 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VENOMAVE: Clean-Label Poisoning Against Speech Recognition
Oct 21, 2020


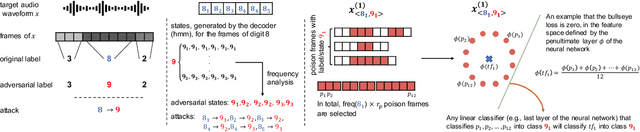
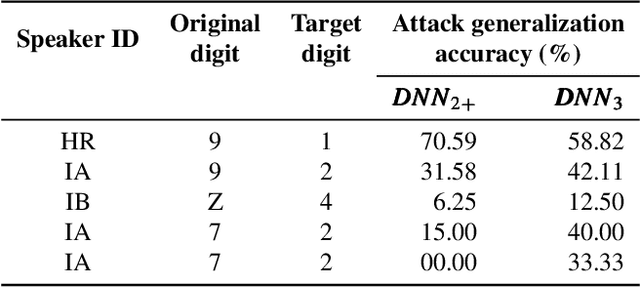
In the past few years, we observed a wide adoption of practical systems that use Automatic Speech Recognition (ASR) systems to improve human-machine interaction. Modern ASR systems are based on neural networks and prior research demonstrated that these systems are susceptible to adversarial examples, i.e., malicious audio inputs that lead to misclassification by the victim's network during the system's run time. The research question if ASR systems are also vulnerable to data poisoning attacks is still unanswered. In such an attack, a manipulation happens during the training phase of the neural network: an adversary injects malicious inputs into the training set such that the neural network's integrity and performance are compromised. In this paper, we present the first data poisoning attack in the audio domain, called VENOMAVE. Prior work in the image domain demonstrated several types of data poisoning attacks, but they cannot be applied to the audio domain. The main challenge is that we need to attack a time series of inputs. To enforce a targeted misclassification in an ASR system, we need to carefully generate a specific sequence of disturbed inputs for the target utterance, which will eventually be decoded to the desired sequence of words. More specifically, the adversarial goal is to produce a series of misclassification tasks and in each of them, we need to poison the system to misrecognize each frame of the target file. To demonstrate the practical feasibility of our attack, we evaluate VENOMAVE on an ASR system that detects sequences of digits from 0 to 9. When poisoning only 0.94% of the dataset on average, we achieve an attack success rate of 83.33%. We conclude that data poisoning attacks against ASR systems represent a real threat that needs to be considered.
Semi-Supervised Learning for In-Game Expert-Level Music-to-Dance Translation
Sep 27, 2020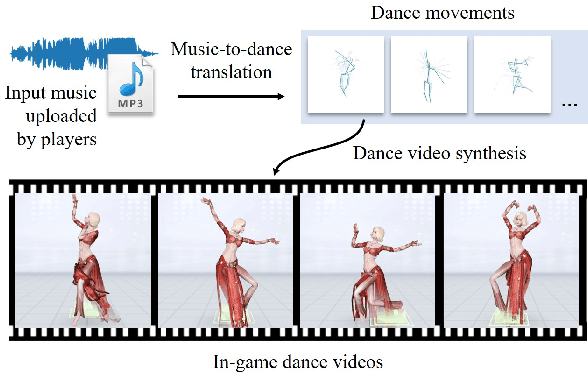

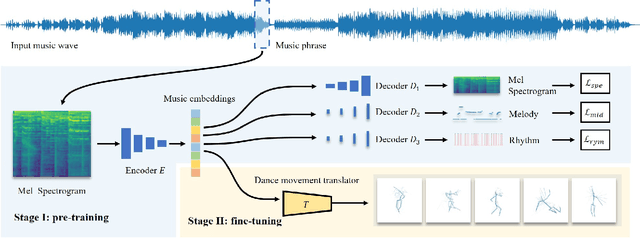

Music-to-dance translation is a brand-new and powerful feature in recent role-playing games. Players can now let their characters dance along with specified music clips and even generate fan-made dance videos. Previous works of this topic consider music-to-dance as a supervised motion generation problem based on time-series data. However, these methods suffer from limited training data pairs and the degradation of movements. This paper provides a new perspective for this task where we re-formulate the translation problem as a piece-wise dance phrase retrieval problem based on the choreography theory. With such a design, players are allowed to further edit the dance movements on top of our generation while other regression based methods ignore such user interactivity. Considering that the dance motion capture is an expensive and time-consuming procedure which requires the assistance of professional dancers, we train our method under a semi-supervised learning framework with a large unlabeled dataset (20x than labeled data) collected. A co-ascent mechanism is introduced to improve the robustness of our network. Using this unlabeled dataset, we also introduce self-supervised pre-training so that the translator can understand the melody, rhythm, and other components of music phrases. We show that the pre-training significantly improves the translation accuracy than that of training from scratch. Experimental results suggest that our method not only generalizes well over various styles of music but also succeeds in expert-level choreography for game players.
V2I Connectivity-Based Dynamic Queue-Jump Lane for Emergency Vehicles: A Deep Reinforcement Learning Approach
Aug 01, 2020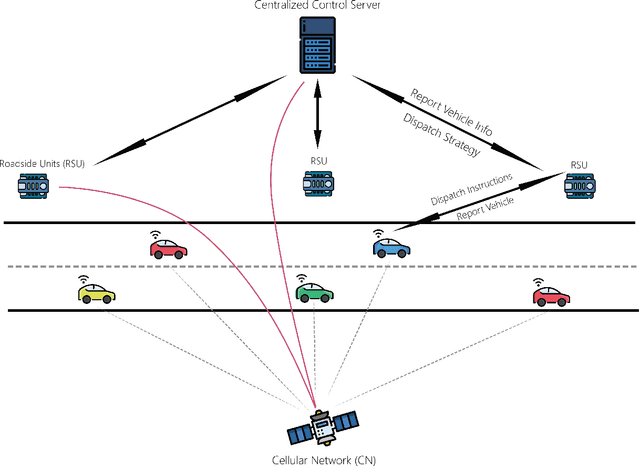

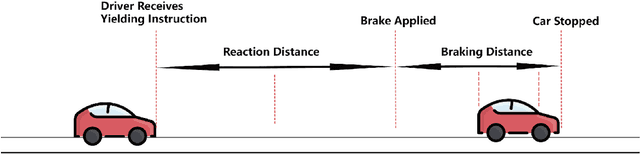

Emergency vehicle (EMV) service is a key function of cities and is exceedingly challenging due to urban traffic congestion. A main reason behind EMV service delay is the lack of communication and cooperation between vehicles blocking EMVs. In this paper, we study the improvement of EMV service under V2I connectivity. We consider the establishment of dynamic queue jump lanes (DQJLs) based on real-time coordination of connected vehicles. We develop a novel Markov decision process formulation for the DQJL problem, which explicitly accounts for the uncertainty of drivers' reaction to approaching EMVs. We propose a deep neural network-based reinforcement learning algorithm that efficiently computes the optimal coordination instructions. We also validate our approach on a micro-simulation testbed using Simulation of Urban Mobility (SUMO). Validation results show that with our proposed methodology, the centralized control system saves approximately 15\% EMV passing time than the benchmark system.
Towards Coalgebras in Stylometry
Oct 06, 2020
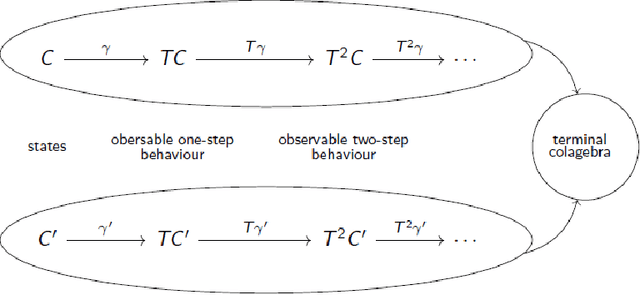
The syntactic behaviour of texts can highly vary depending on their contexts (e.g. author, genre, etc.). From the standpoint of stylometry, it can be helpful to objectively measure this behaviour. In this paper, we discuss how coalgebras are used to formalise the notion of behaviour by embedding syntactic features of a given text into probabilistic transition systems. By introducing the behavioural distance, we are then able to quantitatively measure differences between points in these systems and thus, comparing features of different texts. Furthermore, the behavioural distance of points can be approximated by a polynomial-time algorithm.
TNT: Target-driveN Trajectory Prediction
Aug 19, 2020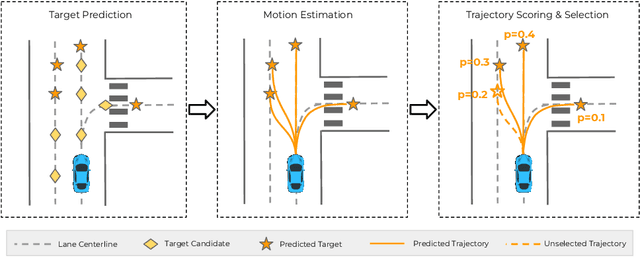
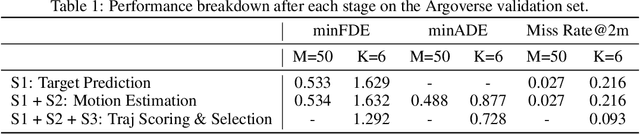
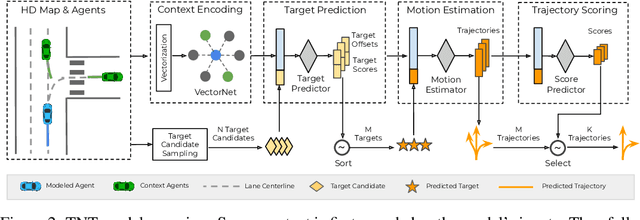
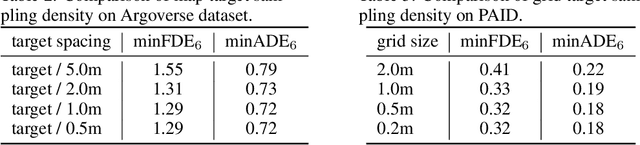
Predicting the future behavior of moving agents is essential for real world applications. It is challenging as the intent of the agent and the corresponding behavior is unknown and intrinsically multimodal. Our key insight is that for prediction within a moderate time horizon, the future modes can be effectively captured by a set of target states. This leads to our target-driven trajectory prediction (TNT) framework. TNT has three stages which are trained end-to-end. It first predicts an agent's potential target states $T$ steps into the future, by encoding its interactions with the environment and the other agents. TNT then generates trajectory state sequences conditioned on targets. A final stage estimates trajectory likelihoods and a final compact set of trajectory predictions is selected. This is in contrast to previous work which models agent intents as latent variables, and relies on test-time sampling to generate diverse trajectories. We benchmark TNT on trajectory prediction of vehicles and pedestrians, where we outperform state-of-the-art on Argoverse Forecasting, INTERACTION, Stanford Drone and an in-house Pedestrian-at-Intersection dataset.
SkiNet: A Deep Learning Solution for Skin Lesion Diagnosis with Uncertainty Estimation and Explainability
Dec 30, 2020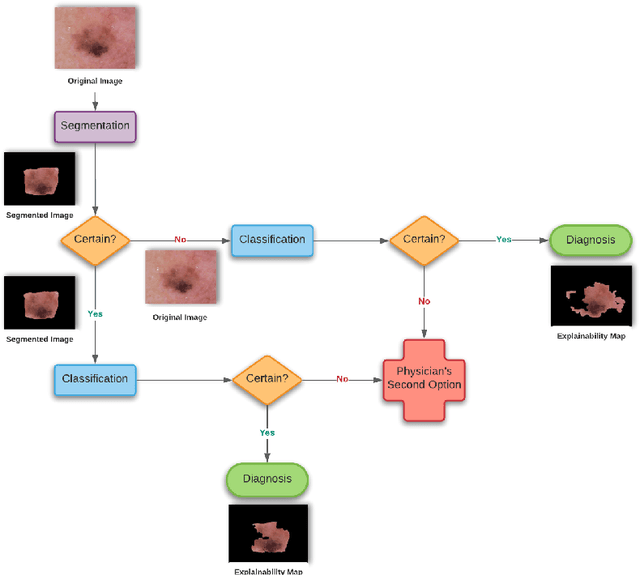

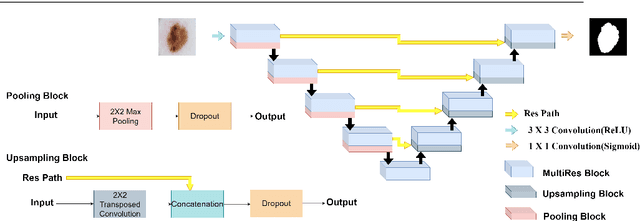
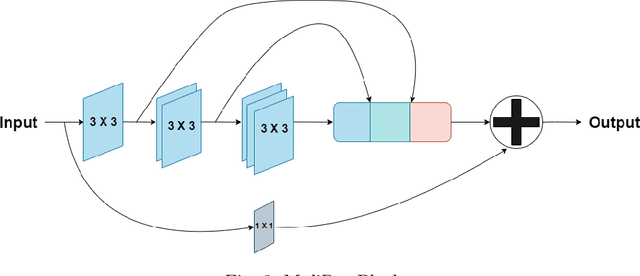
Skin cancer is considered to be the most common human malignancy. Around 5 million new cases of skin cancer are recorded in the United States annually. Early identification and evaluation of skin lesions is of great clinical significance, but the disproportionate dermatologist-patient ratio poses significant problem in most developing nations. Therefore a deep learning based architecture, known as SkiNet, is proposed with an objective to provide faster screening solution and assistance to newly trained physicians in the clinical diagnosis process. The main motive behind Skinet's design and development is to provide a white box solution, addressing a critical problem of trust and interpretability which is crucial for the wider adoption of Computer-aided diagnosis systems by the medical practitioners. SkiNet is a two-stage pipeline wherein the lesion segmentation is followed by the lesion classification. In our SkiNet methodology, Monte Carlo dropout and test time augmentation techniques have been employed to estimate epistemic and aleatoric uncertainty, while saliency-based methods are explored to provide post-hoc explanations of the deep learning models. The publicly available dataset, ISIC-2018, is used to perform experimentation and ablation studies. The results establish the robustness of the model on the traditional benchmarks while addressing the black-box nature of such models to alleviate the skepticism of medical practitioners by incorporating transparency and confidence to the model's prediction.
Improving Simultaneous Translation with Pseudo References
Oct 21, 2020
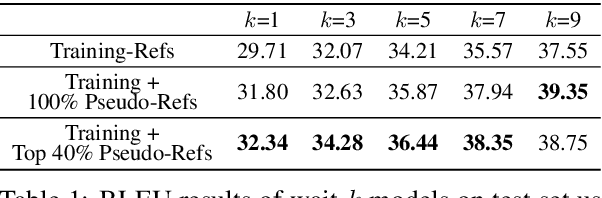
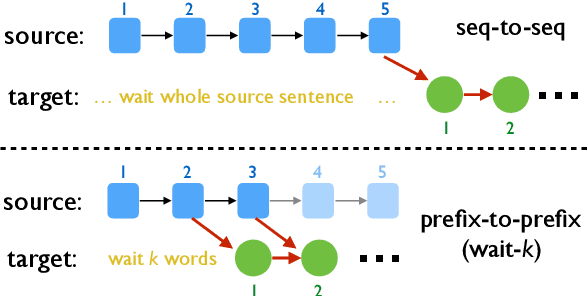
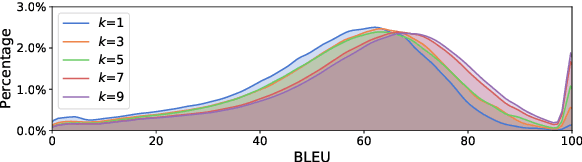
Simultaneous translation is vastly different from full-sentence translation, in the sense that it starts translation before the source sentence ends, with only a few words delay. However, due to the lack of large scale and publicly available simultaneous translation datasets, most simultaneous translation systems still train with ordinary full-sentence parallel corpora which are not suitable for the simultaneous scenario due to the existence of unnecessary long-distance reorderings. Instead of expensive, time-consuming annotation, we propose a novel method that rewrites the target side of existing full-sentence corpus into simultaneous-style translation. Experiments on Chinese-to-English translation demonstrate about +2.7 BLEU improvements with the addition of newly generated pseudo references.
Concept Drift Monitoring and Diagnostics of Supervised Learning Models via Score Vectors
Dec 12, 2020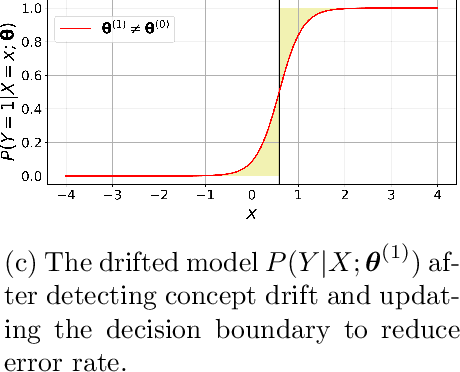
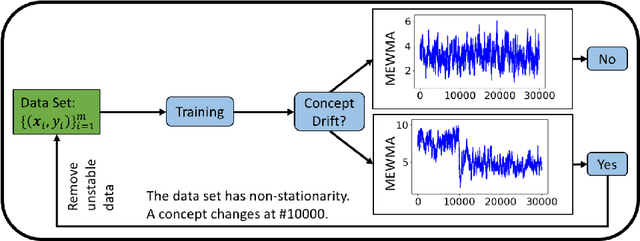
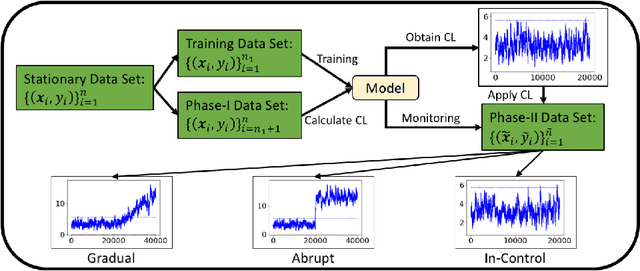
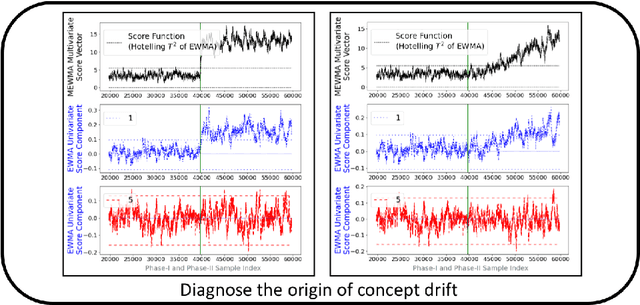
Supervised learning models are one of the most fundamental classes of models. Viewing supervised learning from a probabilistic perspective, the set of training data to which the model is fitted is usually assumed to follow a stationary distribution. However, this stationarity assumption is often violated in a phenomenon called concept drift, which refers to changes over time in the predictive relationship between covariates $\mathbf{X}$ and a response variable $Y$ and can render trained models suboptimal or obsolete. We develop a comprehensive and computationally efficient framework for detecting, monitoring, and diagnosing concept drift. Specifically, we monitor the Fisher score vector, defined as the gradient of the log-likelihood for the fitted model, using a form of multivariate exponentially weighted moving average, which monitors for general changes in the mean of a random vector. In spite of the substantial performance advantages that we demonstrate over popular error-based methods, a score-based approach has not been previously considered for concept drift monitoring. Advantages of the proposed score-based framework include applicability to any parametric model, more powerful detection of changes as shown in theory and experiments, and inherent diagnostic capabilities for helping to identify the nature of the changes.
Coarse-grained and emergent distributed parameter systems from data
Nov 16, 2020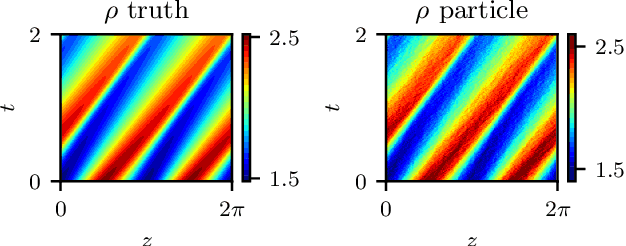
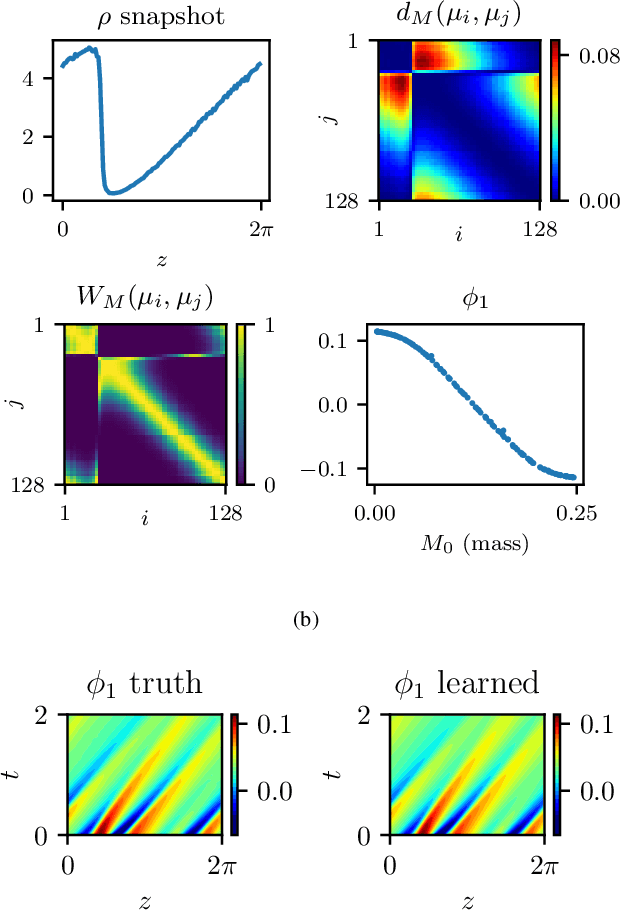
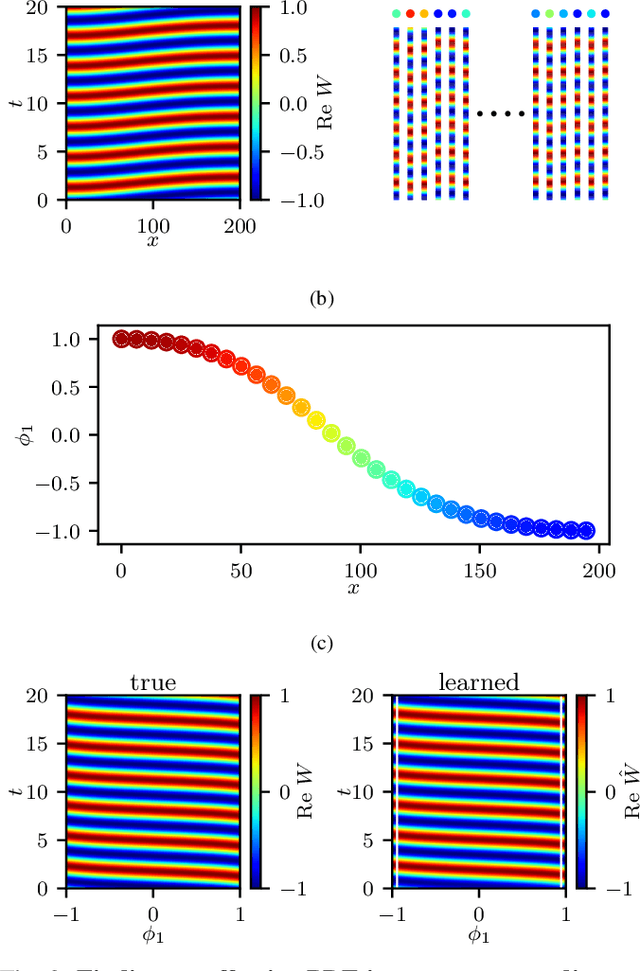
We explore the derivation of distributed parameter system evolution laws (and in particular, partial differential operators and associated partial differential equations, PDEs) from spatiotemporal data. This is, of course, a classical identification problem; our focus here is on the use of manifold learning techniques (and, in particular, variations of Diffusion Maps) in conjunction with neural network learning algorithms that allow us to attempt this task when the dependent variables, and even the independent variables of the PDE are not known a priori and must be themselves derived from the data. The similarity measure used in Diffusion Maps for dependent coarse variable detection involves distances between local particle distribution observations; for independent variable detection we use distances between local short-time dynamics. We demonstrate each approach through an illustrative established PDE example. Such variable-free, emergent space identification algorithms connect naturally with equation-free multiscale computation tools.
NP-ODE: Neural Process Aided Ordinary Differential Equations for Uncertainty Quantification of Finite Element Analysis
Dec 12, 2020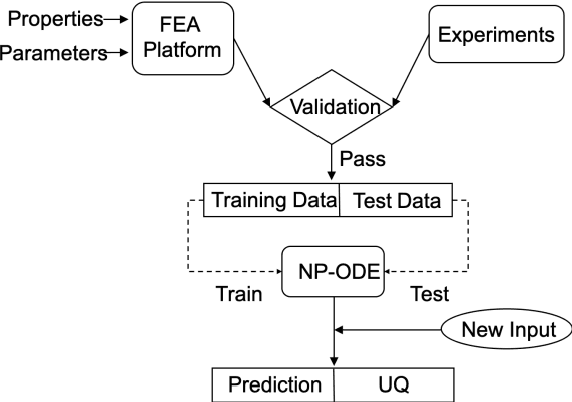
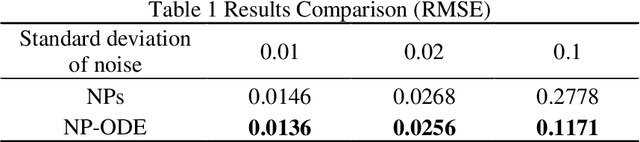
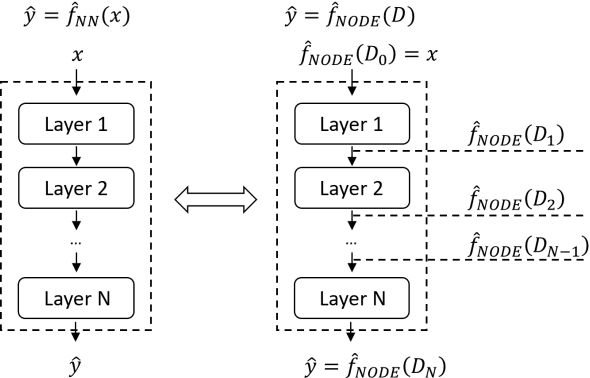
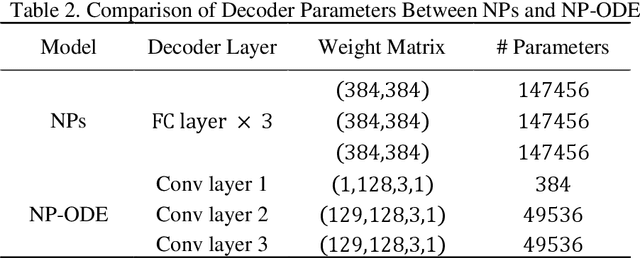
Finite element analysis (FEA) has been widely used to generate simulations of complex and nonlinear systems. Despite its strength and accuracy, the limitations of FEA can be summarized into two aspects: a) running high-fidelity FEA often requires significant computational cost and consumes a large amount of time; b) FEA is a deterministic method that is insufficient for uncertainty quantification (UQ) when modeling complex systems with various types of uncertainties. In this paper, a physics-informed data-driven surrogate model, named Neural Process Aided Ordinary Differential Equation (NP-ODE), is proposed to model the FEA simulations and capture both input and output uncertainties. To validate the advantages of the proposed NP-ODE, we conduct experiments on both the simulation data generated from a given ordinary differential equation and the data collected from a real FEA platform for tribocorrosion. The performances of the proposed NP-ODE and several benchmark methods are compared. The results show that the proposed NP-ODE outperforms benchmark methods. The NP-ODE method realizes the smallest predictive error as well as generates the most reasonable confidence interval having the best coverage on testing data points.