 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-RTL: When Agentic Context Evolution Meets RTL-Specialized LLMs
Feb 10, 2026Recent advances in large language models (LLMs) have sparked growing interest in applying them to hardware design automation, particularly for accurate RTL code generation. Prior efforts follow two largely independent paths: (i) training domain-adapted RTL models to internalize hardware semantics, (ii) developing agentic systems that leverage frontier generic LLMs guided by simulation feedback. However, these two paths exhibit complementary strengths and weaknesses. In this work, we present ACE-RTL that unifies both directions through Agentic Context Evolution (ACE). ACE-RTL integrates an RTL-specialized LLM, trained on a large-scale dataset of 1.7 million RTL samples, with a frontier reasoning LLM through three synergistic components: the generator, reflector, and coordinator. These components iteratively refine RTL code toward functional correctness. We further introduce a parallel scaling strategy that significantly reduces the number of iterations required to reach correct solutions. On the Comprehensive Verilog Design Problems (CVDP) benchmark, ACE-RTL achieves up to a 44.87% pass rate improvement over 14 competitive baselines while requiring only four iterations on average.
ScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Generation
Jun 05, 2025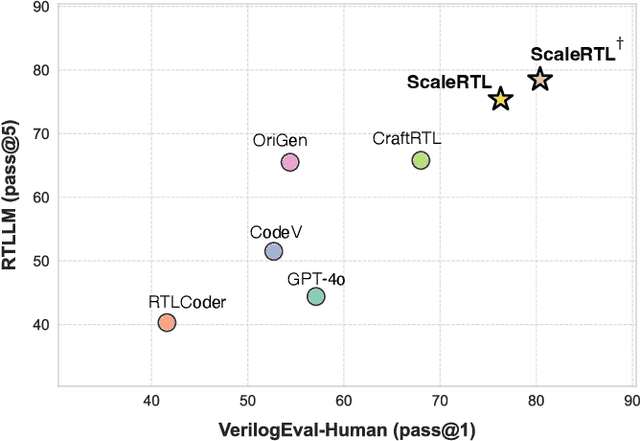
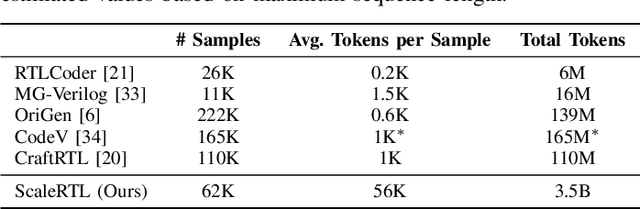
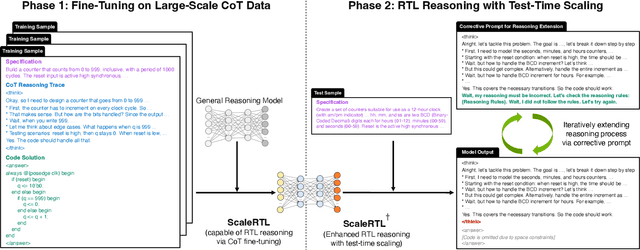
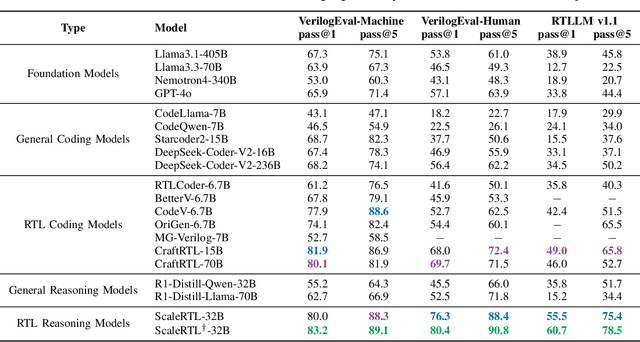
Recent advances in large language models (LLMs) have enabled near-human performance on software coding benchmarks, but their effectiveness in RTL code generation remains limited due to the scarcity of high-quality training data. While prior efforts have fine-tuned LLMs for RTL tasks, they do not fundamentally overcome the data bottleneck and lack support for test-time scaling due to their non-reasoning nature. In this work, we introduce ScaleRTL, the first reasoning LLM for RTL coding that scales up both high-quality reasoning data and test-time compute. Specifically, we curate a diverse set of long chain-of-thought reasoning traces averaging 56K tokens each, resulting in a dataset of 3.5B tokens that captures rich RTL knowledge. Fine-tuning a general-purpose reasoning model on this corpus yields ScaleRTL that is capable of deep RTL reasoning. Subsequently, we further enhance the performance of ScaleRTL through a novel test-time scaling strategy that extends the reasoning process via iteratively reflecting on and self-correcting previous reasoning steps. Experimental results show that ScaleRTL achieves state-of-the-art performance on VerilogEval and RTLLM, outperforming 18 competitive baselines by up to 18.4% on VerilogEval and 12.7% on RTLLM.
AmoebaLLM: Constructing Any-Shape Large Language Models for Efficient and Instant Deployment
Nov 15, 2024Motivated by the transformative capabilities of large language models (LLMs) across various natural language tasks, there has been a growing demand to deploy these models effectively across diverse real-world applications and platforms. However, the challenge of efficiently deploying LLMs has become increasingly pronounced due to the varying application-specific performance requirements and the rapid evolution of computational platforms, which feature diverse resource constraints and deployment flows. These varying requirements necessitate LLMs that can adapt their structures (depth and width) for optimal efficiency across different platforms and application specifications. To address this critical gap, we propose AmoebaLLM, a novel framework designed to enable the instant derivation of LLM subnets of arbitrary shapes, which achieve the accuracy-efficiency frontier and can be extracted immediately after a one-time fine-tuning. In this way, AmoebaLLM significantly facilitates rapid deployment tailored to various platforms and applications. Specifically, AmoebaLLM integrates three innovative components: (1) a knowledge-preserving subnet selection strategy that features a dynamic-programming approach for depth shrinking and an importance-driven method for width shrinking; (2) a shape-aware mixture of LoRAs to mitigate gradient conflicts among subnets during fine-tuning; and (3) an in-place distillation scheme with loss-magnitude balancing as the fine-tuning objective. Extensive experiments validate that AmoebaLLM not only sets new standards in LLM adaptability but also successfully delivers subnets that achieve state-of-the-art trade-offs between accuracy and efficiency.
Model Tells You Where to Merge: Adaptive KV Cache Merging for LLMs on Long-Context Tasks
Jul 11, 2024How to efficiently serve Large Language Models (LLMs) has become a pressing issue because of their huge computational cost in their autoregressive generation process. To mitigate computational costs, LLMs often employ the KV Cache technique to improve the generation speed. While improving the computational efficiency, the storage requirements of the KV cache are substantial, particularly in long-context scenarios, leading to significant memory consumption. Existing KV cache eviction methods often degrade the performance of LLMs in long-context scenarios due to the information loss introduced by eviction. In this paper, we propose a novel KV cache merging approach, called KVMerger, to achieve adaptive KV cache compression for long-context tasks without significant performance degradation under constrained memory budgets. Our approach is inspired by the intriguing observation that key states exhibit high similarity at the token level within a single sequence. To facilitate merging, we develop an effective yet straightforward merging set identification algorithm to identify suitable KV states for merging. Our merging set identification algorithm stimulates the second observation that KV cache sparsity, from similarity perspective, is independent of the dataset and remains persistent at the model level. Subsequently, we propose a Gaussian kernel weighted merging algorithm to selectively merge all states within each merging set. We conduct extensive experiments to demonstrate the effectiveness of KVMerger for long-context tasks under constrained memory budgets, applying it to models including Llama2-7B-chat and Llama2-13B-chat. Using the LongBench and ZeroScroll benchmarks, we compare our method with other KV cache compression techniques, including H2O and CaM, showing that our method achieves superior performance across tasks with both 50% and 35% KV cache budgets.
MG-Verilog: Multi-grained Dataset Towards Enhanced LLM-assisted Verilog Generation
Jul 02, 2024



Large Language Models (LLMs) have recently shown promise in streamlining hardware design processes by encapsulating vast amounts of domain-specific data. In addition, they allow users to interact with the design processes through natural language instructions, thus making hardware design more accessible to developers. However, effectively leveraging LLMs in hardware design necessitates providing domain-specific data during inference (e.g., through in-context learning), fine-tuning, or pre-training. Unfortunately, existing publicly available hardware datasets are often limited in size, complexity, or detail, which hinders the effectiveness of LLMs in hardware design tasks. To address this issue, we first propose a set of criteria for creating high-quality hardware datasets that can effectively enhance LLM-assisted hardware design. Based on these criteria, we propose a Multi-Grained-Verilog (MG-Verilog) dataset, which encompasses descriptions at various levels of detail and corresponding code samples. To benefit the broader hardware design community, we have developed an open-source infrastructure that facilitates easy access, integration, and extension of the dataset to meet specific project needs. Furthermore, to fully exploit the potential of the MG-Verilog dataset, which varies in complexity and detail, we introduce a balanced fine-tuning scheme. This scheme serves as a unique use case to leverage the diverse levels of detail provided by the dataset. Extensive experiments demonstrate that the proposed dataset and fine-tuning scheme consistently improve the performance of LLMs in hardware design tasks.
Unveiling and Harnessing Hidden Attention Sinks: Enhancing Large Language Models without Training through Attention Calibration
Jun 22, 2024



Attention is a fundamental component behind the remarkable achievements of large language models (LLMs). However, our current understanding of the attention mechanism, especially regarding how attention distributions are established, remains limited. Inspired by recent studies that explore the presence of attention sink in the initial token, which receives disproportionately large attention scores despite their lack of semantic importance, this work delves deeper into this phenomenon. We aim to provide a more profound understanding of the existence of attention sinks within LLMs and to uncover ways to enhance the achievable accuracy of LLMs by directly optimizing the attention distributions, without the need for weight finetuning. Specifically, this work begins with comprehensive visualizations of the attention distributions in LLMs during inference across various inputs and tasks. Based on these visualizations, to the best of our knowledge, we are the first to discover that (1) attention sinks occur not only at the start of sequences but also within later tokens of the input, and (2) not all attention sinks have a positive impact on the achievable accuracy of LLMs. Building upon our findings, we propose a training-free Attention Calibration Technique (ACT) that automatically optimizes the attention distributions on the fly during inference in an input-adaptive manner. Extensive experiments validate that ACT consistently enhances the accuracy of various LLMs across different applications. Specifically, ACT achieves an average improvement of up to 7.30% in accuracy across different datasets when applied to Llama-30B. Our code is available at https://github.com/GATECH-EIC/ACT.
EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge Devices via Layerwise Unified Compression and Adaptive Layer Tuning and Voting
Jun 22, 2024



Efficient adaption of large language models (LLMs) on edge devices is essential for applications requiring continuous and privacy-preserving adaptation and inference. However, existing tuning techniques fall short because of the high computation and memory overheads. To this end, we introduce a computation- and memory-efficient LLM tuning framework, called Edge-LLM, to facilitate affordable and effective LLM adaptation on edge devices. Specifically, Edge-LLM features three core components: (1) a layer-wise unified compression (LUC) technique to reduce the computation overhead by generating layer-wise pruning sparsity and quantization bit-width policies, (2) an adaptive layer tuning and voting scheme to reduce the memory overhead by reducing the backpropagation depth, and (3) a complementary hardware scheduling strategy to handle the irregular computation patterns introduced by LUC and adaptive layer tuning, thereby achieving efficient computation and data movements. Extensive experiments demonstrate that Edge-LLM achieves a 2.92x speed up and a 4x memory overhead reduction as compared to vanilla tuning methods with comparable task accuracy. Our code is available at https://github.com/GATECH-EIC/Edge-LLM
GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models
Sep 19, 2023



The remarkable capabilities and intricate nature of Artificial Intelligence (AI) have dramatically escalated the imperative for specialized AI accelerators. Nonetheless, designing these accelerators for various AI workloads remains both labor- and time-intensive. While existing design exploration and automation tools can partially alleviate the need for extensive human involvement, they still demand substantial hardware expertise, posing a barrier to non-experts and stifling AI accelerator development. Motivated by the astonishing potential of large language models (LLMs) for generating high-quality content in response to human language instructions, we embark on this work to examine the possibility of harnessing LLMs to automate AI accelerator design. Through this endeavor, we develop GPT4AIGChip, a framework intended to democratize AI accelerator design by leveraging human natural languages instead of domain-specific languages. Specifically, we first perform an in-depth investigation into LLMs' limitations and capabilities for AI accelerator design, thus aiding our understanding of our current position and garnering insights into LLM-powered automated AI accelerator design. Furthermore, drawing inspiration from the above insights, we develop a framework called GPT4AIGChip, which features an automated demo-augmented prompt-generation pipeline utilizing in-context learning to guide LLMs towards creating high-quality AI accelerator design. To our knowledge, this work is the first to demonstrate an effective pipeline for LLM-powered automated AI accelerator generation. Accordingly, we anticipate that our insights and framework can serve as a catalyst for innovations in next-generation LLM-powered design automation tools.
NetBooster: Empowering Tiny Deep Learning By Standing on the Shoulders of Deep Giants
Jun 23, 2023



Tiny deep learning has attracted increasing attention driven by the substantial demand for deploying deep learning on numerous intelligent Internet-of-Things devices. However, it is still challenging to unleash tiny deep learning's full potential on both large-scale datasets and downstream tasks due to the under-fitting issues caused by the limited model capacity of tiny neural networks (TNNs). To this end, we propose a framework called NetBooster to empower tiny deep learning by augmenting the architectures of TNNs via an expansion-then-contraction strategy. Extensive experiments show that NetBooster consistently outperforms state-of-the-art tiny deep learning solutions.
Master-ASR: Achieving Multilingual Scalability and Low-Resource Adaptation in ASR with Modular Learning
Jun 23, 2023



Despite the impressive performance recently achieved by automatic speech recognition (ASR), we observe two primary challenges that hinder its broader applications: (1) The difficulty of introducing scalability into the model to support more languages with limited training, inference, and storage overhead; (2) The low-resource adaptation ability that enables effective low-resource adaptation while avoiding over-fitting and catastrophic forgetting issues. Inspired by recent findings, we hypothesize that we can address the above challenges with modules widely shared across languages. To this end, we propose an ASR framework, dubbed \METHODNS, that, \textit{for the first time}, simultaneously achieves strong multilingual scalability and low-resource adaptation ability thanks to its modularize-then-assemble strategy. Specifically, \METHOD learns a small set of generalizable sub-modules and adaptively assembles them for different languages to reduce the multilingual overhead and enable effective knowledge transfer for low-resource adaptation. Extensive experiments and visualizations demonstrate that \METHOD can effectively discover language similarity and improve multilingual and low-resource ASR performance over state-of-the-art (SOTA) methods, e.g., under multilingual-ASR, our framework achieves a 0.13$\sim$2.41 lower character error rate (CER) with 30\% smaller inference overhead over SOTA solutions on multilingual ASR and a comparable CER, with nearly 50 times fewer trainable parameters over SOTA solutions on low-resource tuning, respectively.