 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Spatio-Temporal Point Processes
Nov 09, 2020
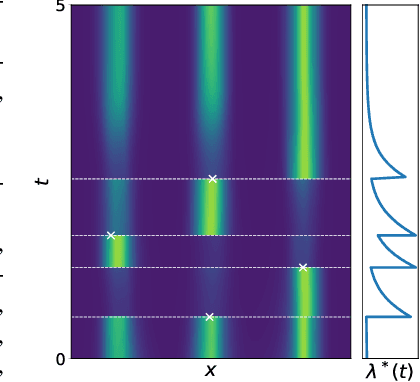
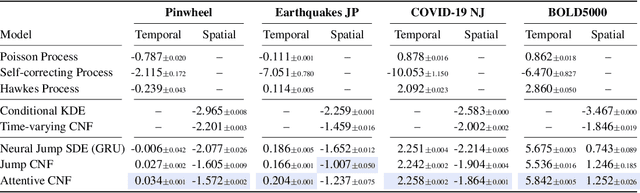
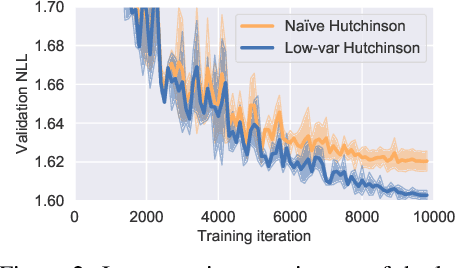

We propose a new class of parameterizations for spatio-temporal point processes which leverage Neural ODEs as a computational method and enable flexible, high-fidelity models of discrete events that are localized in continuous time and space. Central to our approach is a combination of recurrent continuous-time neural networks with two novel neural architectures, i.e., Jump and Attentive Continuous-time Normalizing Flows. This approach allows us to learn complex distributions for both the spatial and temporal domain and to condition non-trivially on the observed event history. We validate our models on data sets from a wide variety of contexts such as seismology, epidemiology, urban mobility, and neuroscience.
Equality Constrained Linear Optimal Control With Factor Graphs
Nov 02, 2020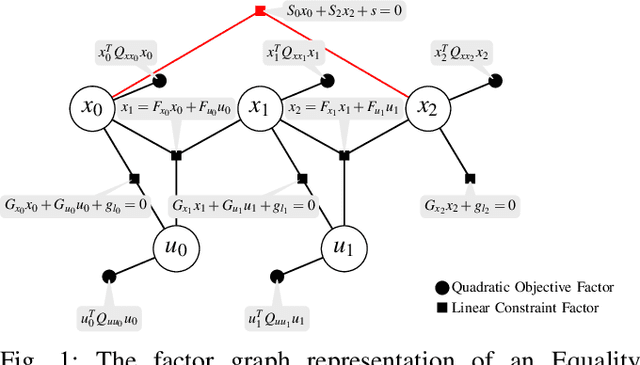
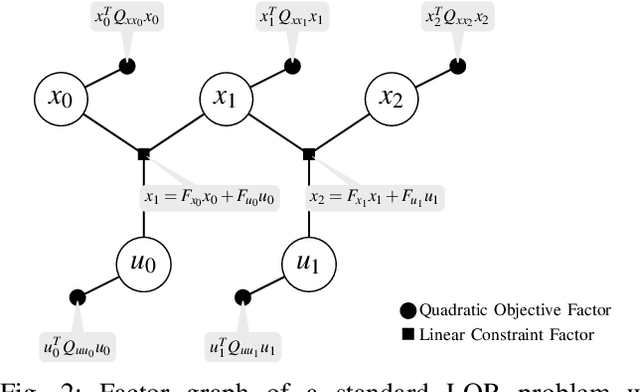
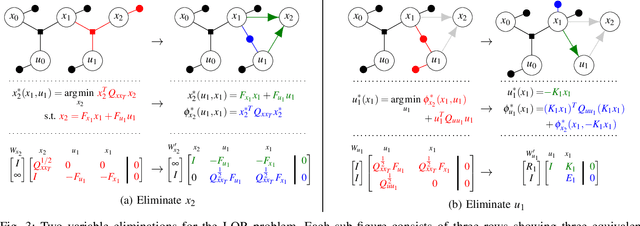
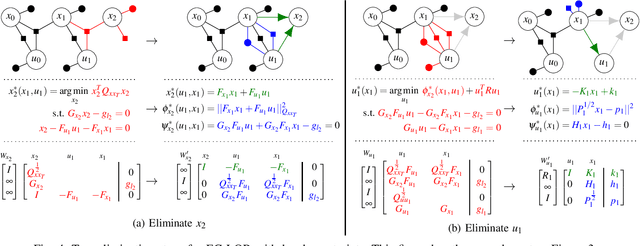
This paper presents a novel factor graph-based approach to solve the discrete-time finite-horizon Linear Quadratic Regulator problem subject to auxiliary linear equality constraints within and across time steps. We represent such optimal control problems using constrained factor graphs and optimize the factor graphs to obtain the optimal trajectory and the feedback control policies using the variable elimination algorithm with a modified Gram-Schmidt process. We prove that our approach has the same order of computational complexity as the state-of-the-art dynamic programming approach. Furthermore, current dynamic programming approaches can only handle equality constraints between variables at the same time step, but ours can handle equality constraints among any combination of variables at any time step while maintaining linear complexity with respect to trajectory length. Our approach can be used to efficiently generate trajectories and feedback control policies to achieve periodic motion or repetitive manipulation.
Unsupervised Segmentation Algorithms for Infrared Cloud Images
Mar 03, 2021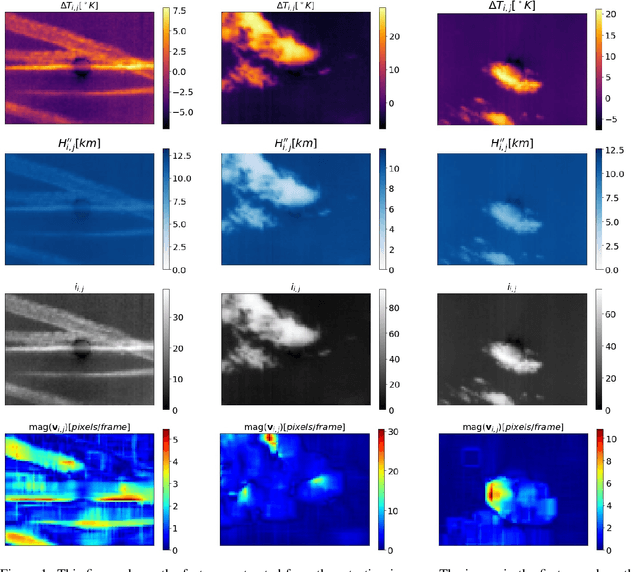
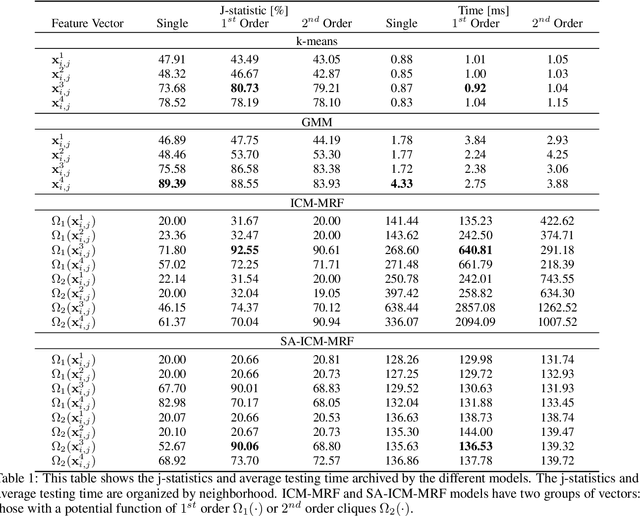

The increasing number of Photovoltaic (PV) systems connected to the power grids makes them vulnerable to the projection of shadows from moving clouds. Solar Global Irradiance (GSI) forecasting allows smart grids to optimize energy dispatch preventing cloud coverage shortages. This investigation compares the performances of unsupervised learning algorithms (not requiring labelled images for training) for real-time segmentation of clouds in a ground-base infrared sky-imaging system, which is commonly used to extract cloud features using only the pixels where clouds are detected.
Discussion of Ensemble Learning under the Era of Deep Learning
Jan 21, 2021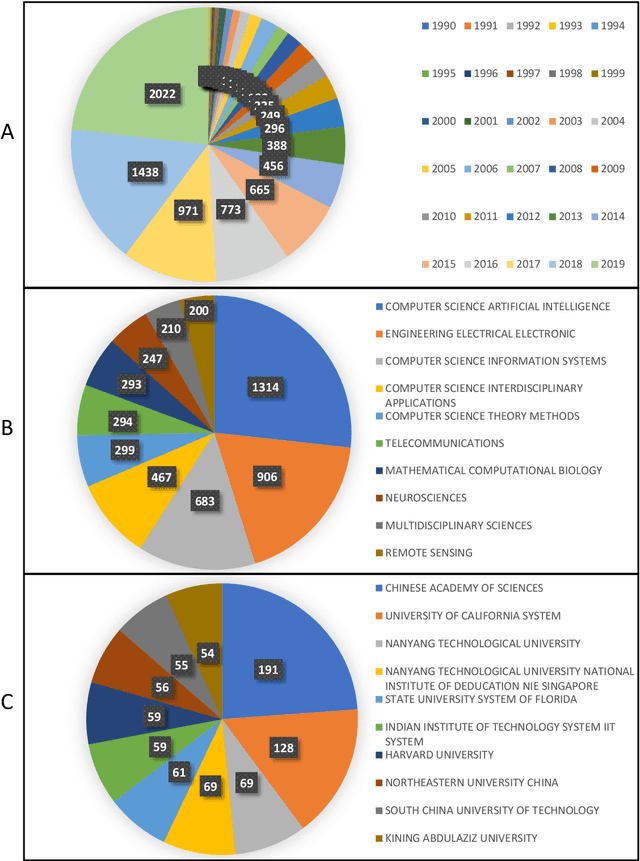
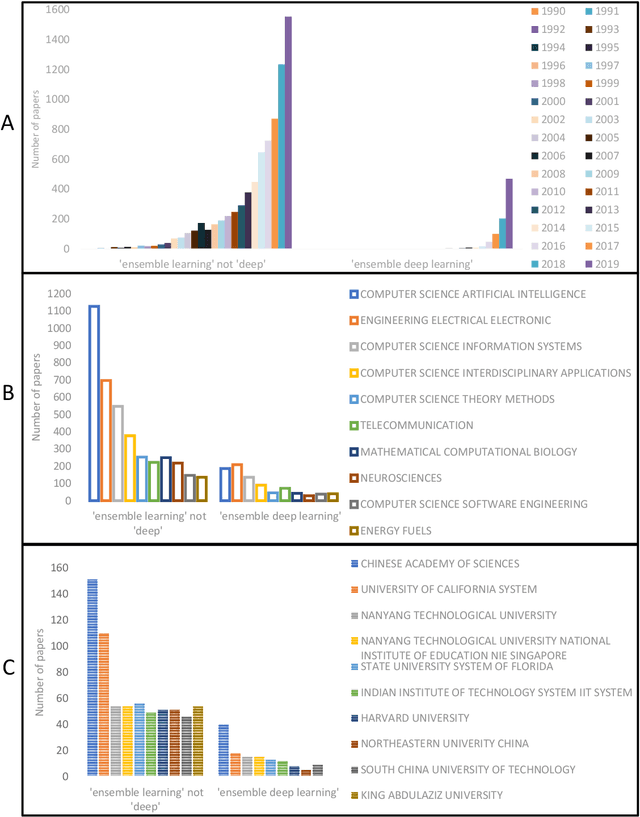
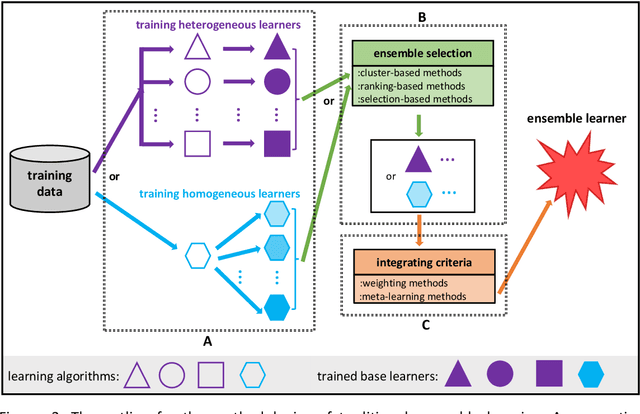
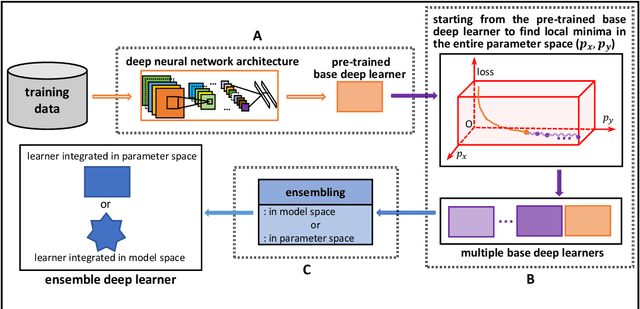
Due to the dominant position of deep learning (mostly deep neural networks) in various artificial intelligence applications, recently, ensemble learning based on deep neural networks (ensemble deep learning) has shown significant performances in improving the generalization of learning system. However, since modern deep neural networks usually have millions to billions of parameters, the time and space overheads for training multiple base deep learners and testing with the ensemble deep learner are far greater than that of traditional ensemble learning. Though several algorithms of fast ensemble deep learning have been proposed to promote the deployment of ensemble deep learning in some applications, further advances still need to be made for many applications in specific fields, where the developing time and computing resources are usually restricted or the data to be processed is of large dimensionality. An urgent problem needs to be solved is how to take the significant advantages of ensemble deep learning while reduce the required time and space overheads so that many more applications in specific fields can benefit from it. For the alleviation of this problem, it is necessary to know about how ensemble learning has developed under the era of deep learning. Thus, in this article, we present discussion focusing on data analyses of published works, the methodology and unattainability of traditional ensemble learning, and recent developments of ensemble deep learning. We hope this article will be helpful to realize the technical challenges faced by future developments of ensemble learning under the era of deep learning.
Real-time processing of high resolution video and 3D model-based tracking in remote tower operations
Oct 08, 2019
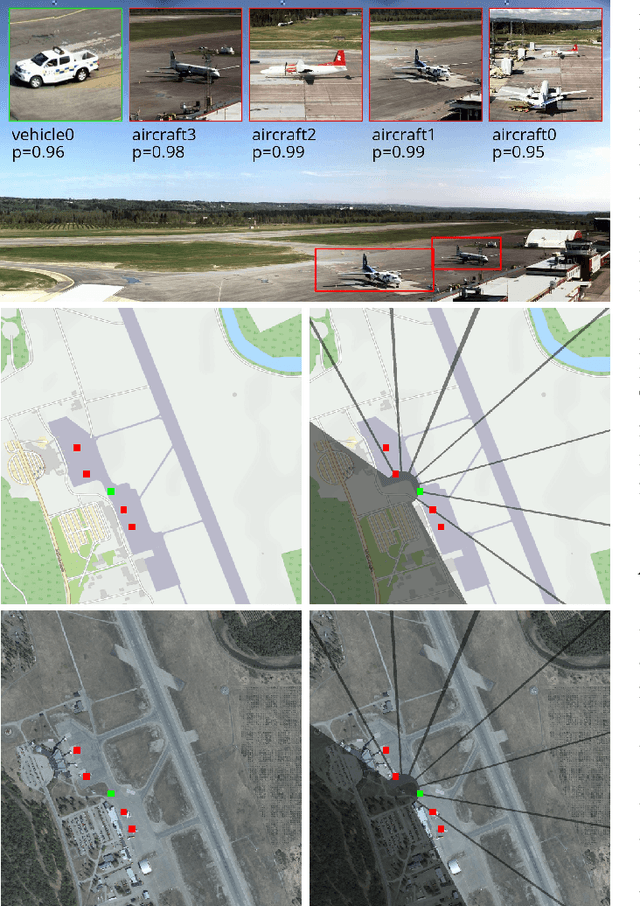

High quality video data is a core component in emerging remote tower operations as it inherently contains a huge amount of information on which an air traffic controller can base decisions. Various digital technologies also have the potential to exploit this data to bring enhancements, including tracking ground movements by relating events in the video view to their positions in 3D space. The total resolution of remote tower setups with multiple cameras often exceeds 25 million RGB pixels and is captured at 30 frames per second or more. It is thus a challenge to efficiently process all the data in such a way as to provide relevant real-time enhancements to the controller. In this paper we discuss how a number of improvements can be implemented efficiently on a single workstation by decoupling processes and utilizing hardware for parallel computing. We also highlight how decoupling the processes in this way increases resilience of the software solution in the sense that failure of a single component does not impair the function of the other components.
Localization and Control of Magnetic Suture Needles in Cluttered Surgical Site with Blood and Tissue
May 20, 2021
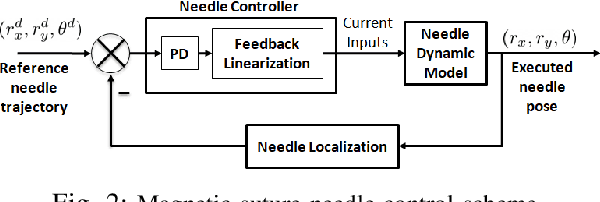
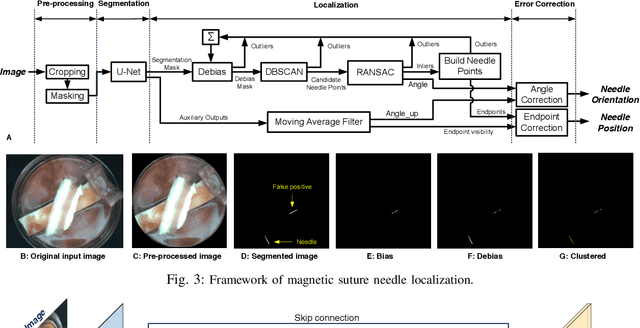
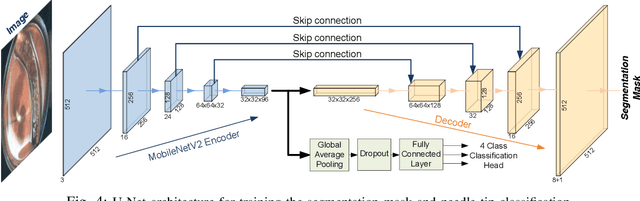
Real-time visual localization of needles is necessary for various surgical applications, including surgical automation and visual feedback. In this study we investigate localization and autonomous robotic control of needles in the context of our magneto-suturing system. Our system holds the potential for surgical manipulation with the benefit of minimal invasiveness and reduced patient side effects. However, the non-linear magnetic fields produce unintuitive forces and demand delicate position-based control that exceeds the capabilities of direct human manipulation. This makes automatic needle localization a necessity. Our localization method combines neural network-based segmentation and classical techniques, and we are able to consistently locate our needle with 0.73 mm RMS error in clean environments and 2.72 mm RMS error in challenging environments with blood and occlusion. The average localization RMS error is 2.16 mm for all environments we used in the experiments. We combine this localization method with our closed-loop feedback control system to demonstrate the further applicability of localization to autonomous control. Our needle is able to follow a running suture path in (1) no blood, no tissue; (2) heavy blood, no tissue; (3) no blood, with tissue; and (4) heavy blood, with tissue environments. The tip position tracking error ranges from 2.6 mm to 3.7 mm RMS, opening the door towards autonomous suturing tasks.
Integrated Decision and Control: Towards Interpretable and Efficient Driving Intelligence
Mar 18, 2021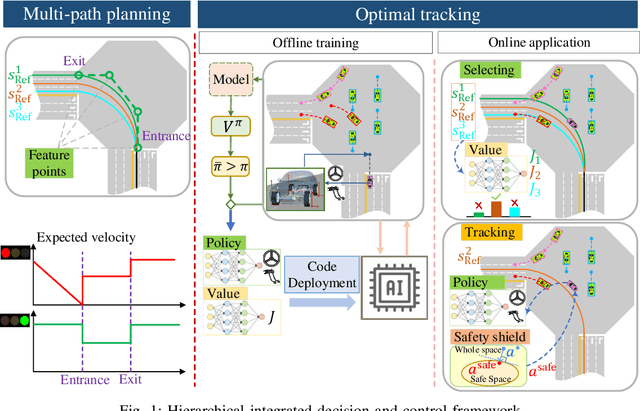
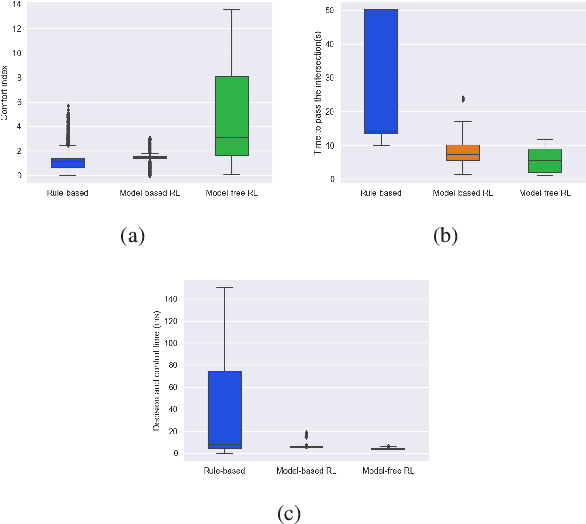
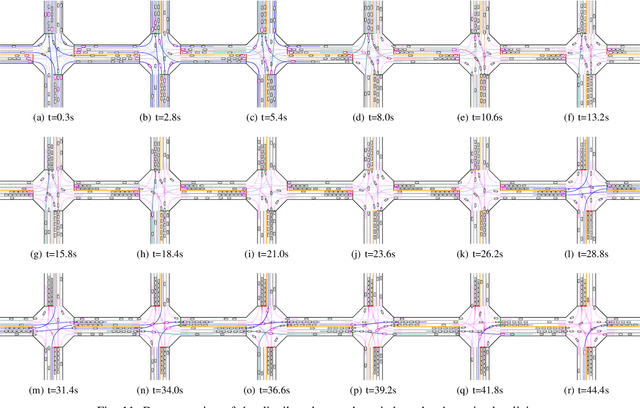
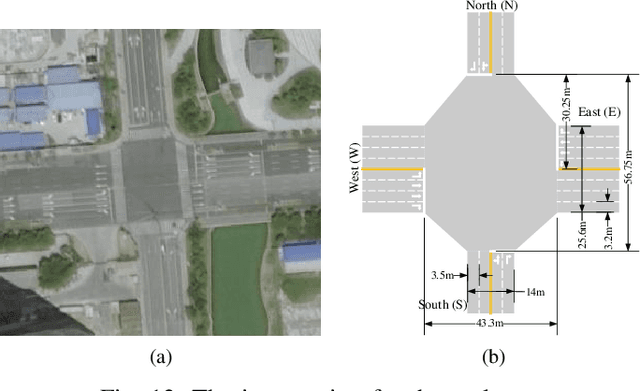
Decision and control are two of the core functionalities of high-level automated vehicles. Current mainstream methods, such as functionality decomposition or end-to-end reinforcement learning (RL), either suffer high time complexity or poor interpretability and limited safety performance in real-world complex autonomous driving tasks. In this paper, we present an interpretable and efficient decision and control framework for automated vehicles, which decomposes the driving task into multi-path planning and optimal tracking that are structured hierarchically. First, the multi-path planning is to generate several paths only considering static constraints. Then, the optimal tracking is designed to track the optimal path while considering the dynamic obstacles. To that end, in theory, we formulate a constrained optimal control problem (OCP) for each candidate path, optimize them separately and choose the one with the best tracking performance to follow. More importantly, we propose a model-based reinforcement learning (RL) algorithm, which is served as an approximate constrained OCP solver, to unload the heavy computation by the paradigm of offline training and online application. Specifically, the OCPs for all paths are considered together to construct a multi-task RL problem and then solved offline by our algorithm into value and policy networks, for real-time online path selecting and tracking respectively. We verify our framework in both simulation and the real world. Results show that our method has better online computing efficiency and driving performance including traffic efficiency and safety compared with baseline methods. In addition, it yields great interpretability and adaptability among different driving tasks. The real road test also suggests that it is applicable in complicated traffic scenarios without even tuning.
Packet-Loss-Tolerant Split Inference for Delay-Sensitive Deep Learning in Lossy Wireless Networks
Apr 28, 2021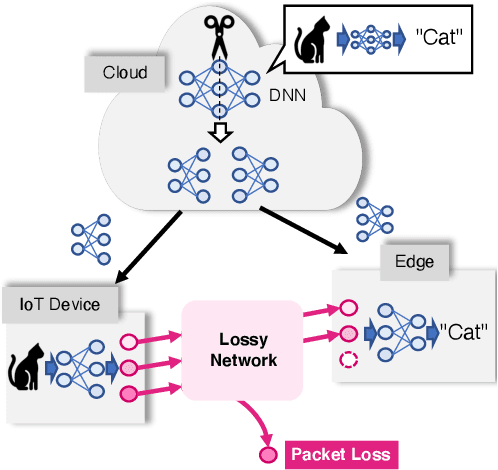
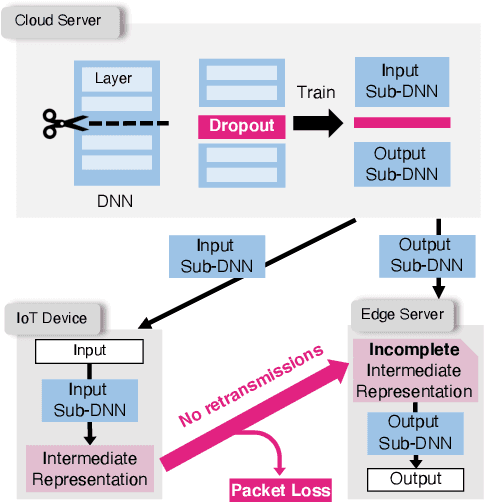
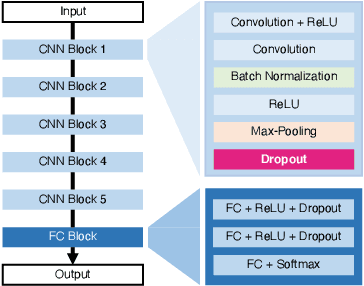
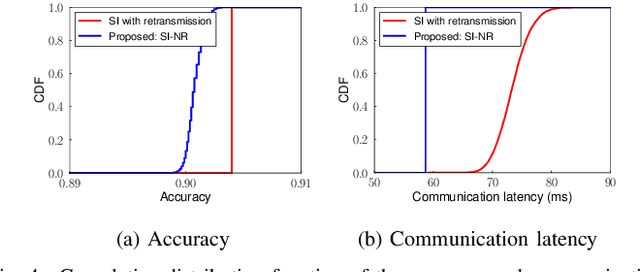
The distributed inference framework is an emerging technology for real-time applications empowered by cutting-edge deep machine learning (ML) on resource-constrained Internet of things (IoT) devices. In distributed inference, computational tasks are offloaded from the IoT device to other devices or the edge server via lossy IoT networks. However, narrow-band and lossy IoT networks cause non-negligible packet losses and retransmissions, resulting in non-negligible communication latency. This study solves the problem of the incremental retransmission latency caused by packet loss in a lossy IoT network. We propose a split inference with no retransmissions (SI-NR) method that achieves high accuracy without any retransmissions, even when packet loss occurs. In SI-NR, the key idea is to train the ML model by emulating the packet loss by a dropout method, which randomly drops the output of hidden units in a DNN layer. This enables the SI-NR system to obtain robustness against packet losses. Our ML experimental evaluation reveals that SI-NR obtains accurate predictions without packet retransmission at a packet loss rate of 60%.
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction
Apr 19, 2021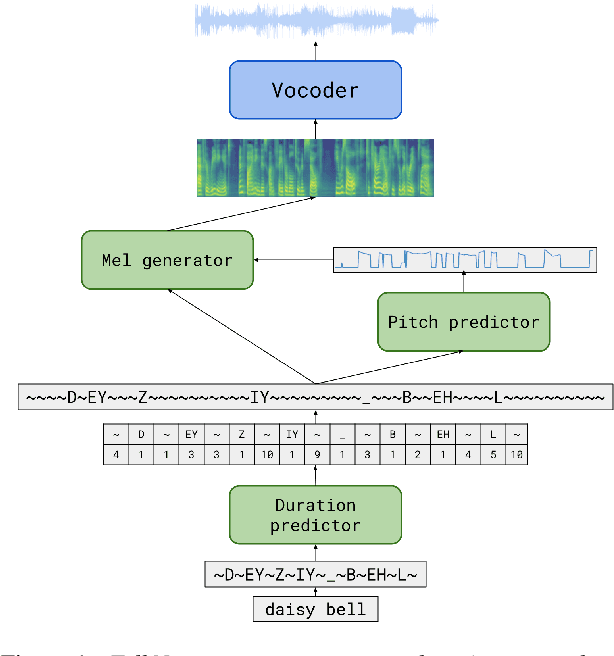
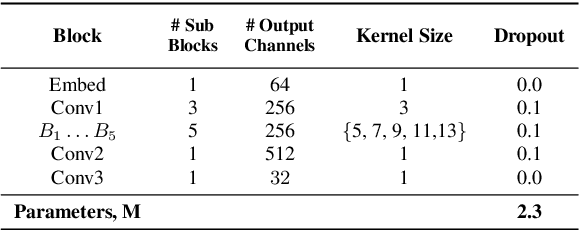
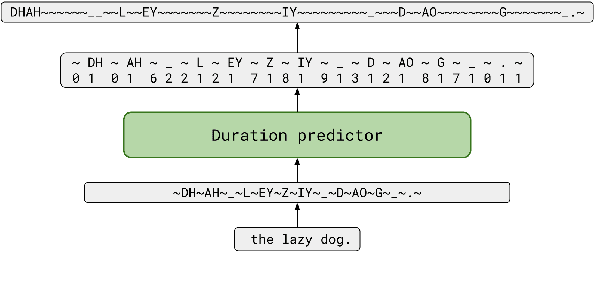
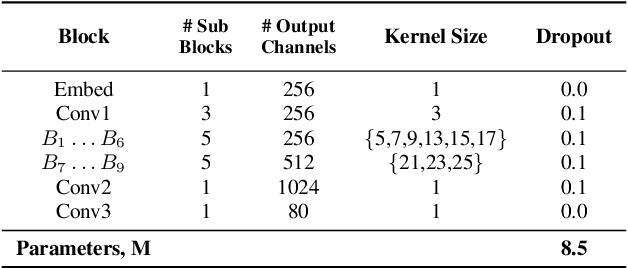
We propose TalkNet, a non-autoregressive convolutional neural model for speech synthesis with explicit pitch and duration prediction. The model consists of three feed-forward convolutional networks. The first network predicts grapheme durations. An input text is expanded by repeating each symbol according to the predicted duration. The second network predicts pitch value for every mel frame. The third network generates a mel-spectrogram from the expanded text conditioned on predicted pitch. All networks are based on 1D depth-wise separable convolutional architecture. The explicit duration prediction eliminates word skipping and repeating. The quality of the generated speech nearly matches the best auto-regressive models - TalkNet trained on the LJSpeech dataset got MOS4.08. The model has only 13.2M parameters, almost 2x less than the present state-of-the-art text-to-speech models. The non-autoregressive architecture allows for fast training and inference - 422x times faster than real-time. The small model size and fast inference make the TalkNet an attractive candidate for embedded speech synthesis.
Relation-aware Hierarchical Attention Framework for Video Question Answering
May 13, 2021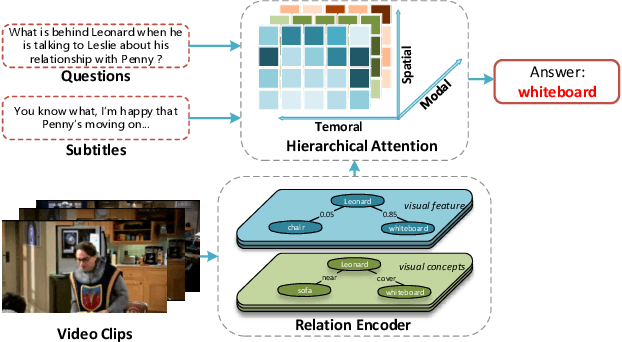
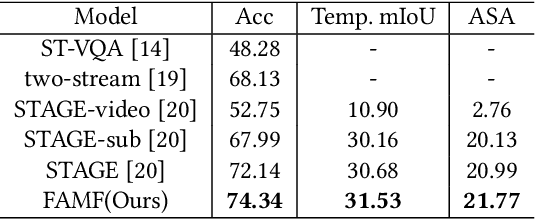
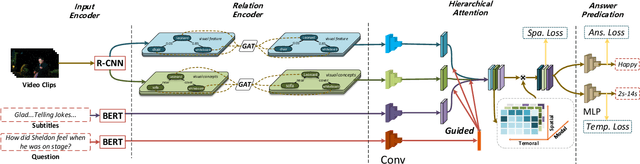
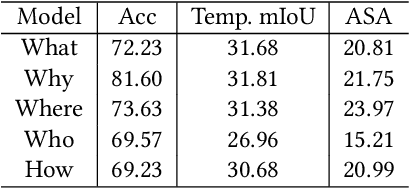
Video Question Answering (VideoQA) is a challenging video understanding task since it requires a deep understanding of both question and video. Previous studies mainly focus on extracting sophisticated visual and language embeddings, fusing them by delicate hand-crafted networks.However, the relevance of different frames, objects, and modalities to the question are varied along with the time, which is ignored in most of existing methods. Lacking understanding of the the dynamic relationships and interactions among objects brings a great challenge to VideoQA task.To address this problem, we propose a novel Relation-aware Hierarchical Attention (RHA) framework to learn both the static and dynamic relations of the objects in videos. In particular, videos and questions are embedded by pre-trained models firstly to obtain the visual and textual features. Then a graph-based relation encoder is utilized to extract the static relationship between visual objects.To capture the dynamic changes of multimodal objects in different video frames, we consider the temporal, spatial, and semantic relations, and fuse the multimodal features by hierarchical attention mechanism to predict the answer. We conduct extensive experiments on a large scale VideoQA dataset, and the experimental results demonstrate that our RHA outperforms the state-of-the-art methods.