 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning a Dynamic Map of Visual Appearance
Dec 29, 2020

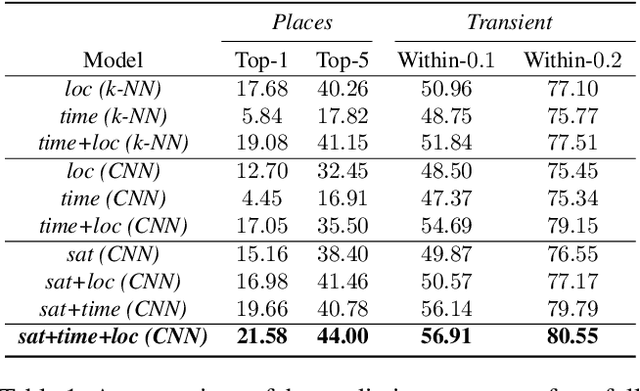

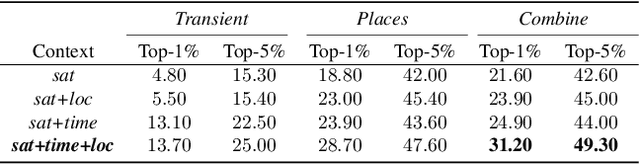
The appearance of the world varies dramatically not only from place to place but also from hour to hour and month to month. Every day billions of images capture this complex relationship, many of which are associated with precise time and location metadata. We propose to use these images to construct a global-scale, dynamic map of visual appearance attributes. Such a map enables fine-grained understanding of the expected appearance at any geographic location and time. Our approach integrates dense overhead imagery with location and time metadata into a general framework capable of mapping a wide variety of visual attributes. A key feature of our approach is that it requires no manual data annotation. We demonstrate how this approach can support various applications, including image-driven mapping, image geolocalization, and metadata verification.
Progressively Normalized Self-Attention Network for Video Polyp Segmentation
May 18, 2021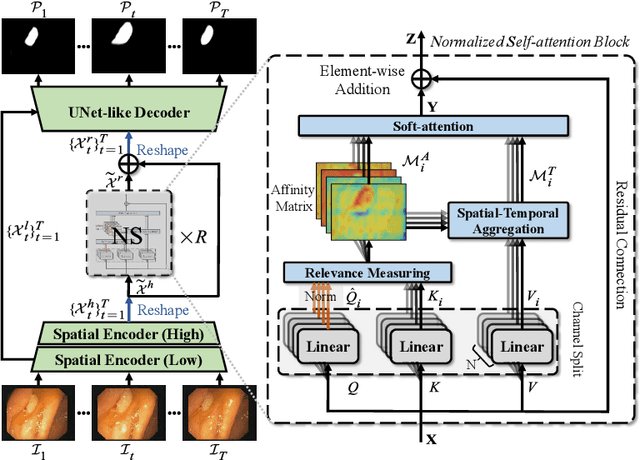
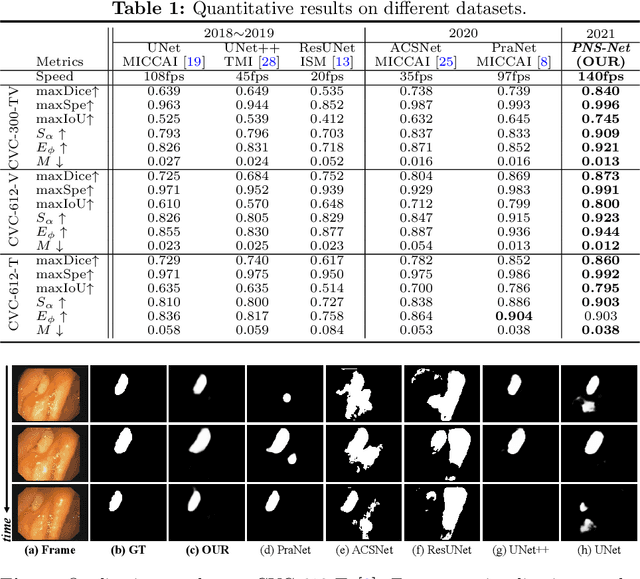
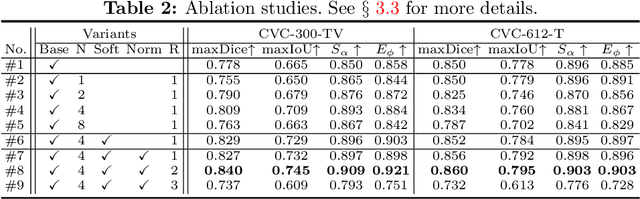
Existing video polyp segmentation (VPS) models typically employ convolutional neural networks (CNNs) to extract features. However, due to their limited receptive fields, CNNs can not fully exploit the global temporal and spatial information in successive video frames, resulting in false-positive segmentation results. In this paper, we propose the novel PNS-Net (Progressively Normalized Self-attention Network), which can efficiently learn representations from polyp videos with real-time speed (~140fps) on a single RTX 2080 GPU and no post-processing. Our PNS-Net is based solely on a basic normalized self-attention block, equipping with recurrence and CNNs entirely. Experiments on challenging VPS datasets demonstrate that the proposed PNS-Net achieves state-of-the-art performance. We also conduct extensive experiments to study the effectiveness of the channel split, soft-attention, and progressive learning strategy. We find that our PNS-Net works well under different settings, making it a promising solution to the VPS task.
When Can Liquid Democracy Unveil the Truth?
Apr 05, 2021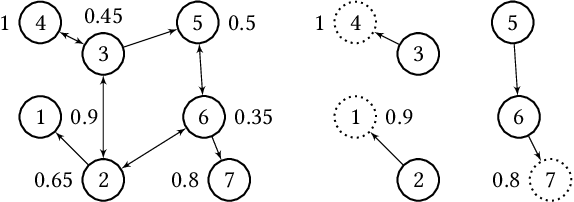
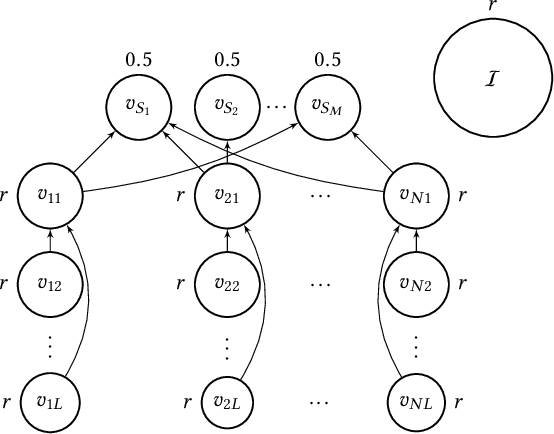
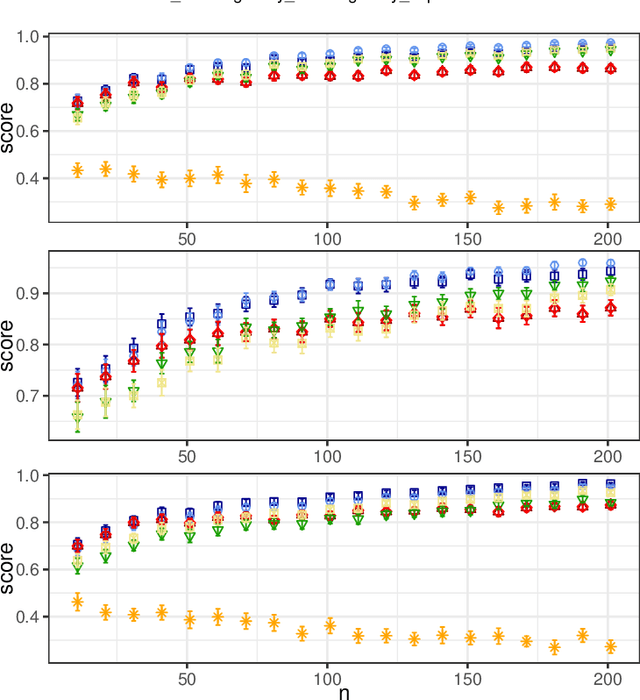
In this paper, we investigate the so-called ODP-problem that has been formulated by Caragiannis and Micha [10]. Here, we are in a setting with two election alternatives out of which one is assumed to be correct. In ODP, the goal is to organise the delegations in the social network in order to maximize the probability that the correct alternative, referred to as ground truth, is elected. While the problem is known to be computationally hard, we strengthen existing hardness results by providing a novel strong approximation hardness result: For any positive constant $C$, we prove that, unless $P=NP$, there is no polynomial-time algorithm for ODP that achieves an approximation guarantee of $\alpha \ge (\ln n)^{-C}$, where $n$ is the number of voters. The reduction designed for this result uses poorly connected social networks in which some voters suffer from misinformation. Interestingly, under some hypothesis on either the accuracies of voters or the connectivity of the network, we obtain a polynomial-time $1/2$-approximation algorithm. This observation proves formally that the connectivity of the social network is a key feature for the efficiency of the liquid democracy paradigm. Lastly, we run extensive simulations and observe that simple algorithms (working either in a centralized or decentralized way) outperform direct democracy on a large class of instances. Overall, our contributions yield new insights on the question in which situations liquid democracy can be beneficial.
Binarized Weight Error Networks With a Transition Regularization Term
May 09, 2021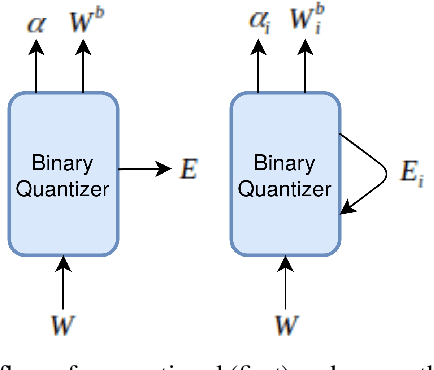
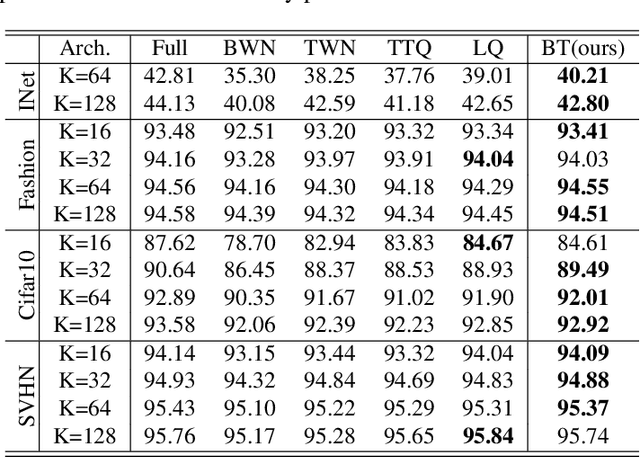

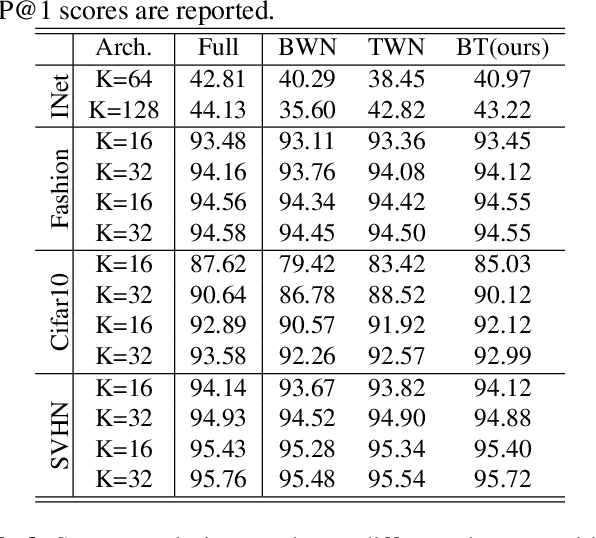
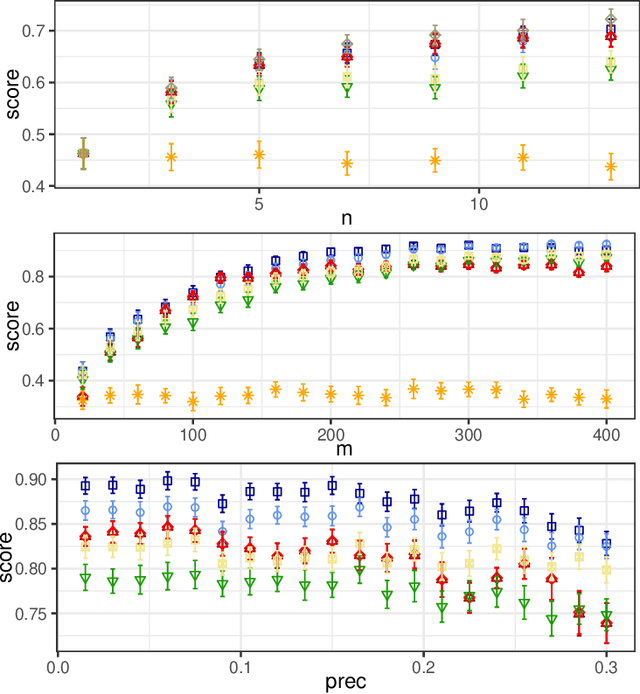
This paper proposes a novel binarized weight network (BT) for a resource-efficient neural structure. The proposed model estimates a binary representation of weights by taking into account the approximation error with an additional term. This model increases representation capacity and stability, particularly for shallow networks, while the computation load is theoretically reduced. In addition, a novel regularization term is introduced that is suitable for all threshold-based binary precision networks. This term penalizes the trainable parameters that are far from the thresholds at which binary transitions occur. This step promotes a swift modification for binary-precision responses at train time. The experimental results are carried out for two sets of tasks: visual classification and visual inverse problems. Benchmarks for Cifar10, SVHN, Fashion, ImageNet2012, Set5, Set14, Urban and BSD100 datasets show that our method outperforms all counterparts with binary precision.
Transform-Based Multilinear Dynamical System for Tensor Time Series Analysis
Nov 18, 2018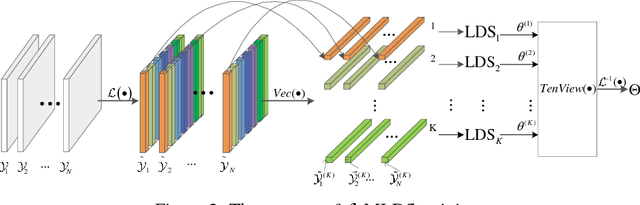
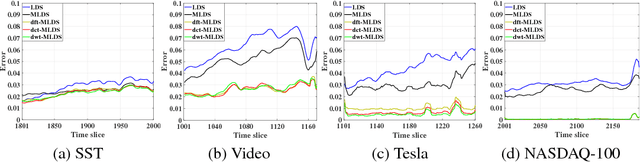
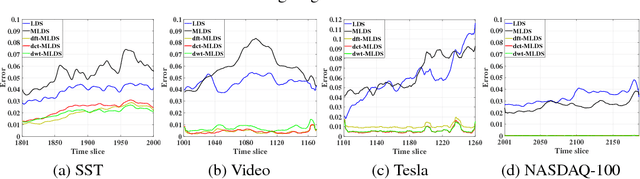
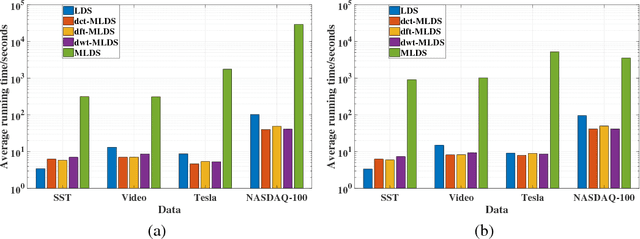
We propose a novel multilinear dynamical system (MLDS) in a transform domain, named $\mathcal{L}$-MLDS, to model tensor time series. With transformations applied to a tensor data, the latent multidimensional correlations among the frontal slices are built, and thus resulting in the computational independence in the transform domain. This allows the exact separability of the multi-dimensional problem into multiple smaller LDS problems. To estimate the system parameters, we utilize the expectation-maximization (EM) algorithm to determine the parameters of each LDS. Further, $\mathcal{L}$-MLDSs significantly reduce the model parameters and allows parallel processing. Our general $\mathcal{L}$-MLDS model is implemented based on different transforms: discrete Fourier transform, discrete cosine transform and discrete wavelet transform. Due to the nonlinearity of these transformations, $\mathcal{L}$-MLDS is able to capture the nonlinear correlations within the data unlike the MLDS \cite{rogers2013multilinear} which assumes multi-way linear correlations. Using four real datasets, the proposed $\mathcal{L}$-MLDS is shown to achieve much higher prediction accuracy than the state-of-the-art MLDS and LDS with an equal number of parameters under different noise models. In particular, the relative errors are reduced by $50\% \sim 99\%$. Simultaneously, $\mathcal{L}$-MLDS achieves an exponential improvement in the model's training time than MLDS.
Automatic Construction of Sememe Knowledge Bases via Dictionaries
May 26, 2021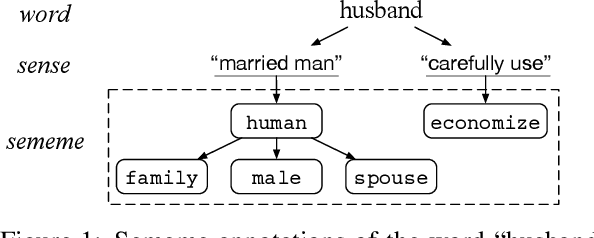
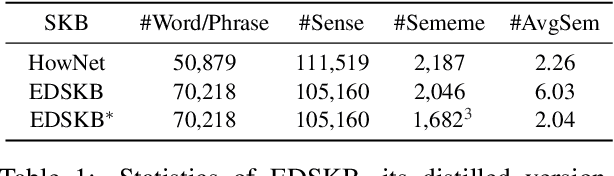

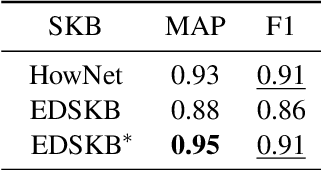
A sememe is defined as the minimum semantic unit in linguistics. Sememe knowledge bases (SKBs), which comprise words annotated with sememes, enable sememes to be applied to natural language processing. So far a large body of research has showcased the unique advantages and effectiveness of SKBs in various tasks. However, most languages have no SKBs, and manual construction of SKBs is time-consuming and labor-intensive. To tackle this challenge, we propose a simple and fully automatic method of building an SKB via an existing dictionary. We use this method to build an English SKB and a French SKB, and conduct comprehensive evaluations from both intrinsic and extrinsic perspectives. Experimental results demonstrate that the automatically built English SKB is even superior to HowNet, the most widely used SKB that takes decades to build manually. And both the English and French SKBs can bring obvious performance enhancement in multiple downstream tasks. All the code and data of this paper (except the copyrighted dictionaries) can be obtained at https://github.com/thunlp/DictSKB.
Analysis of bio-electro-chemical signals from passive sweat-based wearable electro-impedance spectroscopy (EIS) towards assessing blood glucose modulations
Apr 05, 2021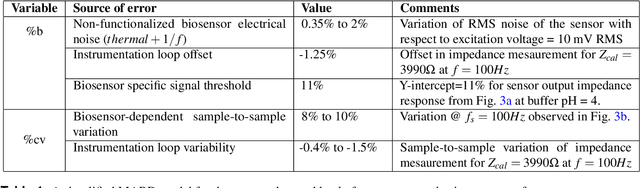
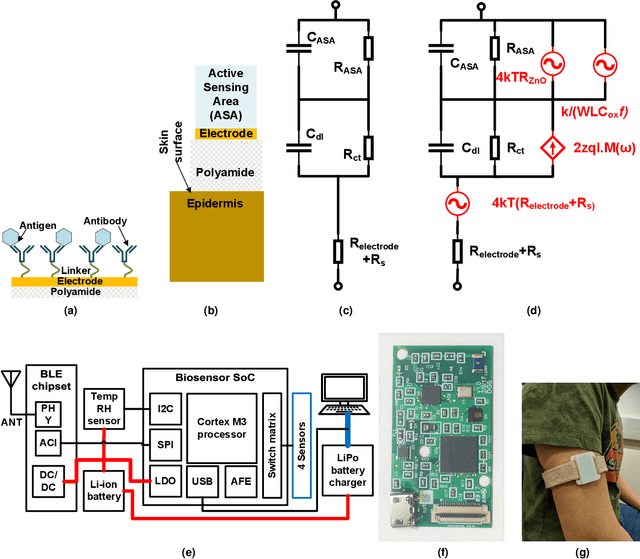
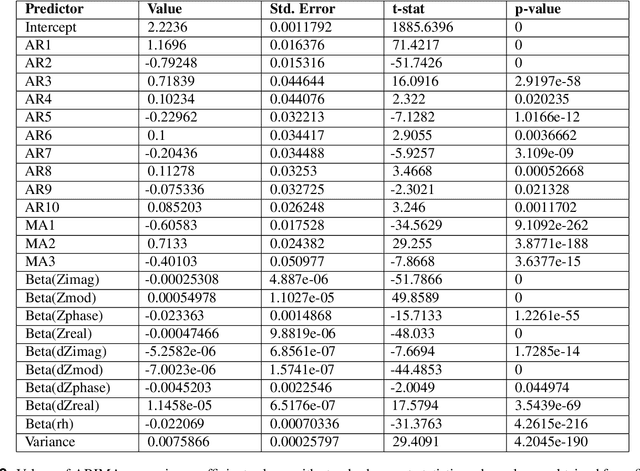
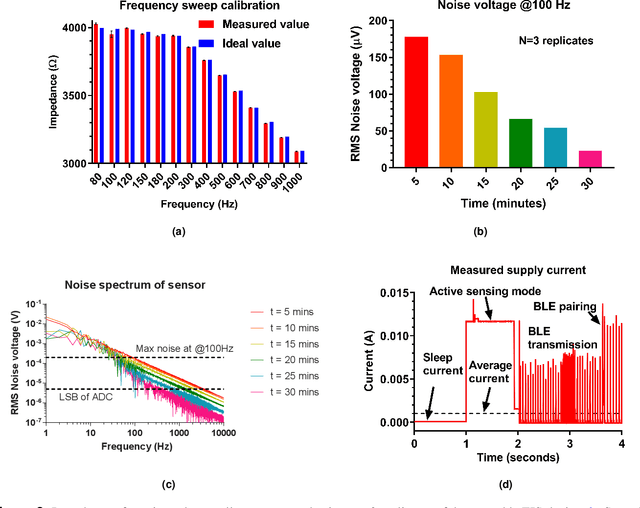
There has been a recent tremendous interest in label-free detection of biomarkers which is a critical enabler of point-of-need diagnostics. A low-power, small form factor, multiplexed wearable system is proposed for continuous detection of glucose in passively expressed sweat using electrochemical impedance spectroscopy (EIS) measurement. The wearable EIS system consists of a sensing analog front end integrated with low-volume (1-5 $\mu$L) ultra-sensitive flexible biosensors. A passive sweat sensor was designed to integrate a glucose oxidase electrochemical system on active semiconducting material. The non-faradaic EIS response of the biosensor was used to calibrate the analog front end response using ratiometric Discrete Fourier Transform (DFT) for a shorter measurement time. In this work, a stringent assessment of a continuous glucose sensing platform is performed in a bottom-up approach, going from the biosensor to the system to the interaction with a human subject. The active semiconductor-based biosensors are dosed with glucose concentrations ranging from 5-200 mg/dL and detection is performed using the analog front end. In addition, a detailed analysis of battery life and performance of a wearable EIS system is discussed to define a figure of merit for an optimally integrated design. Moreover, a continuous glucose detection test is performed on a healthy human subject cohort to investigate the stability of the sensor-system mechanism for an 8-hour period, and a time-series-based, auto-regressive (AR) model was created for the system.
Learning Temporal Dynamics from Cycles in Narrated Video
Jan 07, 2021
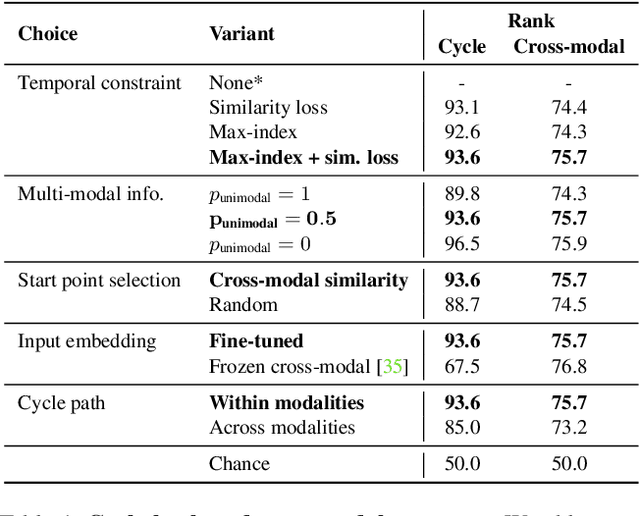
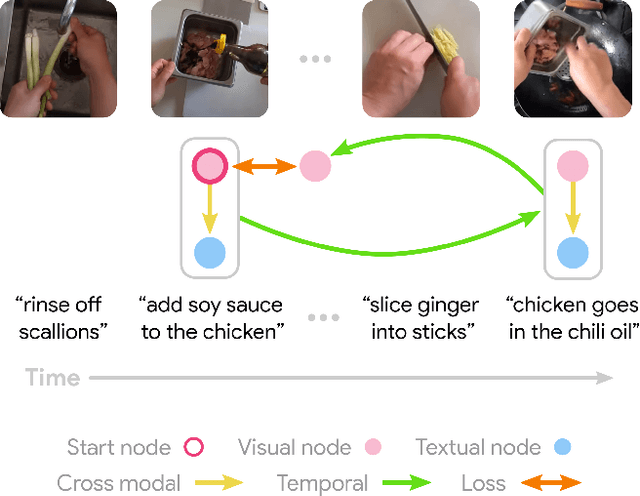
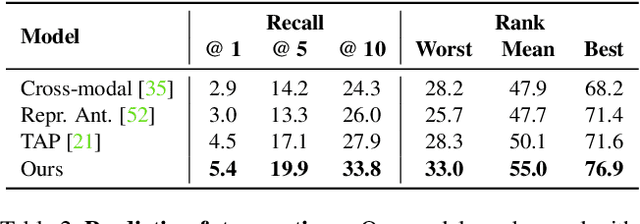
Learning to model how the world changes as time elapses has proven a challenging problem for the computer vision community. We propose a self-supervised solution to this problem using temporal cycle consistency jointly in vision and language, training on narrated video. Our model learns modality-agnostic functions to predict forward and backward in time, which must undo each other when composed. This constraint leads to the discovery of high-level transitions between moments in time, since such transitions are easily inverted and shared across modalities. We justify the design of our model with an ablation study on different configurations of the cycle consistency problem. We then show qualitatively and quantitatively that our approach yields a meaningful, high-level model of the future and past. We apply the learned dynamics model without further training to various tasks, such as predicting future action and temporally ordering sets of images.
Alleviate Exposure Bias in Sequence Prediction \\ with Recurrent Neural Networks
Mar 22, 2021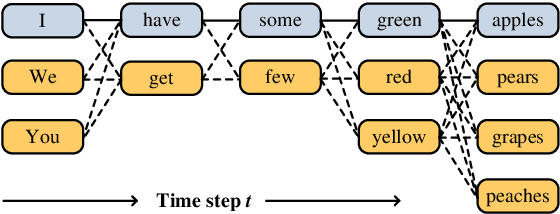
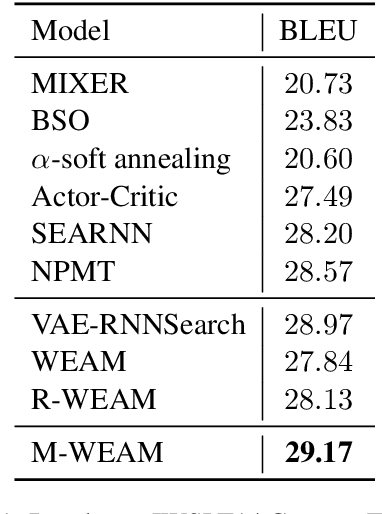
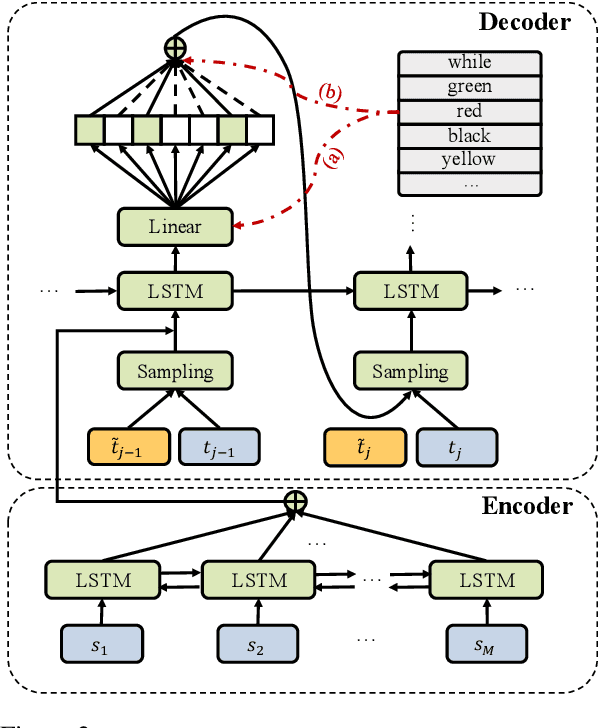
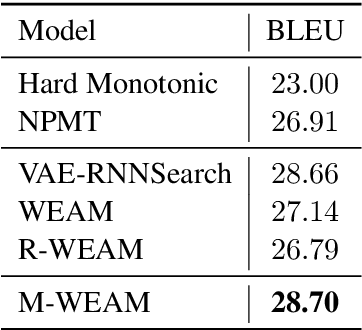
A popular strategy to train recurrent neural networks (RNNs), known as ``teacher forcing'' takes the ground truth as input at each time step and makes the later predictions partly conditioned on those inputs. Such training strategy impairs their ability to learn rich distributions over entire sequences because the chosen inputs hinders the gradients back-propagating to all previous states in an end-to-end manner. We propose a fully differentiable training algorithm for RNNs to better capture long-term dependencies by recovering the probability of the whole sequence. The key idea is that at each time step, the network takes as input a ``bundle'' of similar words predicted at the previous step instead of a single ground truth. The representations of these similar words forms a convex hull, which can be taken as a kind of regularization to the input. Smoothing the inputs by this way makes the whole process trainable and differentiable. This design makes it possible for the model to explore more feasible combinations (possibly unseen sequences), and can be interpreted as a computationally efficient approximation to the beam search. Experiments on multiple sequence generation tasks yield performance improvements, especially in sequence-level metrics, such as BLUE or ROUGE-2.
Deep Extended Feedback Codes
May 04, 2021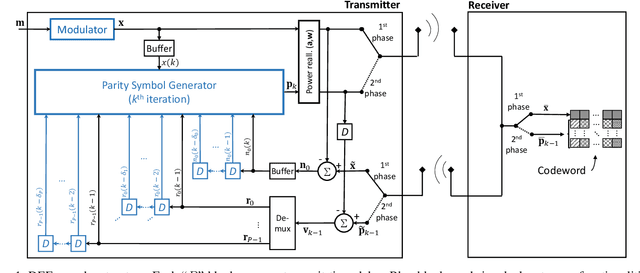
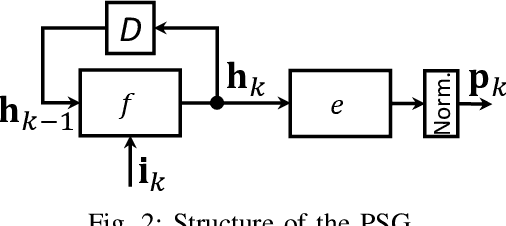
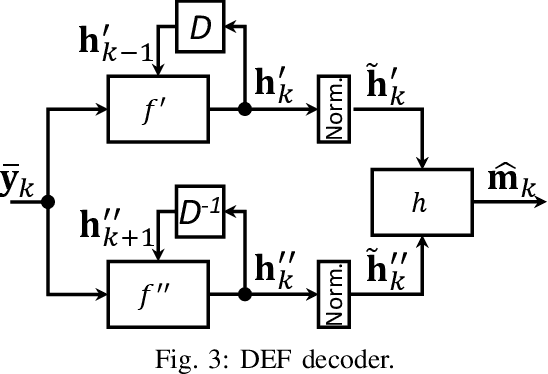
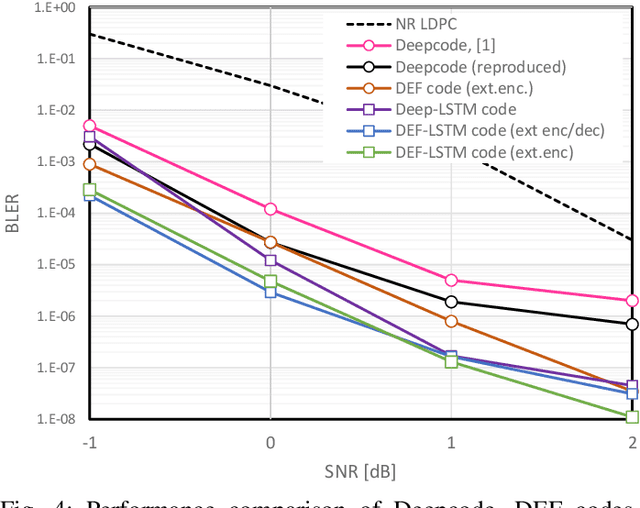
A new deep-neural-network (DNN) based error correction encoder architecture for channels with feedback, called Deep Extended Feedback (DEF), is presented in this paper. The encoder in the DEF architecture transmits an information message followed by a sequence of parity symbols which are generated based on the message as well as the observations of the past forward channel outputs sent to the transmitter through a feedback channel. DEF codes generalize Deepcode [1] in several ways: parity symbols are generated based on forward-channel output observations over longer time intervals in order to provide better error correction capability; and high-order modulation formats are deployed in the encoder so as to achieve increased spectral efficiency. Performance evaluations show that DEF codes have better performance compared to other DNN-based codes for channels with feedback.