 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviate Exposure Bias in Sequence Prediction \\ with Recurrent Neural Networks
Paper and Code
Mar 22, 2021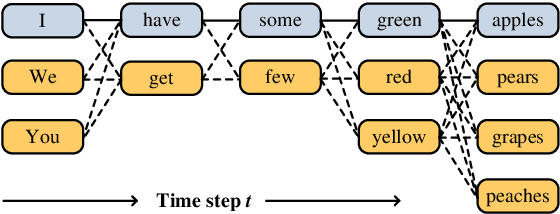
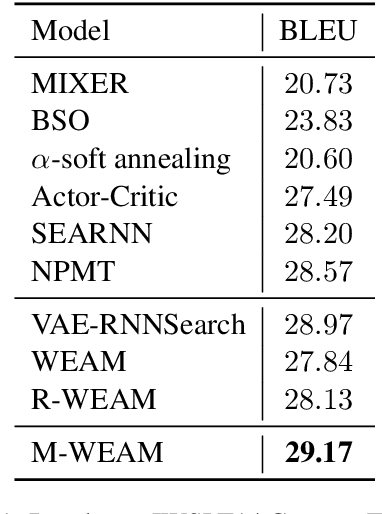
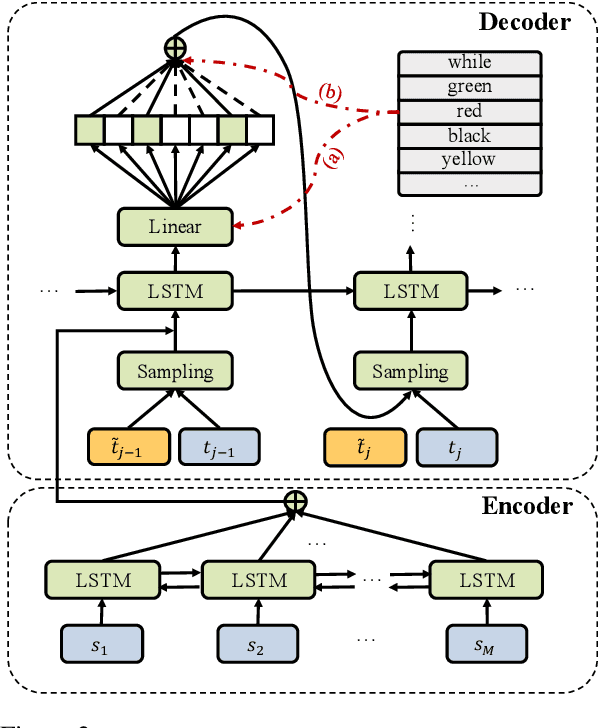
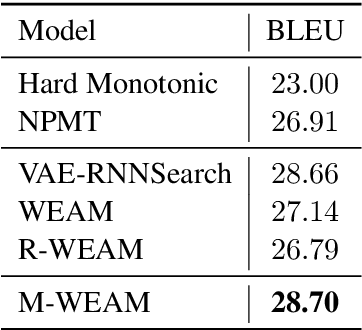
A popular strategy to train recurrent neural networks (RNNs), known as ``teacher forcing'' takes the ground truth as input at each time step and makes the later predictions partly conditioned on those inputs. Such training strategy impairs their ability to learn rich distributions over entire sequences because the chosen inputs hinders the gradients back-propagating to all previous states in an end-to-end manner. We propose a fully differentiable training algorithm for RNNs to better capture long-term dependencies by recovering the probability of the whole sequence. The key idea is that at each time step, the network takes as input a ``bundle'' of similar words predicted at the previous step instead of a single ground truth. The representations of these similar words forms a convex hull, which can be taken as a kind of regularization to the input. Smoothing the inputs by this way makes the whole process trainable and differentiable. This design makes it possible for the model to explore more feasible combinations (possibly unseen sequences), and can be interpreted as a computationally efficient approximation to the beam search. Experiments on multiple sequence generation tasks yield performance improvements, especially in sequence-level metrics, such as BLUE or ROUGE-2.