 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Road Ahead in Autonomous Driving: The KITScenes Multimodal Dataset
Jun 01, 2026Existing autonomous driving datasets have enabled major progress, but fall short in sensor fidelity, map completeness, or geographic diversity. We present KITScenes Multimodal, a European dataset built around high-fidelity sensors and maps. Our fully synchronized sensor suite combines high-resolution global-shutter cameras, long-range lidar beyond 400m, 4D imaging radar, and redundant GNSS/INS localization. Our HD maps are, to our knowledge, the most complete of any sensor dataset, validated through autonomous driving trials on open-source software. For the first time in a public dataset, all driving-relevant traffic elements, such as traffic lights, are mapped in 3D to a reprojection-accurate level with full topological connectivity. Recorded in cities with irregular street layouts and mixed traffic modes, our dataset complements existing datasets by broadening the available geographic diversity. We also introduce four benchmarks, each advancing spatial learning for embodied AI: online HD map construction, long-range depth estimation, novel view synthesis, and end-to-end driving. Project page: https://kitscenes.com/
InterMesh: Explicit Interaction-Aware End-to-End Multi-Person Human Mesh Recovery
May 06, 2026Humans constantly interact with their surroundings. Existing end-to-end multi-person human mesh recovery methods, typically based on the DETR framework, capture inter-human relationships through self-attention across all human queries. However, these approaches model interactions only implicitly and lack explicit reasoning about how humans interact with objects and with each other. In this paper, we propose InterMesh, a simple yet effective framework that explicitly incorporates human-environment interaction information into human mesh recovery pipeline. By leveraging a human-object interaction detector, InterMesh enriches query representations with structured interaction semantics, enabling more accurate pose and shape estimation. We design lightweight modules, Contextual Interaction Encoder and Interaction-Guided Refiner, to integrate these features into existing HMR architectures with minimal overhead. We validate our approach through extensive experiments on 3DPW, MuPoTS, CMU Panoptic, Hi4D, and CHI3D datasets, demonstrating remarkable improvements over state-of-the-art methods. Notably, InterMesh reduces MPJPE by 9.9% on CMU Panoptic and 8.2% on Hi4D, highlighting its effectiveness in scenarios with complex human-object and inter-human interactions.
BoxComm: Benchmarking Category-Aware Commentary Generation and Narration Rhythm in Boxing
Apr 06, 2026Recent multimodal large language models (MLLMs) have shown strong capabilities in general video understanding, driving growing interest in automatic sports commentary generation. However, existing benchmarks for this task focus exclusively on team sports such as soccer and basketball, leaving combat sports entirely unexplored. Notably, combat sports present distinct challenges: critical actions unfold within milliseconds with visually subtle yet semantically decisive differences, and professional commentary contains a substantially higher proportion of tactical analysis compared to team sports. In this paper, we present BoxComm, a large-scale dataset comprising 445 World Boxing Championship match videos with over 52K commentary sentences from professional broadcasts. We propose a structured commentary taxonomy that categorizes each sentence into play-by-play, tactical, or contextual, providing the first category-level annotation for sports commentary benchmarks. Building on this taxonomy, we introduce two novel and complementary evaluations tailored to sports commentary generation: (1) category-conditioned generation, which evaluates whether models can produce accurate commentary of a specified type given video context; and (2) commentary rhythm assessment, which measures whether freely generated commentary exhibits appropriate temporal pacing and type distribution over continuous video segments, capturing a dimension of commentary competence that prior benchmarks have not addressed. Experiments on multiple state-of-the-art MLLMs reveal that current models struggle on both evaluations. We further propose EIC-Gen, an improved baseline incorporating detected punch events to supply structured action cues, yielding consistent gains and highlighting the importance of perceiving fleeting and subtle events for combat sports commentary.
LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
Mar 24, 2026In real-world domains such as self-driving, generalization to rare scenarios remains a fundamental challenge. To address this, we introduce a new dataset designed for end-to-end driving that focuses on long-tail driving events. We provide multi-view video data, trajectories, high-level instructions, and detailed reasoning traces, facilitating in-context learning and few-shot generalization. The resulting benchmark for multimodal models, such as VLMs and VLAs, goes beyond safety and comfort metrics by evaluating instruction following and semantic coherence between model outputs. The multilingual reasoning traces in English, Spanish, and Chinese are from domain experts with diverse cultural backgrounds. Thus, our dataset is a unique resource for studying how different forms of reasoning affect driving competence. Our dataset is available at: https://hf.co/datasets/kit-mrt/kitscenes-longtail
Learning the Mechanism of Catastrophic Forgetting: A Perspective from Gradient Similarity
Jan 29, 2026Catastrophic forgetting during knowledge injection severely undermines the continual learning capability of large language models (LLMs). Although existing methods attempt to mitigate this issue, they often lack a foundational theoretical explanation. We establish a gradient-based theoretical framework to explain catastrophic forgetting. We first prove that strongly negative gradient similarity is a fundamental cause of forgetting. We then use gradient similarity to identify two types of neurons: conflicting neurons that induce forgetting and account for 50%-75% of neurons, and collaborative neurons that mitigate forgetting and account for 25%-50%. Based on this analysis, we propose a knowledge injection method, Collaborative Neural Learning (CNL). By freezing conflicting neurons and updating only collaborative neurons, CNL theoretically eliminates catastrophic forgetting under an infinitesimal learning rate eta and an exactly known mastered set. Experiments on five LLMs, four datasets, and four optimizers show that CNL achieves zero forgetting in in-set settings and reduces forgetting by 59.1%-81.7% in out-of-set settings.
BoxMind: Closed-loop AI strategy optimization for elite boxing validated in the 2024 Olympics
Jan 16, 2026Competitive sports require sophisticated tactical analysis, yet combat disciplines like boxing remain underdeveloped in AI-driven analytics due to the complexity of action dynamics and the lack of structured tactical representations. To address this, we present BoxMind, a closed-loop AI expert system validated in elite boxing competition. By defining atomic punch events with precise temporal boundaries and spatial and technical attributes, we parse match footage into 18 hierarchical technical-tactical indicators. We then propose a graph-based predictive model that fuses these explicit technical-tactical profiles with learnable, time-variant latent embeddings to capture the dynamics of boxer matchups. Modeling match outcome as a differentiable function of technical-tactical indicators, we turn winning probability gradients into executable tactical adjustments. Experiments show that the outcome prediction model achieves state-of-the-art performance, with 69.8% accuracy on BoxerGraph test set and 87.5% on Olympic matches. Using this predictive model as a foundation, the system generates strategic recommendations that demonstrate proficiency comparable to human experts. BoxMind is validated through a closed-loop deployment during the 2024 Paris Olympics, directly contributing to the Chinese National Team's historic achievement of three gold and two silver medals. BoxMind establishes a replicable paradigm for transforming unstructured video data into strategic intelligence, bridging the gap between computer vision and decision support in competitive sports.
Towards Metric-Aware Multi-Person Mesh Recovery by Jointly Optimizing Human Crowd in Camera Space
Nov 17, 2025Multi-person human mesh recovery from a single image is a challenging task, hindered by the scarcity of in-the-wild training data. Prevailing in-the-wild human mesh pseudo-ground-truth (pGT) generation pipelines are single-person-centric, where each human is processed individually without joint optimization. This oversight leads to a lack of scene-level consistency, producing individuals with conflicting depths and scales within the same image. To address this, we introduce Depth-conditioned Translation Optimization (DTO), a novel optimization-based method that jointly refines the camera-space translations of all individuals in a crowd. By leveraging anthropometric priors on human height and depth cues from a monocular depth estimator, DTO solves for a scene-consistent placement of all subjects within a principled Maximum a posteriori (MAP) framework. Applying DTO to the 4D-Humans dataset, we construct DTO-Humans, a new large-scale pGT dataset of 0.56M high-quality, scene-consistent multi-person images, featuring dense crowds with an average of 4.8 persons per image. Furthermore, we propose Metric-Aware HMR, an end-to-end network that directly estimates human mesh and camera parameters in metric scale. This is enabled by a camera branch and a novel relative metric loss that enforces plausible relative scales. Extensive experiments demonstrate that our method achieves state-of-the-art performance on relative depth reasoning and human mesh recovery. Code and data will be released publicly.
Value-Guided Search for Efficient Chain-of-Thought Reasoning
May 23, 2025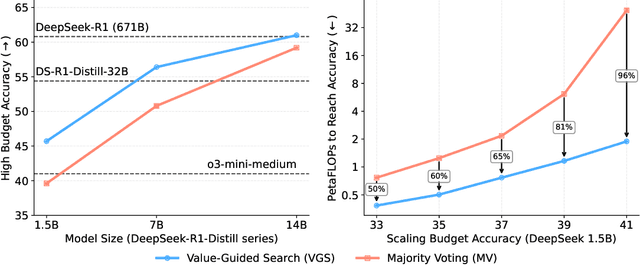
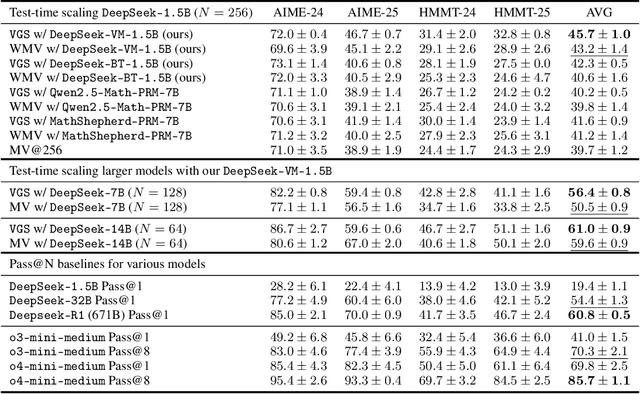
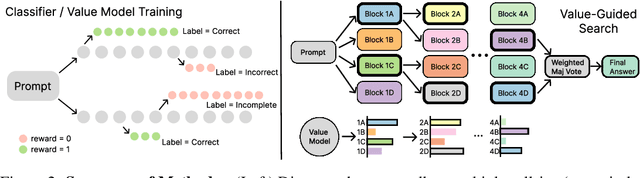
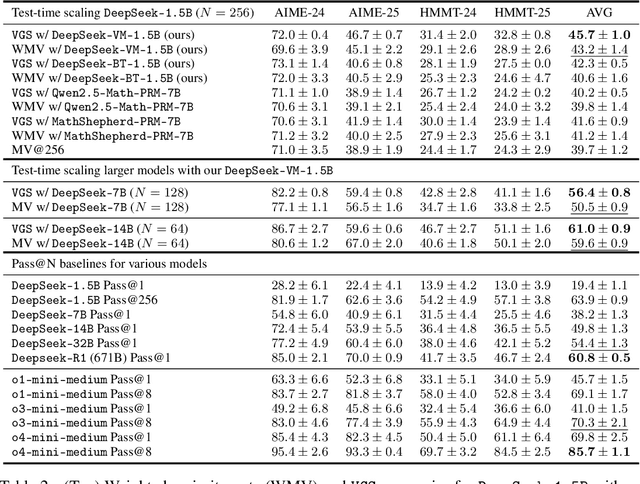
In this paper, we propose a simple and efficient method for value model training on long-context reasoning traces. Compared to existing process reward models (PRMs), our method does not require a fine-grained notion of "step," which is difficult to define for long-context reasoning models. By collecting a dataset of 2.5 million reasoning traces, we train a 1.5B token-level value model and apply it to DeepSeek models for improved performance with test-time compute scaling. We find that block-wise value-guided search (VGS) with a final weighted majority vote achieves better test-time scaling than standard methods such as majority voting or best-of-n. With an inference budget of 64 generations, VGS with DeepSeek-R1-Distill-1.5B achieves an average accuracy of 45.7% across four competition math benchmarks (AIME 2024 & 2025, HMMT Feb 2024 & 2025), reaching parity with o3-mini-medium. Moreover, VGS significantly reduces the inference FLOPs required to achieve the same performance of majority voting. Our dataset, model and codebase are open-sourced.
$Q\sharp$: Provably Optimal Distributional RL for LLM Post-Training
Feb 27, 2025



Reinforcement learning (RL) post-training is crucial for LLM alignment and reasoning, but existing policy-based methods, such as PPO and DPO, can fall short of fixing shortcuts inherited from pre-training. In this work, we introduce $Q\sharp$, a value-based algorithm for KL-regularized RL that guides the reference policy using the optimal regularized $Q$ function. We propose to learn the optimal $Q$ function using distributional RL on an aggregated online dataset. Unlike prior value-based baselines that guide the model using unregularized $Q$-values, our method is theoretically principled and provably learns the optimal policy for the KL-regularized RL problem. Empirically, $Q\sharp$ outperforms prior baselines in math reasoning benchmarks while maintaining a smaller KL divergence to the reference policy. Theoretically, we establish a reduction from KL-regularized RL to no-regret online learning, providing the first bounds for deterministic MDPs under only realizability. Thanks to distributional RL, our bounds are also variance-dependent and converge faster when the reference policy has small variance. In sum, our results highlight $Q\sharp$ as an effective approach for post-training LLMs, offering both improved performance and theoretical guarantees. The code can be found at https://github.com/jinpz/q_sharp.
Divide and Merge: Motion and Semantic Learning in End-to-End Autonomous Driving
Feb 11, 2025



Perceiving the environment and its changes over time corresponds to two fundamental yet heterogeneous types of information: semantics and motion. Previous end-to-end autonomous driving works represent both types of information in a single feature vector. However, including motion tasks, such as prediction and planning, always impairs detection and tracking performance, a phenomenon known as negative transfer in multi-task learning. To address this issue, we propose Neural-Bayes motion decoding, a novel parallel detection, tracking, and prediction method separating semantic and motion learning, similar to the Bayes filter. Specifically, we employ a set of learned motion queries that operate in parallel with the detection and tracking queries, sharing a unified set of recursively updated reference points. Moreover, we employ interactive semantic decoding to enhance information exchange in semantic tasks, promoting positive transfer. Experiments on the nuScenes dataset show improvements of 5% in detection and 11% in tracking. Our method achieves state-of-the-art collision rates in open-loop planning evaluation without any modifications to the planning module.