 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraged Weighted Loss for Partial Label Learning
Jun 10, 2021
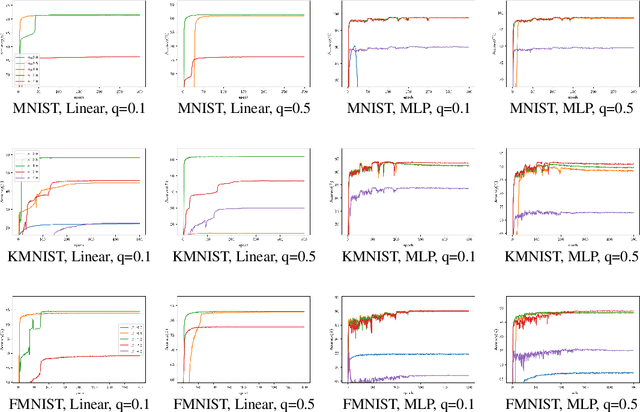
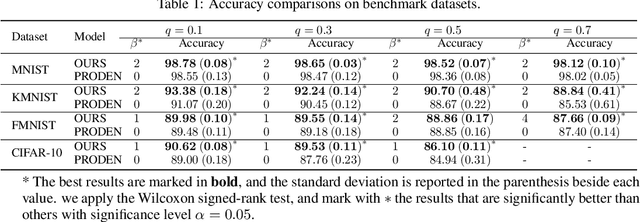
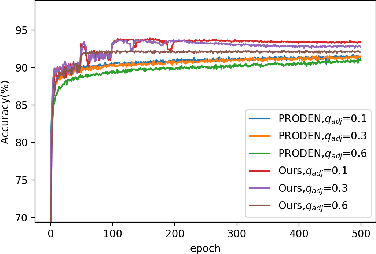
As an important branch of weakly supervised learning, partial label learning deals with data where each instance is assigned with a set of candidate labels, whereas only one of them is true. Despite many methodology studies on learning from partial labels, there still lacks theoretical understandings of their risk consistent properties under relatively weak assumptions, especially on the link between theoretical results and the empirical choice of parameters. In this paper, we propose a family of loss functions named \textit{Leveraged Weighted} (LW) loss, which for the first time introduces the leverage parameter $\beta$ to consider the trade-off between losses on partial labels and non-partial ones. From the theoretical side, we derive a generalized result of risk consistency for the LW loss in learning from partial labels, based on which we provide guidance to the choice of the leverage parameter $\beta$. In experiments, we verify the theoretical guidance, and show the high effectiveness of our proposed LW loss on both benchmark and real datasets compared with other state-of-the-art partial label learning algorithms.
LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations
Jun 02, 2021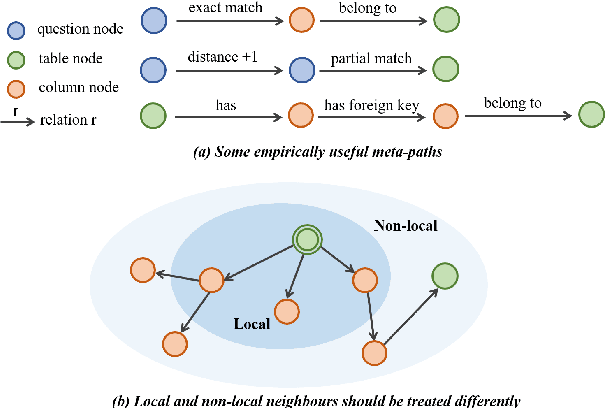
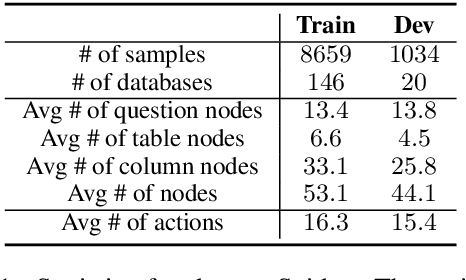
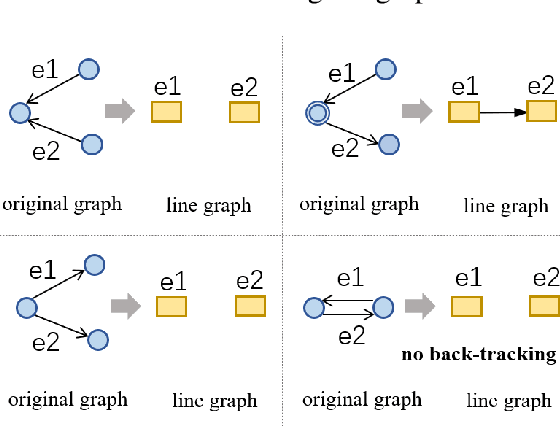
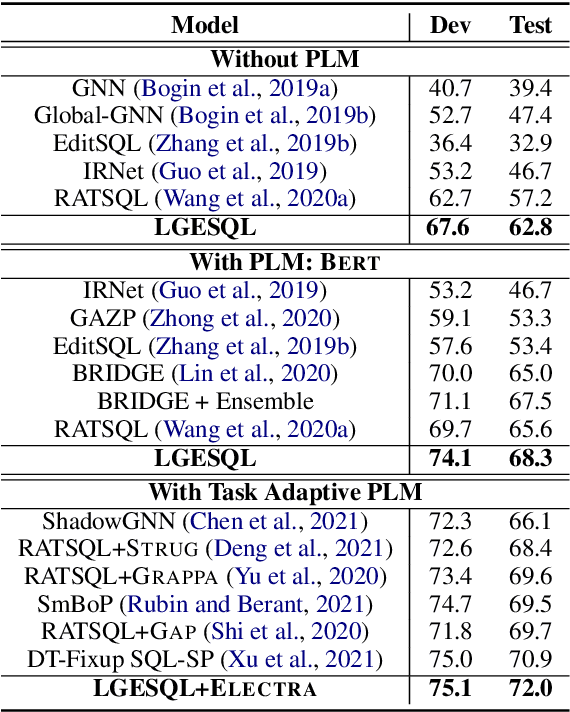
This work aims to tackle the challenging heterogeneous graph encoding problem in the text-to-SQL task. Previous methods are typically node-centric and merely utilize different weight matrices to parameterize edge types, which 1) ignore the rich semantics embedded in the topological structure of edges, and 2) fail to distinguish local and non-local relations for each node. To this end, we propose a Line Graph Enhanced Text-to-SQL (LGESQL) model to mine the underlying relational features without constructing meta-paths. By virtue of the line graph, messages propagate more efficiently through not only connections between nodes, but also the topology of directed edges. Furthermore, both local and non-local relations are integrated distinctively during the graph iteration. We also design an auxiliary task called graph pruning to improve the discriminative capability of the encoder. Our framework achieves state-of-the-art results (62.8% with Glove, 72.0% with Electra) on the cross-domain text-to-SQL benchmark Spider at the time of writing.
InstantNet: Automated Generation and Deployment of Instantaneously Switchable-Precision Networks
Apr 22, 2021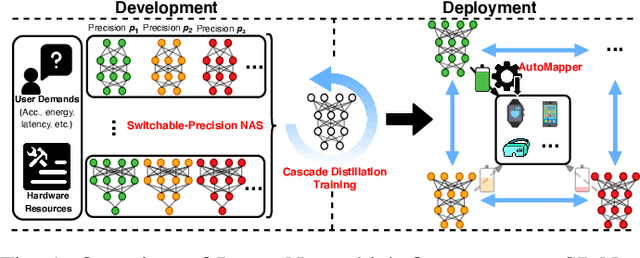
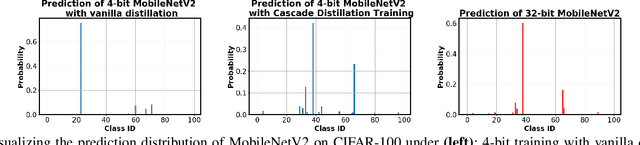
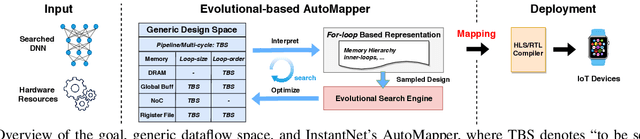
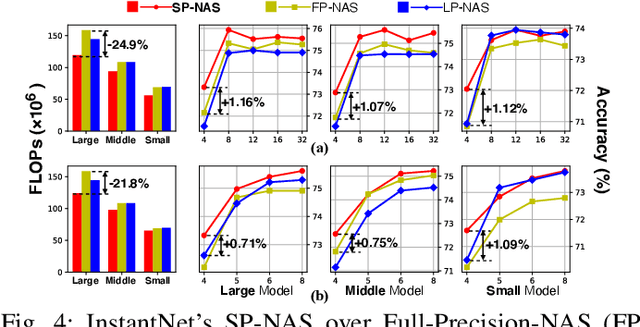
The promise of Deep Neural Network (DNN) powered Internet of Thing (IoT) devices has motivated a tremendous demand for automated solutions to enable fast development and deployment of efficient (1) DNNs equipped with instantaneous accuracy-efficiency trade-off capability to accommodate the time-varying resources at IoT devices and (2) dataflows to optimize DNNs' execution efficiency on different devices. Therefore, we propose InstantNet to automatically generate and deploy instantaneously switchable-precision networks which operate at variable bit-widths. Extensive experiments show that the proposed InstantNet consistently outperforms state-of-the-art designs.
Self-training with noisy student model and semi-supervised loss function for dcase 2021 challenge task 4
Jul 06, 2021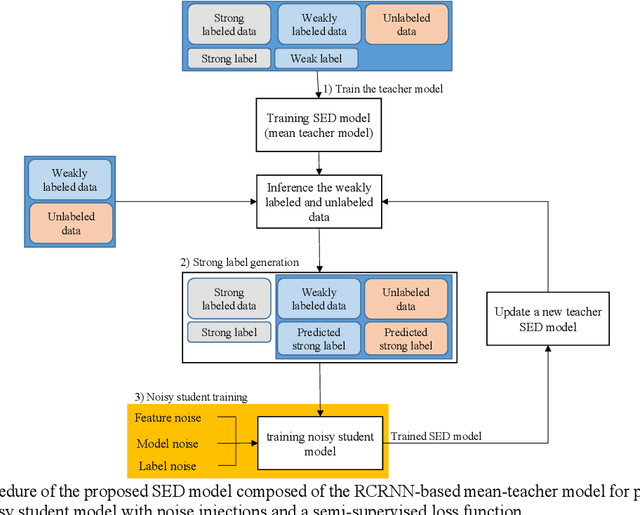
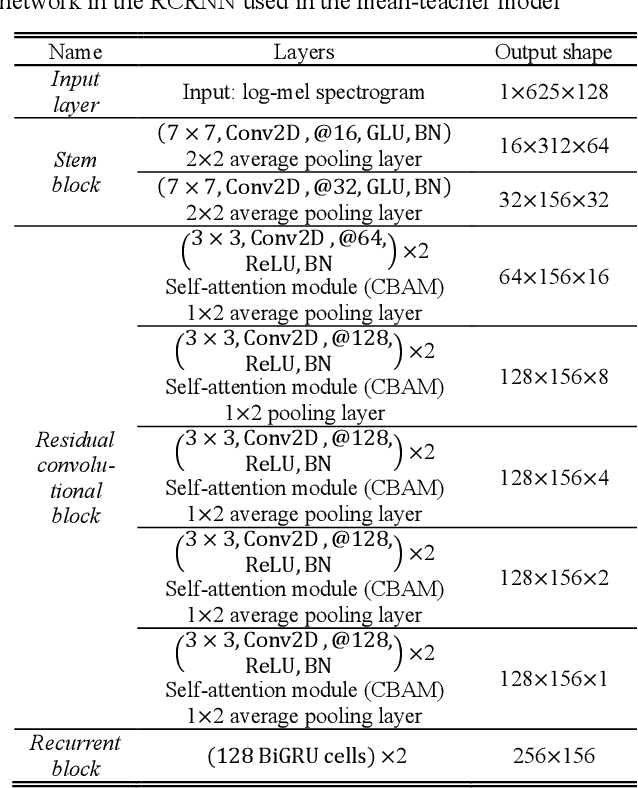
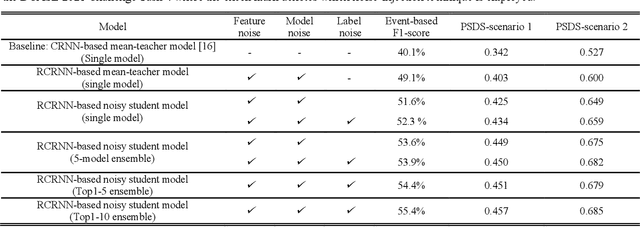
This report proposes a polyphonic sound event detection (SED) method for the DCASE 2021 Challenge Task 4. The proposed SED model consists of two stages: a mean-teacher model for providing target labels regarding weakly labeled or unlabeled data and a self-training-based noisy student model for predicting strong labels for sound events. The mean-teacher model, which is based on the residual convolutional recurrent neural network (RCRNN) for the teacher and student model, is first trained using all the training data from a weakly labeled dataset, an unlabeled dataset, and a strongly labeled synthetic dataset. Then, the trained mean-teacher model predicts the strong label to each of the weakly labeled and unlabeled datasets, which is brought to the noisy student model in the second stage of the proposed SED model. Here, the structure of the noisy student model is identical to the RCRNN-based student model of the mean-teacher model in the first stage. Then, it is self-trained by adding feature noises, such as time-frequency shift, mixup, SpecAugment, and dropout-based model noise. In addition, a semi-supervised loss function is applied to train the noisy student model, which acts as label noise injection. The performance of the proposed SED model is evaluated on the validation set of the DCASE 2021 Challenge Task 4, and then, several ensemble models that combine five-fold validation models with different hyperparameters of the semi-supervised loss function are finally selected as our final models.
IGrow: A Smart Agriculture Solution to Autonomous Greenhouse Control
Jul 06, 2021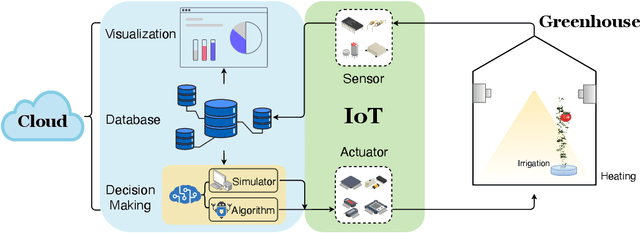
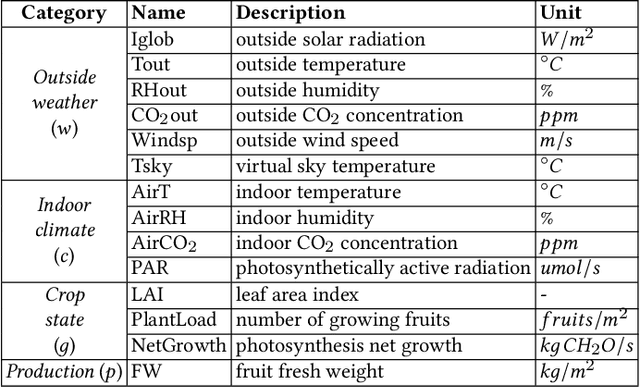
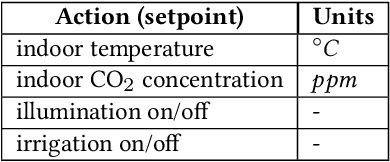
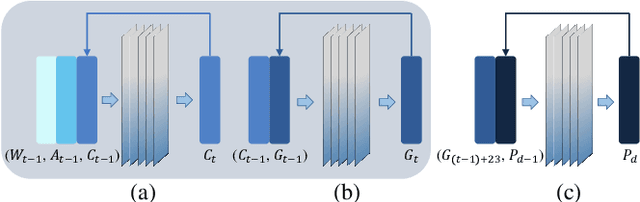
Agriculture is the foundation of human civilization. However, the rapid increase and aging of the global population pose challenges on this cornerstone by demanding more healthy and fresh food. Internet of Things (IoT) technology makes modern autonomous greenhouse a viable and reliable engine of food production. However, the educated and skilled labor capable of overseeing high-tech greenhouses is scarce. Artificial intelligence (AI) and cloud computing technologies are promising solutions for precision control and high-efficiency production in such controlled environments. In this paper, we propose a smart agriculture solution, namely iGrow: (1) we use IoT and cloud computing technologies to measure, collect, and manage growing data, to support iteration of our decision-making AI module, which consists of an incremental model and an optimization algorithm; (2) we propose a three-stage incremental model based on accumulating data, enabling growers/central computers to schedule control strategies conveniently and at low cost; (3) we propose a model-based iterative optimization algorithm, which can dynamically optimize the greenhouse control strategy in real-time production. In the simulated experiment, evaluation results show the accuracy of our incremental model is comparable to an advanced tomato simulator, while our optimization algorithms can beat the champion of the 2nd Autonomous Greenhouse Challenge. Compelling results from the A/B test in real greenhouses demonstrate that our solution significantly increases production (commercially sellable fruits) (+ 10.15%) and net profit (+ 87.07%) with statistical significance compared to planting experts.
STRESS: Super-Resolution for Dynamic Fetal MRI using Self-Supervised Learning
Jun 30, 2021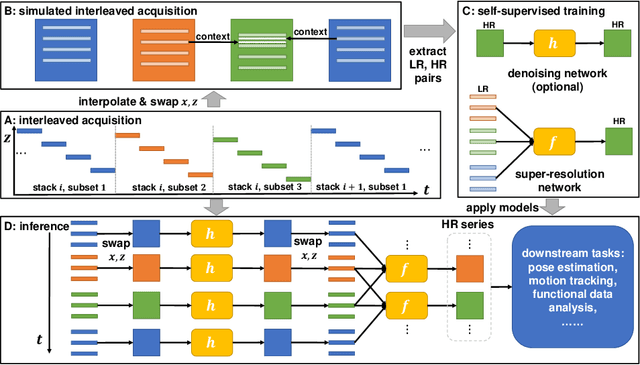
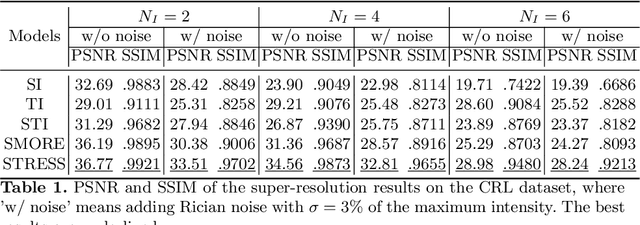
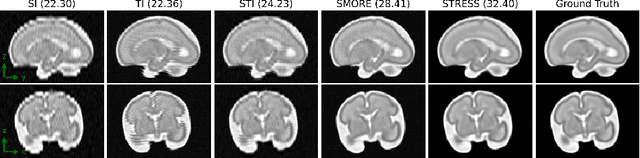

Fetal motion is unpredictable and rapid on the scale of conventional MR scan times. Therefore, dynamic fetal MRI, which aims at capturing fetal motion and dynamics of fetal function, is limited to fast imaging techniques with compromises in image quality and resolution. Super-resolution for dynamic fetal MRI is still a challenge, especially when multi-oriented stacks of image slices for oversampling are not available and high temporal resolution for recording the dynamics of the fetus or placenta is desired. Further, fetal motion makes it difficult to acquire high-resolution images for supervised learning methods. To address this problem, in this work, we propose STRESS (Spatio-Temporal Resolution Enhancement with Simulated Scans), a self-supervised super-resolution framework for dynamic fetal MRI with interleaved slice acquisitions. Our proposed method simulates an interleaved slice acquisition along the high-resolution axis on the originally acquired data to generate pairs of low- and high-resolution images. Then, it trains a super-resolution network by exploiting both spatial and temporal correlations in the MR time series, which is used to enhance the resolution of the original data. Evaluations on both simulated and in utero data show that our proposed method outperforms other self-supervised super-resolution methods and improves image quality, which is beneficial to other downstream tasks and evaluations.
Communication-Efficient Split Learning Based on Analog Communication and Over the Air Aggregation
Jun 02, 2021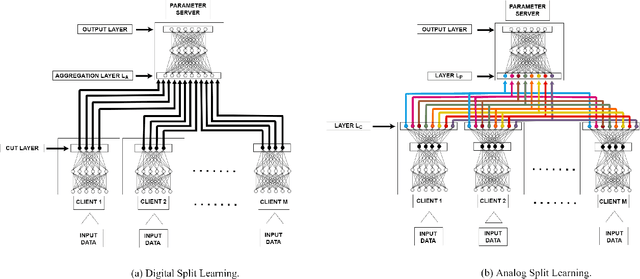
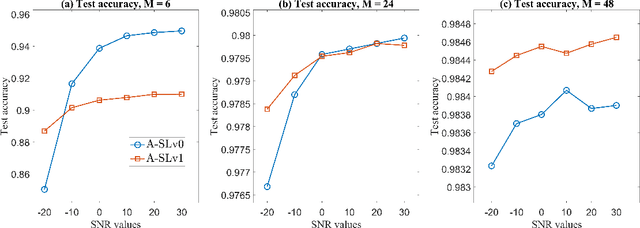
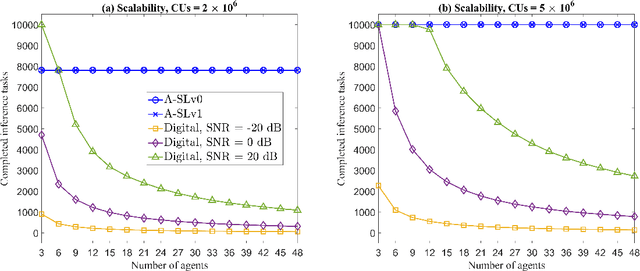
Split-learning (SL) has recently gained popularity due to its inherent privacy-preserving capabilities and ability to enable collaborative inference for devices with limited computational power. Standard SL algorithms assume an ideal underlying digital communication system and ignore the problem of scarce communication bandwidth. However, for a large number of agents, limited bandwidth resources, and time-varying communication channels, the communication bandwidth can become the bottleneck. To address this challenge, in this work, we propose a novel SL framework to solve the remote inference problem that introduces an additional layer at the agent side and constrains the choices of the weights and the biases to ensure over the air aggregation. Hence, the proposed approach maintains constant communication cost with respect to the number of agents enabling remote inference under limited bandwidth. Numerical results show that our proposed algorithm significantly outperforms the digital implementation in terms of communication-efficiency, especially as the number of agents grows large.
Semi supervised segmentation and graph-based tracking of 3D nuclei in time-lapse microscopy
Oct 26, 2020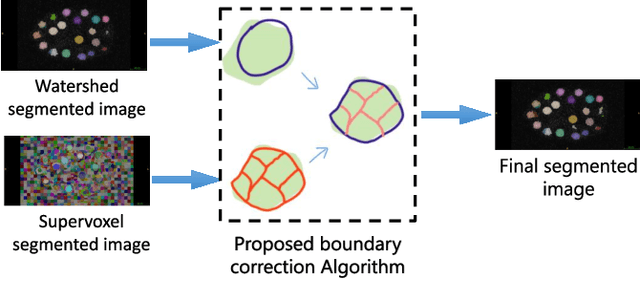


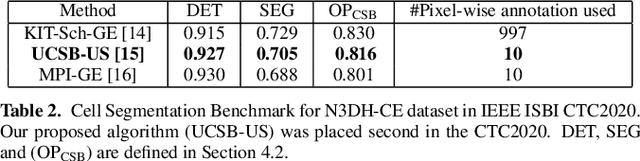
We propose a novel weakly supervised method to improve the boundary of the 3D segmented nuclei utilizing an over-segmented image. This is motivated by the observation that current state-of-the-art deep learning methods do not result in accurate boundaries when the training data is weakly annotated. Towards this, a 3D U-Net is trained to get the centroid of the nuclei and integrated with a simple linear iterative clustering (SLIC) supervoxel algorithm that provides better adherence to cluster boundaries. To track these segmented nuclei, our algorithm utilizes the relative nuclei location depicting the processes of nuclei division and apoptosis. The proposed algorithmic pipeline achieves better segmentation performance compared to the state-of-the-art method in Cell Tracking Challenge (CTC) 2019 and comparable performance to state-of-the-art methods in IEEE ISBI CTC2020 while utilizing very few pixel-wise annotated data. Detailed experimental results are provided, and the source code is available on GitHub.
TeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation
Mar 31, 2021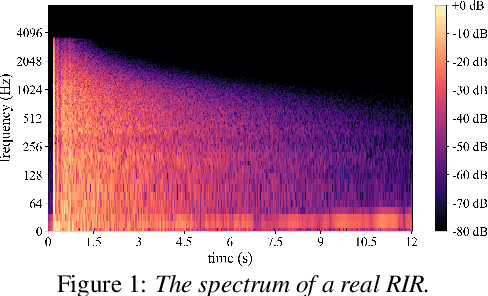
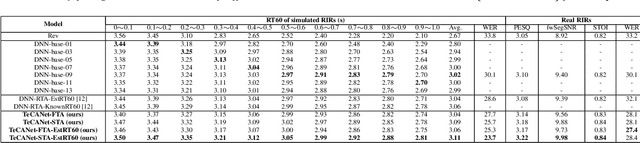
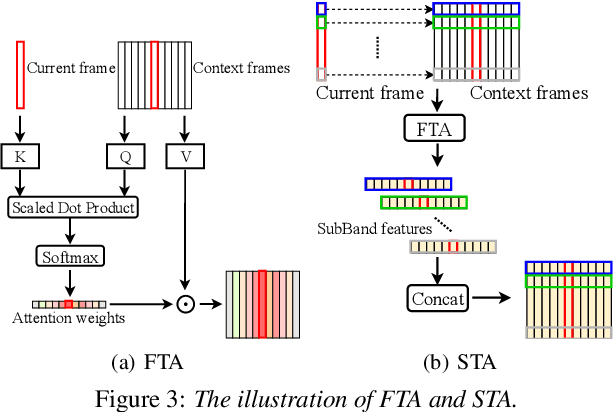
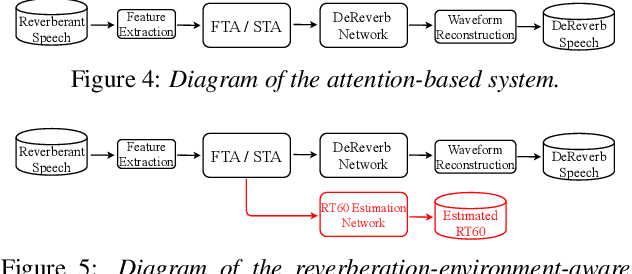
In this paper, we exploit the effective way to leverage contextual information to improve the speech dereverberation performance in real-world reverberant environments. We propose a temporal-contextual attention approach on the deep neural network (DNN) for environment-aware speech dereverberation, which can adaptively attend to the contextual information. More specifically, a FullBand based Temporal Attention approach (FTA) is proposed, which models the correlations between the fullband information of the context frames. In addition, considering the difference between the attenuation of high frequency bands and low frequency bands (high frequency bands attenuate faster than low frequency bands) in the room impulse response (RIR), we also propose a SubBand based Temporal Attention approach (STA). In order to guide the network to be more aware of the reverberant environments, we jointly optimize the dereverberation network and the reverberation time (RT60) estimator in a multi-task manner. Our experimental results indicate that the proposed method outperforms our previously proposed reverberation-time-aware DNN and the learned attention weights are fully physical consistent. We also report a preliminary yet promising dereverberation and recognition experiment on real test data.
Auto-COP: Adaptation Generation in Context-Oriented Programming using Reinforcement Learning Options
Mar 11, 2021
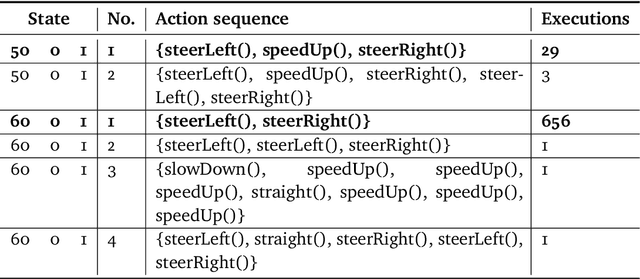
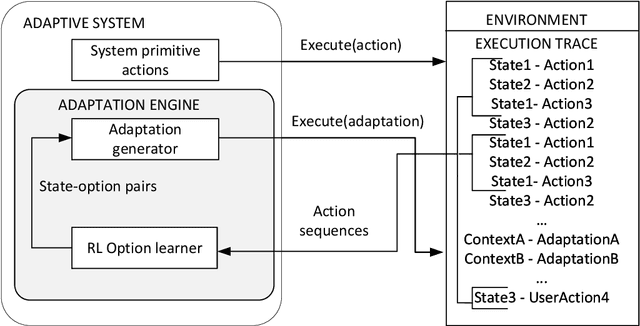
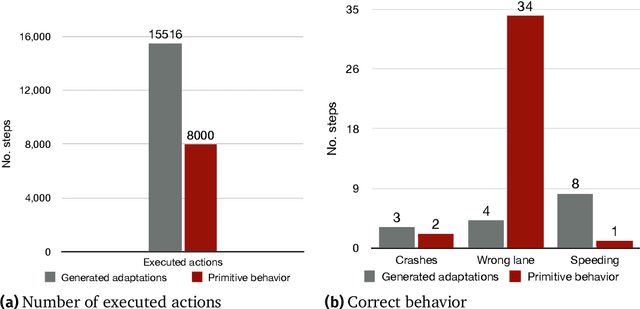
Self-adaptive software systems continuously adapt in response to internal and external changes in their execution environment, captured as contexts. The COP paradigm posits a technique for the development of self-adaptive systems, capturing their main characteristics with specialized programming language constructs. COP adaptations are specified as independent modules composed in and out of the base system as contexts are activated and deactivated in response to sensed circumstances from the surrounding environment. However, the definition of adaptations, their contexts and associated specialized behavior, need to be specified at design time. In complex CPS this is intractable due to new unpredicted operating conditions. We propose Auto-COP, a new technique to enable generation of adaptations at run time. Auto-COP uses RL options to build action sequences, based on the previous instances of the system execution. Options are explored in interaction with the environment, and the most suitable options for each context are used to generate adaptations exploiting COP. To validate Auto-COP, we present two case studies exhibiting different system characteristics and application domains: a driving assistant and a robot delivery system. We present examples of Auto-COP code generated at run time, to illustrate the types of circumstances (contexts) requiring adaptation, and the corresponding generated adaptations for each context. We confirm that the generated adaptations exhibit correct system behavior measured by domain-specific performance metrics, while reducing the number of required execution/actuation steps by a factor of two showing that the adaptations are regularly selected by the running system as adaptive behavior is more appropriate than the execution of primitive actions.