 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Algorithmic Self-Portrait: Deconstructing Memory in ChatGPT
Feb 03, 2026To enable personalized and context-aware interactions, conversational AI systems have introduced a new mechanism: Memory. Memory creates what we refer to as the Algorithmic Self-portrait - a new form of personalization derived from users' self-disclosed information divulged within private conversations. While memory enables more coherent exchanges, the underlying processes of memory creation remain opaque, raising critical questions about data sensitivity, user agency, and the fidelity of the resulting portrait. To bridge this research gap, we analyze 2,050 memory entries from 80 real-world ChatGPT users. Our analyses reveal three key findings: (1) A striking 96% of memories in our dataset are created unilaterally by the conversational system, potentially shifting agency away from the user; (2) Memories, in our dataset, contain a rich mix of GDPR-defined personal data (in 28% memories) along with psychological insights about participants (in 52% memories); and (3)~A significant majority of the memories (84%) are directly grounded in user context, indicating faithful representation of the conversations. Finally, we introduce a framework-Attribution Shield-that anticipates these inferences, alerts about potentially sensitive memory inferences, and suggests query reformulations to protect personal information without sacrificing utility.
Security Benefits and Side Effects of Labeling AI-Generated Images
May 28, 2025



Generative artificial intelligence is developing rapidly, impacting humans' interaction with information and digital media. It is increasingly used to create deceptively realistic misinformation, so lawmakers have imposed regulations requiring the disclosure of AI-generated content. However, only little is known about whether these labels reduce the risks of AI-generated misinformation. Our work addresses this research gap. Focusing on AI-generated images, we study the implications of labels, including the possibility of mislabeling. Assuming that simplicity, transparency, and trust are likely to impact the successful adoption of such labels, we first qualitatively explore users' opinions and expectations of AI labeling using five focus groups. Second, we conduct a pre-registered online survey with over 1300 U.S. and EU participants to quantitatively assess the effect of AI labels on users' ability to recognize misinformation containing either human-made or AI-generated images. Our focus groups illustrate that, while participants have concerns about the practical implementation of labeling, they consider it helpful in identifying AI-generated images and avoiding deception. However, considering security benefits, our survey revealed an ambiguous picture, suggesting that users might over-rely on labels. While inaccurate claims supported by labeled AI-generated images were rated less credible than those with unlabeled AI-images, the belief in accurate claims also decreased when accompanied by a labeled AI-generated image. Moreover, we find the undesired side effect that human-made images conveying inaccurate claims were perceived as more credible in the presence of labels.
HexaCoder: Secure Code Generation via Oracle-Guided Synthetic Training Data
Sep 10, 2024



Large language models (LLMs) have shown great potential for automatic code generation and form the basis for various tools such as GitHub Copilot. However, recent studies highlight that many LLM-generated code contains serious security vulnerabilities. While previous work tries to address this by training models that generate secure code, these attempts remain constrained by limited access to training data and labor-intensive data preparation. In this paper, we introduce HexaCoder, a novel approach to enhance the ability of LLMs to generate secure codes by automatically synthesizing secure codes, which reduces the effort of finding suitable training data. HexaCoder comprises two key components: an oracle-guided data synthesis pipeline and a two-step process for secure code generation. The data synthesis pipeline generates pairs of vulnerable and fixed codes for specific Common Weakness Enumeration (CWE) types by utilizing a state-of-the-art LLM for repairing vulnerable code. A security oracle identifies vulnerabilities, and a state-of-the-art LLM repairs them by extending and/or editing the codes, creating data pairs for fine-tuning using the Low-Rank Adaptation (LoRA) method. Each example of our fine-tuning dataset includes the necessary security-related libraries and code that form the basis of our novel two-step generation approach. This allows the model to integrate security-relevant libraries before generating the main code, significantly reducing the number of generated vulnerable codes by up to 85% compared to the baseline methods. We perform extensive evaluations on three different benchmarks for four LLMs, demonstrating that HexaCoder not only improves the security of the generated code but also maintains a high level of functional correctness.
AI-Generated Faces in the Real World: A Large-Scale Case Study of Twitter Profile Images
Apr 22, 2024



Recent advances in the field of generative artificial intelligence (AI) have blurred the lines between authentic and machine-generated content, making it almost impossible for humans to distinguish between such media. One notable consequence is the use of AI-generated images for fake profiles on social media. While several types of disinformation campaigns and similar incidents have been reported in the past, a systematic analysis has been lacking. In this work, we conduct the first large-scale investigation of the prevalence of AI-generated profile pictures on Twitter. We tackle the challenges of a real-world measurement study by carefully integrating various data sources and designing a multi-stage detection pipeline. Our analysis of nearly 15 million Twitter profile pictures shows that 0.052% were artificially generated, confirming their notable presence on the platform. We comprehensively examine the characteristics of these accounts and their tweet content, and uncover patterns of coordinated inauthentic behavior. The results also reveal several motives, including spamming and political amplification campaigns. Our research reaffirms the need for effective detection and mitigation strategies to cope with the potential negative effects of generative AI in the future.
A Representative Study on Human Detection of Artificially Generated Media Across Countries
Dec 10, 2023



AI-generated media has become a threat to our digital society as we know it. These forgeries can be created automatically and on a large scale based on publicly available technology. Recognizing this challenge, academics and practitioners have proposed a multitude of automatic detection strategies to detect such artificial media. However, in contrast to these technical advances, the human perception of generated media has not been thoroughly studied yet. In this paper, we aim at closing this research gap. We perform the first comprehensive survey into people's ability to detect generated media, spanning three countries (USA, Germany, and China) with 3,002 participants across audio, image, and text media. Our results indicate that state-of-the-art forgeries are almost indistinguishable from "real" media, with the majority of participants simply guessing when asked to rate them as human- or machine-generated. In addition, AI-generated media receive is voted more human like across all media types and all countries. To further understand which factors influence people's ability to detect generated media, we include personal variables, chosen based on a literature review in the domains of deepfake and fake news research. In a regression analysis, we found that generalized trust, cognitive reflection, and self-reported familiarity with deepfakes significantly influence participant's decision across all media categories.
No more Reviewer #2: Subverting Automatic Paper-Reviewer Assignment using Adversarial Learning
Mar 25, 2023



The number of papers submitted to academic conferences is steadily rising in many scientific disciplines. To handle this growth, systems for automatic paper-reviewer assignments are increasingly used during the reviewing process. These systems use statistical topic models to characterize the content of submissions and automate the assignment to reviewers. In this paper, we show that this automation can be manipulated using adversarial learning. We propose an attack that adapts a given paper so that it misleads the assignment and selects its own reviewers. Our attack is based on a novel optimization strategy that alternates between the feature space and problem space to realize unobtrusive changes to the paper. To evaluate the feasibility of our attack, we simulate the paper-reviewer assignment of an actual security conference (IEEE S&P) with 165 reviewers on the program committee. Our results show that we can successfully select and remove reviewers without access to the assignment system. Moreover, we demonstrate that the manipulated papers remain plausible and are often indistinguishable from benign submissions.
More than you've asked for: A Comprehensive Analysis of Novel Prompt Injection Threats to Application-Integrated Large Language Models
Feb 23, 2023



We are currently witnessing dramatic advances in the capabilities of Large Language Models (LLMs). They are already being adopted in practice and integrated into many systems, including integrated development environments (IDEs) and search engines. The functionalities of current LLMs can be modulated via natural language prompts, while their exact internal functionality remains implicit and unassessable. This property, which makes them adaptable to even unseen tasks, might also make them susceptible to targeted adversarial prompting. Recently, several ways to misalign LLMs using Prompt Injection (PI) attacks have been introduced. In such attacks, an adversary can prompt the LLM to produce malicious content or override the original instructions and the employed filtering schemes. Recent work showed that these attacks are hard to mitigate, as state-of-the-art LLMs are instruction-following. So far, these attacks assumed that the adversary is directly prompting the LLM. In this work, we show that augmenting LLMs with retrieval and API calling capabilities (so-called Application-Integrated LLMs) induces a whole new set of attack vectors. These LLMs might process poisoned content retrieved from the Web that contains malicious prompts pre-injected and selected by adversaries. We demonstrate that an attacker can indirectly perform such PI attacks. Based on this key insight, we systematically analyze the resulting threat landscape of Application-Integrated LLMs and discuss a variety of new attack vectors. To demonstrate the practical viability of our attacks, we implemented specific demonstrations of the proposed attacks within synthetic applications. In summary, our work calls for an urgent evaluation of current mitigation techniques and an investigation of whether new techniques are needed to defend LLMs against these threats.
Systematically Finding Security Vulnerabilities in Black-Box Code Generation Models
Feb 08, 2023



Recently, large language models for code generation have achieved breakthroughs in several programming language tasks. Their advances in competition-level programming problems have made them an emerging pillar in AI-assisted pair programming. Tools such as GitHub Copilot are already part of the daily programming workflow and are used by more than a million developers. The training data for these models is usually collected from open-source repositories (e.g., GitHub) that contain software faults and security vulnerabilities. This unsanitized training data can lead language models to learn these vulnerabilities and propagate them in the code generation procedure. Given the wide use of these models in the daily workflow of developers, it is crucial to study the security aspects of these models systematically. In this work, we propose the first approach to automatically finding security vulnerabilities in black-box code generation models. To achieve this, we propose a novel black-box inversion approach based on few-shot prompting. We evaluate the effectiveness of our approach by examining code generation models in the generation of high-risk security weaknesses. We show that our approach automatically and systematically finds 1000s of security vulnerabilities in various code generation models, including the commercial black-box model GitHub Copilot.
Towards the Detection of Diffusion Model Deepfakes
Oct 26, 2022Diffusion models (DMs) have recently emerged as a promising method in image synthesis. They have surpassed generative adversarial networks (GANs) in both diversity and quality, and have achieved impressive results in text-to-image and image-to-image modeling. However, to date, only little attention has been paid to the detection of DM-generated images, which is critical to prevent adverse impacts on our society. Although prior work has shown that GAN-generated images can be reliably detected using automated methods, it is unclear whether the same methods are effective against DMs. In this work, we address this challenge and take a first look at detecting DM-generated images. We approach the problem from two different angles: First, we evaluate the performance of state-of-the-art detectors on a variety of DMs. Second, we analyze DM-generated images in the frequency domain and study different factors that influence the spectral properties of these images. Most importantly, we demonstrate that GANs and DMs produce images with different characteristics, which requires adaptation of existing classifiers to ensure reliable detection. We believe this work provides the foundation and starting point for further research to detect DM deepfakes effectively.
CNN-generated images are surprisingly easy to spotfor now
Apr 07, 2021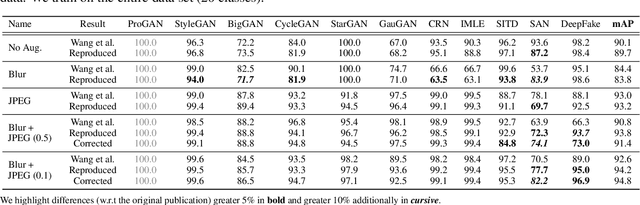
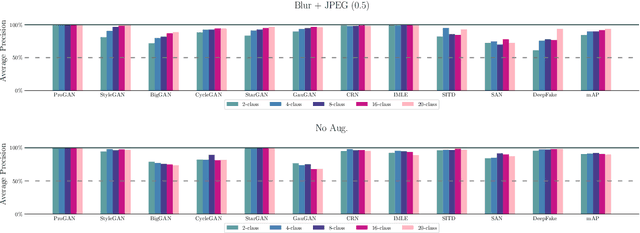
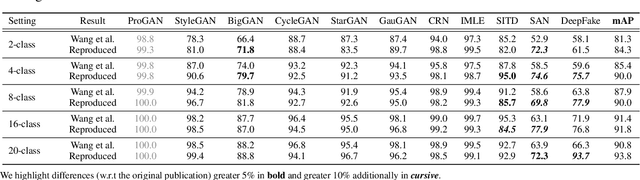
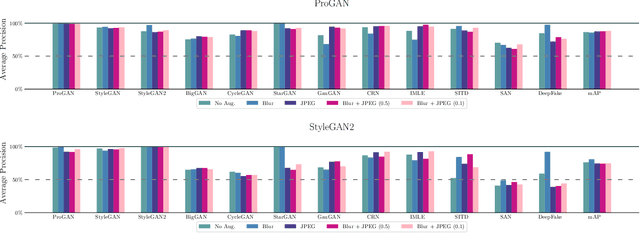
This work evaluates the reproducibility of the paper "CNN-generated images are surprisingly easy to spot... for now" by Wang et al. published at CVPR 2020. The paper addresses the challenge of detecting CNN-generated imagery, which has reached the potential to even fool humans. The authors propose two methods which help an image classifier to generalize from being trained on one specific CNN to detecting imagery produced by unseen architectures, training methods, or data sets. The paper proposes two methods to help a classifier generalize: (i) utilizing different kinds of data augmentations and (ii) using a diverse data set. This report focuses on assessing if these techniques indeed help the generalization process. Furthermore, we perform additional experiments to study the limitations of the proposed techniques.