonatal intensive care units (NICUs). Current approaches to quantifying neonatal providers' gaze rely on manual coding or simulations, which limit scalability and utility. Here, we introduce an automated, real-time, deep learning approach capable of decoding provider gaze into semantic classes directly from first-person point-of-view videos recorded during live resuscitations. Combining state-of-the-art, real-time segmentation with vision-language models (CLIP), our low-shot pipeline attains 91\% classification accuracy in identifying gaze targets without training. Upon fine-tuning, the performance of our gaze-guided vision transformer exceeds 98\% accuracy in gaze classification, approaching human-level precision. This system, capable of real-time inference, enables objective quantification of provider attention dynamics during live neonatal resuscitation. Our approach offers a scalable solution that seamlessly integrates with existing infrastructure for data-scarce gaze analysis, thereby offering new opportunities for understanding and refining clinical decision making.
Neural Networks as Paths through the Space of Representations
Jun 22, 2022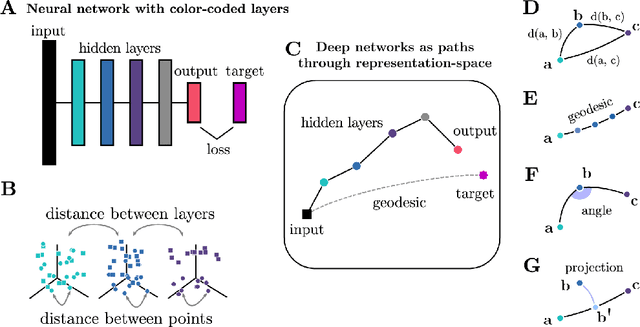
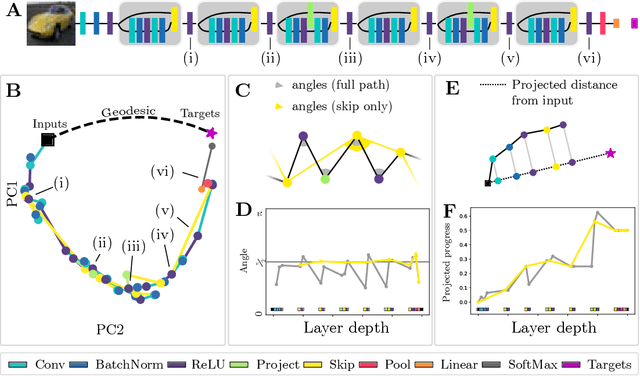
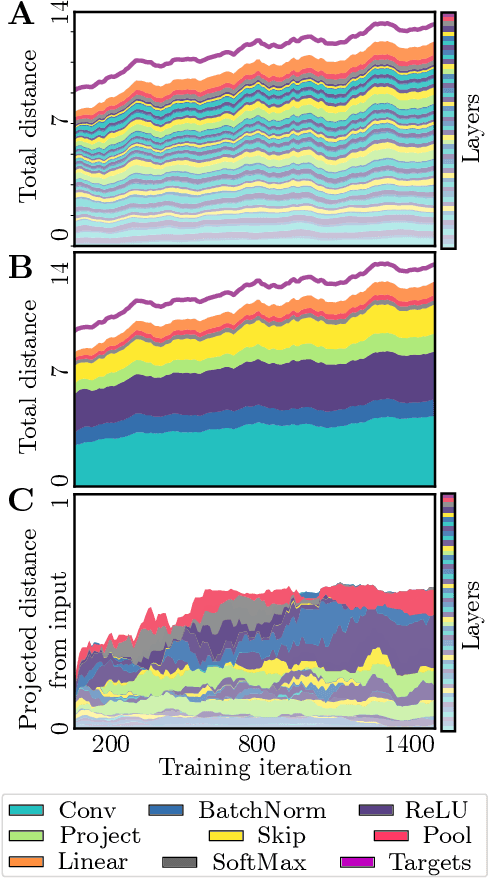
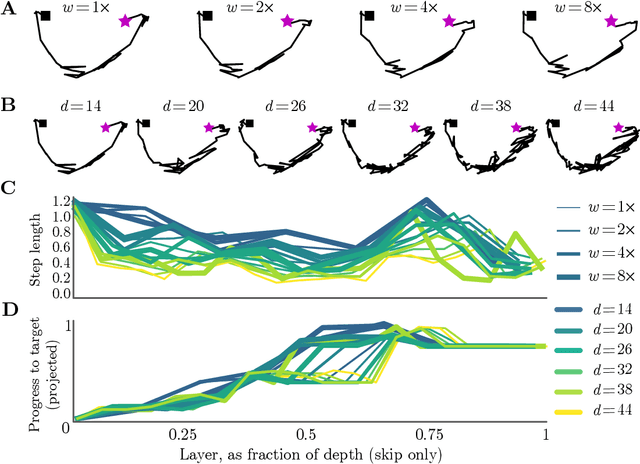
Deep neural networks implement a sequence of layer-by-layer operations that are each relatively easy to understand, but the resulting overall computation is generally difficult to understand. We develop a simple idea for interpreting the layer-by-layer construction of useful representations: the role of each layer is to reformat information to reduce the "distance" to the target outputs. We formalize this intuitive idea of "distance" by leveraging recent work on metric representational similarity, and show how it leads to a rich space of geometric concepts. With this framework, the layer-wise computation implemented by a deep neural network can be viewed as a path in a high-dimensional representation space. We develop tools to characterize the geometry of these in terms of distances, angles, and geodesics. We then ask three sets of questions of residual networks trained on CIFAR-10: (1) how straight are paths, and how does each layer contribute towards the target? (2) how do these properties emerge over training? and (3) how similar are the paths taken by wider versus deeper networks? We conclude by sketching additional ways that this kind of representational geometry can be used to understand and interpret network training, or to prescriptively improve network architectures to suit a task.
A Large Deformation Diffeomorphic Approach to Registration of CLARITY Images via Mutual Information
Aug 11, 2017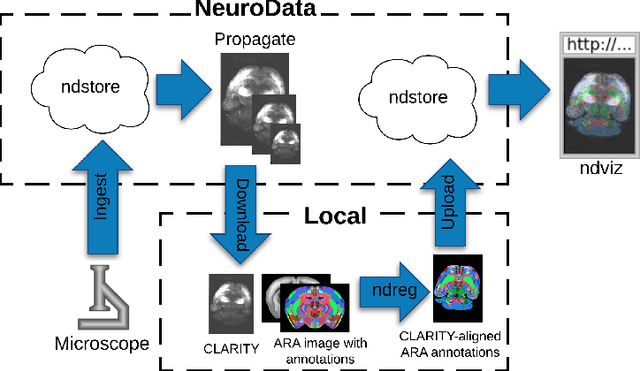
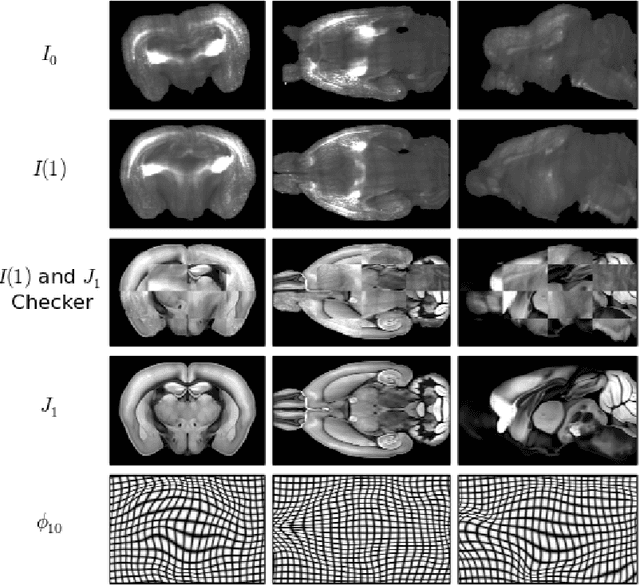
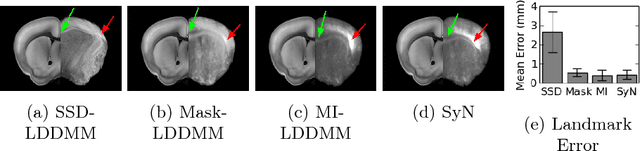
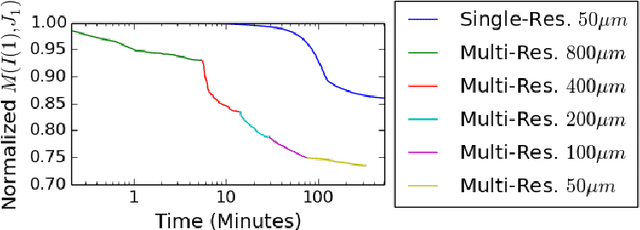
CLARITY is a method for converting biological tissues into translucent and porous hydrogel-tissue hybrids. This facilitates interrogation with light sheet microscopy and penetration of molecular probes while avoiding physical slicing. In this work, we develop a pipeline for registering CLARIfied mouse brains to an annotated brain atlas. Due to the novelty of this microscopy technique it is impractical to use absolute intensity values to align these images to existing standard atlases. Thus we adopt a large deformation diffeomorphic approach for registering images via mutual information matching. Furthermore we show how a cascaded multi-resolution approach can improve registration quality while reducing algorithm run time. As acquired image volumes were over a terabyte in size, they were far too large for work on personal computers. Therefore the NeuroData computational infrastructure was deployed for multi-resolution storage and visualization of these images and aligned annotations on the web.