 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCache-enabled Generative Joint Source-Channel Coding for Evolving Semantic Communications
Mar 18, 2026Learning-based semantic communication (SemCom) has recently emerged as a promising paradigm for improving the transmission efficiency of wireless networks. However, existing methods typically rely on extensive end-to-end training, which is both inflexible and computationally expensive in dynamic wireless environments. Moreover, they fail to exploit redundancy across multiple transmissions of semantically similar content, limiting overall efficiency. To overcome these limitations, we propose a channel-aware generative adversarial network (GAN) inversion-based joint source-channel coding (CAGI-JSCC) framework that enables training-free SemCom by leveraging a pre-trained SemanticStyleGAN model. By explicitly incorporating wireless channel characteristics into the GAN inversion process, CAGI-JSCC adapts to varying channel conditions without additional training. Furthermore, we introduce a cache-enabled dynamic codebook (CDC) that caches disentangled semantic components at both the transmitter and receiver, allowing the system to reuse previously transmitted content. This semantic-level caching can continuously reduce redundant transmissions as experience accumulates. Extensive experiments on image transmission demonstrate the effectiveness of the proposed framework. In particular, our system achieves comparable perceptual quality with an average bandwidth compression ratio (BCR) of 1/224, and as low as 1/1024 for a single image, significantly outperforming baselines with a BCR of 1/128.
Wireless Physical Neural Networks (WPNNs): Opportunities and Challenges
Feb 15, 2026Wireless communication systems exhibit structural and functional similarities to neural networks: signals propagate through cascaded elements, interact with the environment, and undergo transformations. Building upon this perspective, we introduce a unified paradigm, termed \textit{wireless physical neural networks (WPNNs)}, in which components of a wireless network, such as transceivers, relays, backscatter, and intelligent surfaces, are interpreted as computational layers within a learning architecture. By treating the wireless propagation environment and network elements as differentiable operators, new opportunities arise for joint communication-computation designs, where system optimization can be achieved through learning-based methods applied directly to the physical network. This approach may operate independently of, or in conjunction with, conventional digital neural layers, enabling hybrid communication learning pipelines. In the article, we outline representative architectures that embody this viewpoint and discuss the algorithmic and training considerations required to leverage the wireless medium as a computational resource. Through numerical examples, we highlight the potential performance gains in processing, adaptability, efficiency, and end-to-end optimization, demonstrating the promise of reconfiguring wireless systems as learning networks in next-generation communication frameworks.
Diffusion-aided Extreme Video Compression with Lightweight Semantics Guidance
Feb 05, 2026Modern video codecs and learning-based approaches struggle for semantic reconstruction at extremely low bit-rates due to reliance on low-level spatiotemporal redundancies. Generative models, especially diffusion models, offer a new paradigm for video compression by leveraging high-level semantic understanding and powerful visual synthesis. This paper propose a video compression framework that integrates generative priors to drastically reduce bit-rate while maintaining reconstruction fidelity. Specifically, our method compresses high-level semantic representations of the video, then uses a conditional diffusion model to reconstruct frames from these semantics. To further improve compression, we characterize motion information with global camera trajectories and foreground segmentation: background motion is compactly represented by camera pose parameters while foreground dynamics by sparse segmentation masks. This allows for significantly boosts compression efficiency, enabling descent video reconstruction at extremely low bit-rates.
Towards AI-Native Fronthaul: Neural Compression for NextG Cloud RAN
Jun 07, 2025The rapid growth of data traffic and the emerging AI-native wireless architectures in NextG cellular systems place new demands on the fronthaul links of Cloud Radio Access Networks (C-RAN). In this paper, we investigate neural compression techniques for the Common Public Radio Interface (CPRI), aiming to reduce the fronthaul bandwidth while preserving signal quality. We introduce two deep learning-based compression algorithms designed to optimize the transformation of wireless signals into bit sequences for CPRI transmission. The first algorithm utilizes a non-linear transformation coupled with scalar/vector quantization based on a learned codebook. The second algorithm generates a latent vector transformed into a variable-length output bit sequence via arithmetic encoding, guided by the predicted probability distribution of each latent element. Novel techniques such as a shared weight model for storage-limited devices and a successive refinement model for managing multiple CPRI links with varying Quality of Service (QoS) are proposed. Extensive simulation results demonstrate notable Error Vector Magnitude (EVM) gains with improved rate-distortion performance for both algorithms compared to traditional methods. The proposed solutions are robust to variations in channel conditions, modulation formats, and noise levels, highlighting their potential for enabling efficient and scalable fronthaul in NextG AI-native networks as well as aligning with the current 3GPP research directions.
Over-the-Air Inference over Multi-hop MIMO Networks
May 01, 2025A novel over-the-air machine learning framework over multi-hop multiple-input and multiple-output (MIMO) networks is proposed. The core idea is to imitate fully connected (FC) neural network layers using multiple MIMO channels by carefully designing the precoding matrices at the transmitting nodes. A neural network dubbed PrototypeNet is employed consisting of multiple FC layers, with the number of neurons of each layer equal to the number of antennas of the corresponding terminal. To achieve satisfactory performance, we train PrototypeNet based on a customized loss function consisting of classification error and the power of latent vectors to satisfy transmit power constraints, with noise injection during training. Precoding matrices for each hop are then obtained by solving an optimization problem. We also propose a multiple-block extension when the number of antennas is limited. Numerical results verify that the proposed over-the-air transmission scheme can achieve satisfactory classification accuracy under a power constraint. The results also show that higher classification accuracy can be achieved with an increasing number of hops at a modest signal-to-noise ratio (SNR).
Sparse Regression Codes for Integrated Passive Sensing and Communications
Nov 08, 2024



We propose a novel integrated sensing and communication (ISAC) system, where the base station (BS) passively senses the channel parameters using the information carrying signals from a user. To simultaneously guarantee decoding and sensing performance, the user adopts sparse regression codes (SPARCs) with cyclic redundancy check (CRC) to transmit its information bits. The BS generates an initial coarse channel estimation of the parameters after receiving the pilot signal. Then, a novel iterative decoding and parameter sensing algorithm is proposed, where the correctly decoded codewords indicated by the CRC bits are utilized to improve the sensing and channel estimation performance at the BS. In turn, the improved estimate of the channel parameters lead to a better decoding performance. Simulation results show the effectiveness of the proposed iterative decoding and sensing algorithm, where both the sensing and the communication performance are significantly improved with a few iterations. Extensive ablation studies concerning different channel estimation methods and number of CRC bits are carried out for a comprehensive evaluation of the proposed scheme.
LISAC: Learned Coded Waveform Design for ISAC with OFDM
Oct 14, 2024



We propose a novel deep learning based method to design a coded waveform for integrated sensing and communication (ISAC) system based on orthogonal frequency-division multiplexing (OFDM). Our ultimate goal is to design a coded waveform, which is capable of providing satisfactory sensing performance of the target while maintaining high communication quality measured in terms of the bit error rate (BER). The proposed LISAC provides an improved waveform design with the assistance of deep neural networks for the encoding and decoding of the information bits. In particular, the transmitter, parameterized by a recurrent neural network (RNN), encodes the input bit sequence into the transmitted waveform for both sensing and communications. The receiver employs a RNN-based decoder to decode the information bits while the transmitter senses the target via maximum likelihood detection. We optimize the system considering both the communication and sensing performance. Simulation results show that the proposed LISAC waveform achieves a better trade-off curve compared to existing alternatives.
GINO-Q: Learning an Asymptotically Optimal Index Policy for Restless Multi-armed Bandits
Aug 19, 2024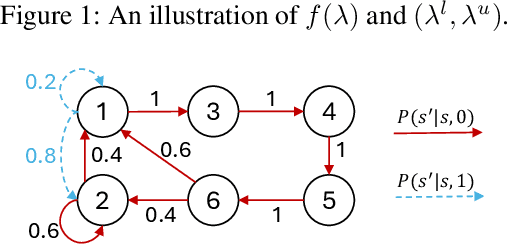
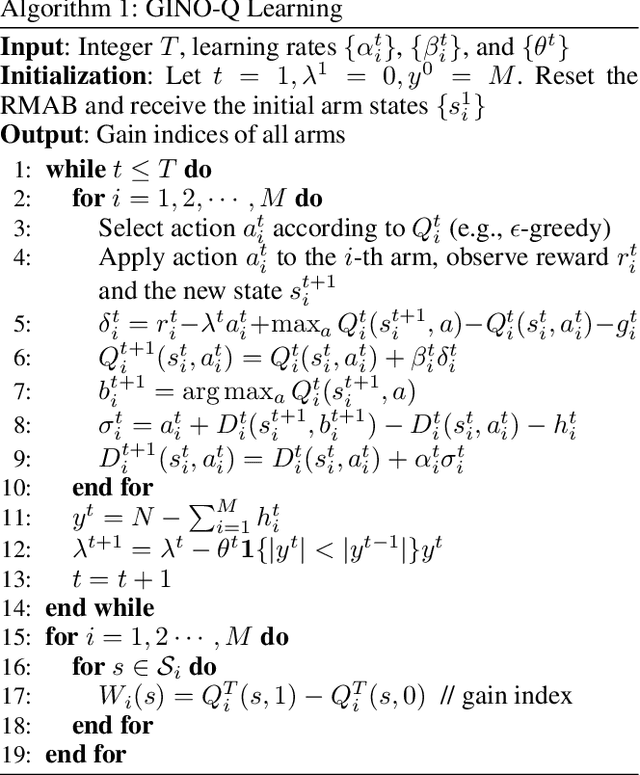
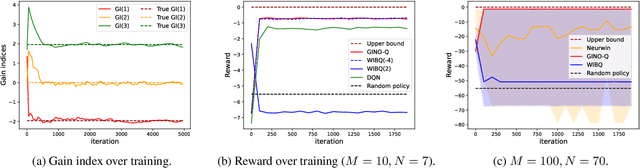
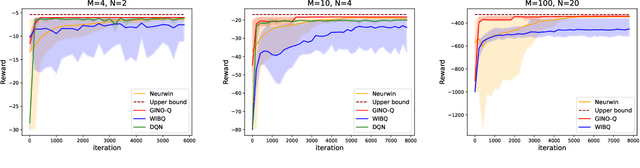
The restless multi-armed bandit (RMAB) framework is a popular model with applications across a wide variety of fields. However, its solution is hindered by the exponentially growing state space (with respect to the number of arms) and the combinatorial action space, making traditional reinforcement learning methods infeasible for large-scale instances. In this paper, we propose GINO-Q, a three-timescale stochastic approximation algorithm designed to learn an asymptotically optimal index policy for RMABs. GINO-Q mitigates the curse of dimensionality by decomposing the RMAB into a series of subproblems, each with the same dimension as a single arm, ensuring that complexity increases linearly with the number of arms. Unlike recently developed Whittle-index-based algorithms, GINO-Q does not require RMABs to be indexable, enhancing its flexibility and applicability. Our experimental results demonstrate that GINO-Q consistently learns near-optimal policies, even for non-indexable RMABs where Whittle-index-based algorithms perform poorly, and it converges significantly faster than existing baselines.
Private Collaborative Edge Inference via Over-the-Air Computation
Jul 30, 2024



We consider collaborative inference at the wireless edge, where each client's model is trained independently on their local datasets. Clients are queried in parallel to make an accurate decision collaboratively. In addition to maximizing the inference accuracy, we also want to ensure the privacy of local models. To this end, we leverage the superposition property of the multiple access channel to implement bandwidth-efficient multi-user inference methods. Specifically, we propose different methods for ensemble and multi-view classification that exploit over-the-air computation. We show that these schemes perform better than their orthogonal counterparts with statistically significant differences while using fewer resources and providing privacy guarantees. We also provide experimental results verifying the benefits of the proposed over-the-air multi-user inference approach and perform an ablation study to demonstrate the effectiveness of our design choices. We share the source code of the framework publicly on Github to facilitate further research and reproducibility.
Aggressive or Imperceptible, or Both: Network Pruning Assisted Hybrid Byzantines in Federated Learning
Apr 09, 2024



Federated learning (FL) has been introduced to enable a large number of clients, possibly mobile devices, to collaborate on generating a generalized machine learning model thanks to utilizing a larger number of local samples without sharing to offer certain privacy to collaborating clients. However, due to the participation of a large number of clients, it is often difficult to profile and verify each client, which leads to a security threat that malicious participants may hamper the accuracy of the trained model by conveying poisoned models during the training. Hence, the aggregation framework at the parameter server also needs to minimize the detrimental effects of these malicious clients. A plethora of attack and defence strategies have been analyzed in the literature. However, often the Byzantine problem is analyzed solely from the outlier detection perspective, being oblivious to the topology of neural networks (NNs). In the scope of this work, we argue that by extracting certain side information specific to the NN topology, one can design stronger attacks. Hence, inspired by the sparse neural networks, we introduce a hybrid sparse Byzantine attack that is composed of two parts: one exhibiting a sparse nature and attacking only certain NN locations with higher sensitivity, and the other being more silent but accumulating over time, where each ideally targets a different type of defence mechanism, and together they form a strong but imperceptible attack. Finally, we show through extensive simulations that the proposed hybrid Byzantine attack is effective against 8 different defence methods.