 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Natural Language Inference Using PHL Triplet Generation
Oct 16, 2021
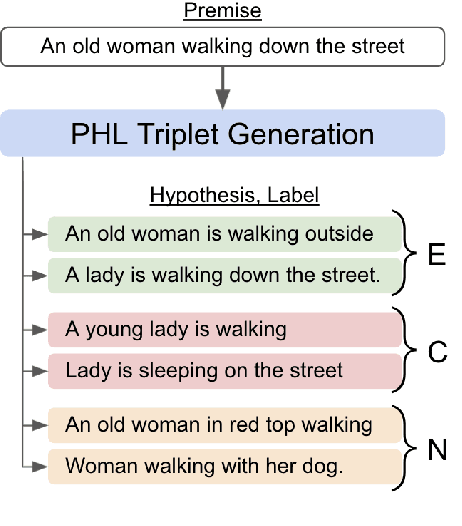

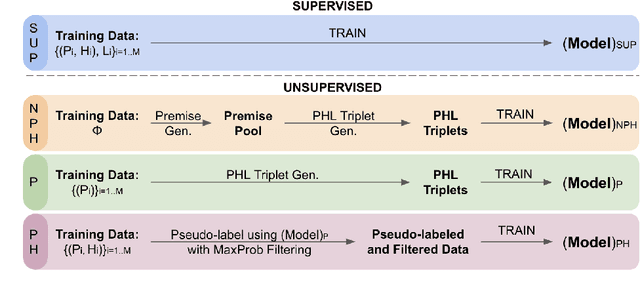
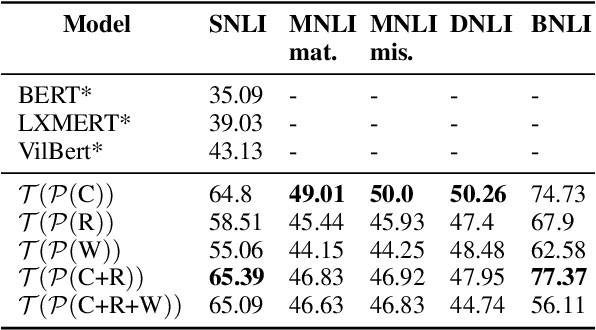
Transformer-based models have achieved impressive performance on various Natural Language Inference (NLI) benchmarks, when trained on respective training datasets. However, in certain cases, training samples may not be available or collecting them could be time-consuming and resource-intensive. In this work, we address this challenge and present an explorative study on unsupervised NLI, a paradigm in which no human-annotated training samples are available. We investigate NLI under three challenging settings: PH, P, and NPH that differ in the extent of unlabeled data available for learning. As a solution, we propose a procedural data generation approach that leverages a set of sentence transformations to collect PHL (Premise, Hypothesis, Label) triplets for training NLI models, bypassing the need for human-annotated training datasets. Comprehensive experiments show that this approach results in accuracies of 66.75%, 65.9%, 65.39% in PH, P, NPH settings respectively, outperforming all existing baselines. Furthermore, fine-tuning our models with as little as ~0.1% of the training dataset (500 samples) leads to 12.2% higher accuracy than the model trained from scratch on the same 500 instances.
Evaluating Music Recommendations with Binary Feedback for Multiple Stakeholders
Sep 16, 2021

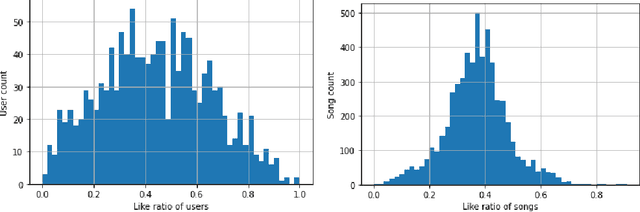
High quality user feedback data is essential to training and evaluating a successful music recommendation system, particularly one that has to balance the needs of multiple stakeholders. Most existing music datasets suffer from noisy feedback and self-selection biases inherent in the data collected by music platforms. Using the Piki Music dataset of 500k ratings collected over a two-year time period, we evaluate the performance of classic recommendation algorithms on three important stakeholders: consumers, well-known artists and lesser-known artists. We show that a matrix factorization algorithm trained on both likes and dislikes performs significantly better compared to one trained only on likes for all three stakeholders.
What is A Wireless UAV? A Design Blueprint for 6G Flying Wireless Nodes
Oct 06, 2021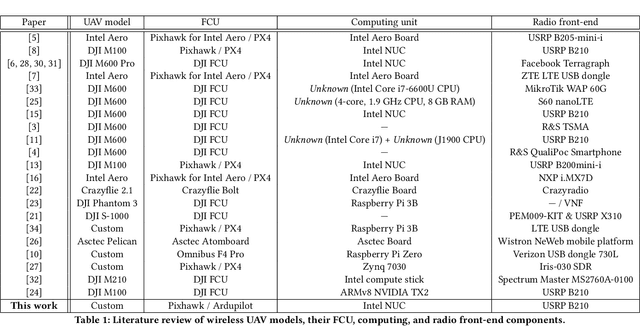
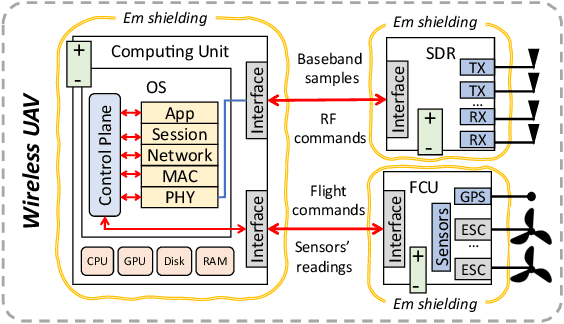
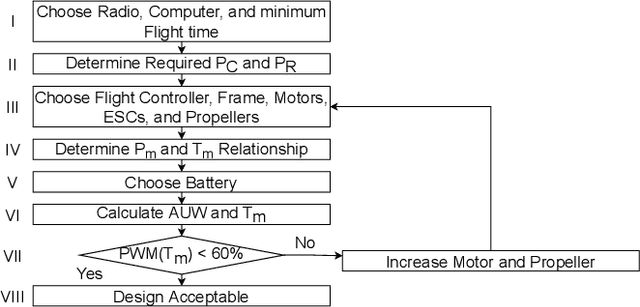
Wireless Unmanned Aerial Vehicles (UAVs) were introduced in the world of 4th generation networks (4G) as cellular users, and have attracted the interest of the wireless community ever since. In~5G, UAVs operate also as flying Base Stations providing service to ground users. They can also implement independent off-the-grid UAV networks. In~6G networks, wireless UAVs will connect ground users to in-orbit wireless infrastructure. As the design and prototyping of wireless UAVs are on the rise, the time is ripe for introducing a more precise definition of what is a wireless UAV. In doing so, we revise the major design challenges in the prototyping of wireless UAVs for future 6G spectrum research. We then introduce a new wireless UAV prototype that addresses these challenges. The design of our wireless UAV prototype will be made public and freely available to other researchers.
Clustering of Pain Dynamics in Sickle Cell Disease from Sparse, Uneven Samples
Aug 31, 2021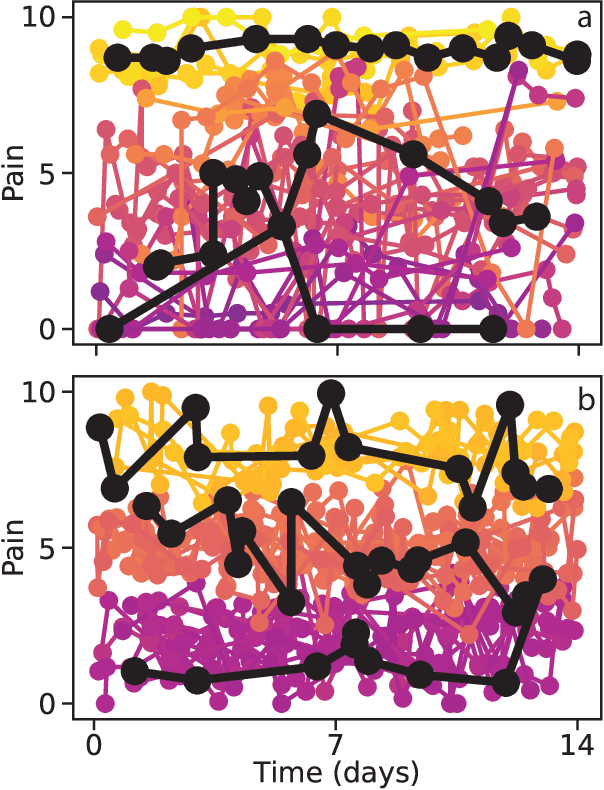
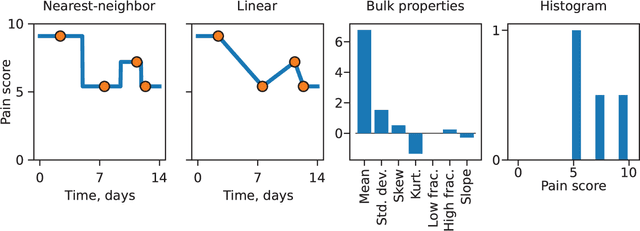
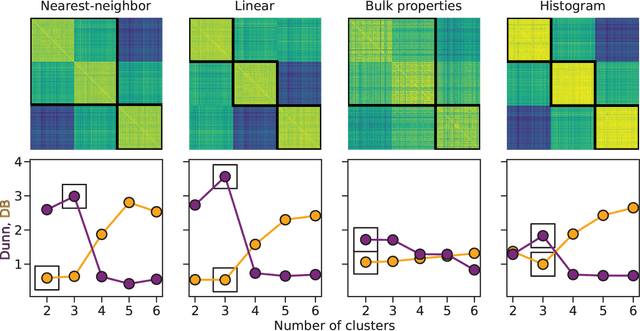
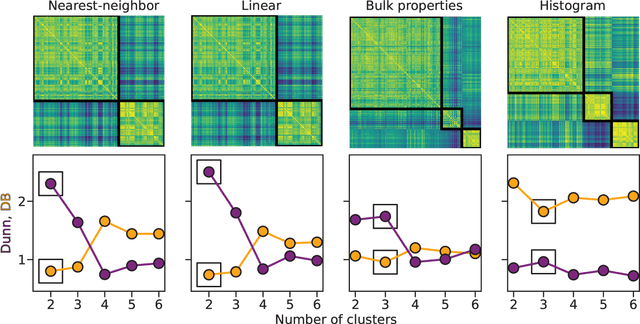
Irregularly sampled time series data are common in a variety of fields. Many typical methods for drawing insight from data fail in this case. Here we attempt to generalize methods for clustering trajectories to irregularly and sparsely sampled data. We first construct synthetic data sets, then propose and assess four methods of data alignment to allow for application of spectral clustering. We also repeat the same process for real data drawn from medical records of patients with sickle cell disease -- patients whose subjective experiences of pain were tracked for several months via a mobile app. We find that different methods for aligning irregularly sampled sparse data sets can lead to different optimal numbers of clusters, even for synthetic data with known properties. For the case of sickle cell disease, we find that three clusters is a reasonable choice, and these appear to correspond to (1) a low pain group with occasionally acute pain, (2) a group which experiences moderate mean pain that fluctuates often from low to high, and (3) a group that experiences persistent high levels of pain. Our results may help physicians and patients better understand and manage patients' pain levels over time, and we expect that the methods we develop will apply to a wide range of other data sources in medicine and beyond.
Efficient Context-Aware Network for Abdominal Multi-organ Segmentation
Oct 09, 2021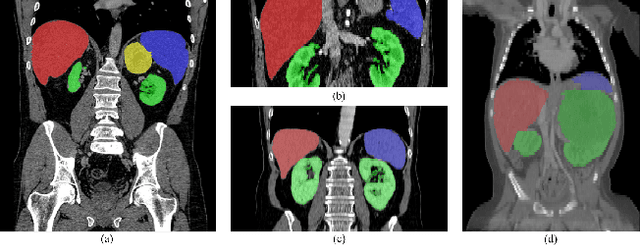
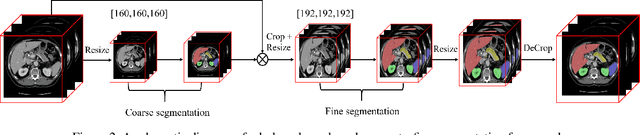
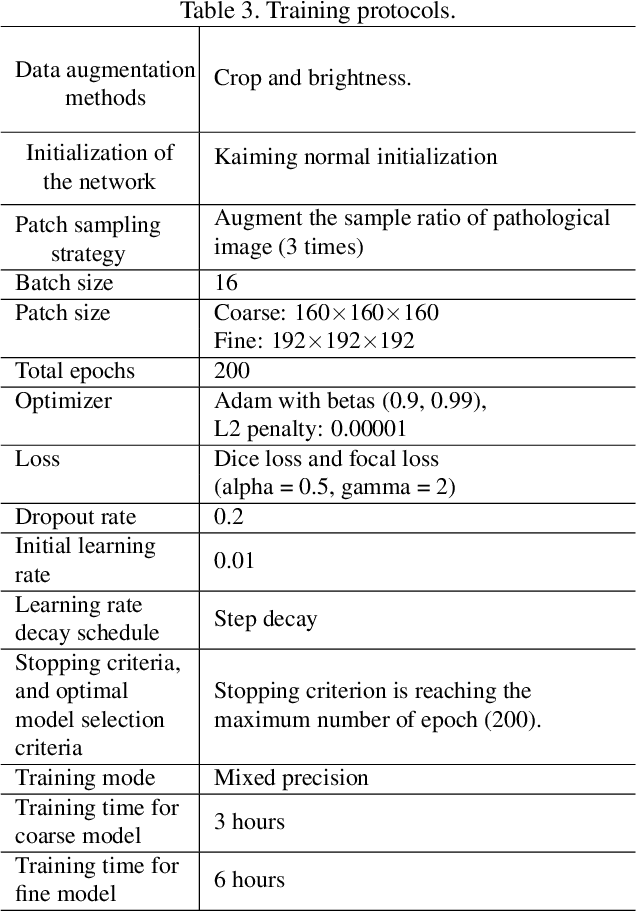
The contextual information, presented in abdominal CT scan, is relative consistent. In order to make full use of the overall 3D context, we develop a whole-volume-based coarse-to-fine framework for efficient and effective abdominal multi-organ segmentation. We propose a new efficientSegNet network, which is composed of encoder, decoder and context block. For the decoder module, anisotropic convolution with a k*k*1 intra-slice convolution and a 1*1*k inter-slice convolution, is designed to reduce the computation burden. For the context block, we propose strip pooling module to capture anisotropic and long-range contextual information, which exists in abdominal scene. Quantitative evaluation on the FLARE2021 validation cases, this method achieves the average dice similarity coefficient (DSC) of 0.895 and average normalized surface distance (NSD) of 0.775. The average running time is 9.8 s per case in inference phase, and maximum used GPU memory is 1017 MB.
Temporally Consistent Video Colorization with Deep Feature Propagation and Self-regularization Learning
Oct 09, 2021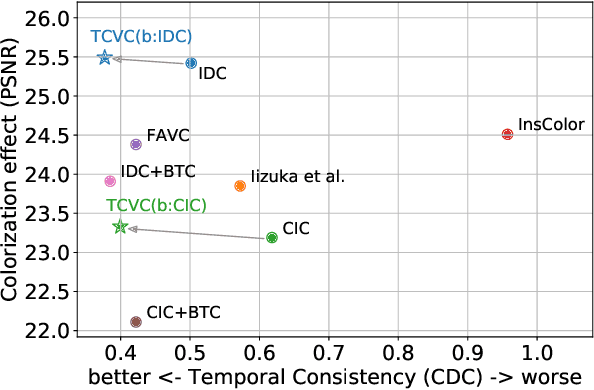
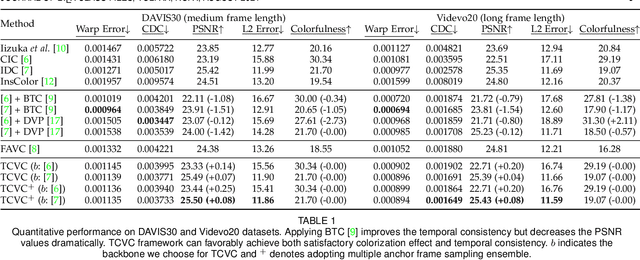

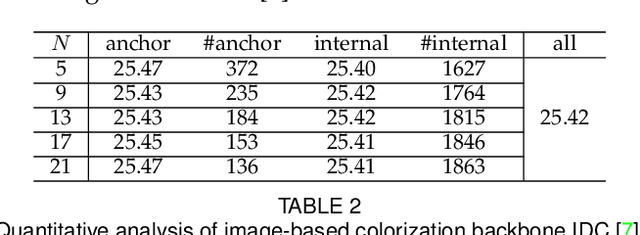
Video colorization is a challenging and highly ill-posed problem. Although recent years have witnessed remarkable progress in single image colorization, there is relatively less research effort on video colorization and existing methods always suffer from severe flickering artifacts (temporal inconsistency) or unsatisfying colorization performance. We address this problem from a new perspective, by jointly considering colorization and temporal consistency in a unified framework. Specifically, we propose a novel temporally consistent video colorization framework (TCVC). TCVC effectively propagates frame-level deep features in a bidirectional way to enhance the temporal consistency of colorization. Furthermore, TCVC introduces a self-regularization learning (SRL) scheme to minimize the prediction difference obtained with different time steps. SRL does not require any ground-truth color videos for training and can further improve temporal consistency. Experiments demonstrate that our method can not only obtain visually pleasing colorized video, but also achieve clearly better temporal consistency than state-of-the-art methods.
Stochastic Adversarial Koopman Model for Dynamical Systems
Sep 10, 2021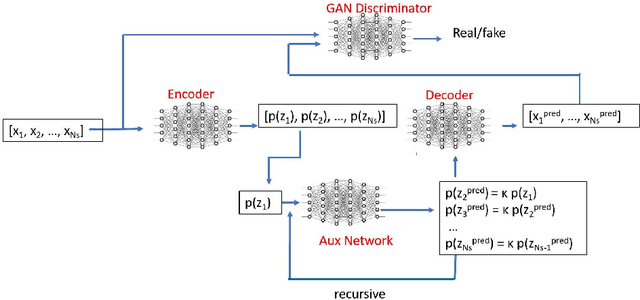
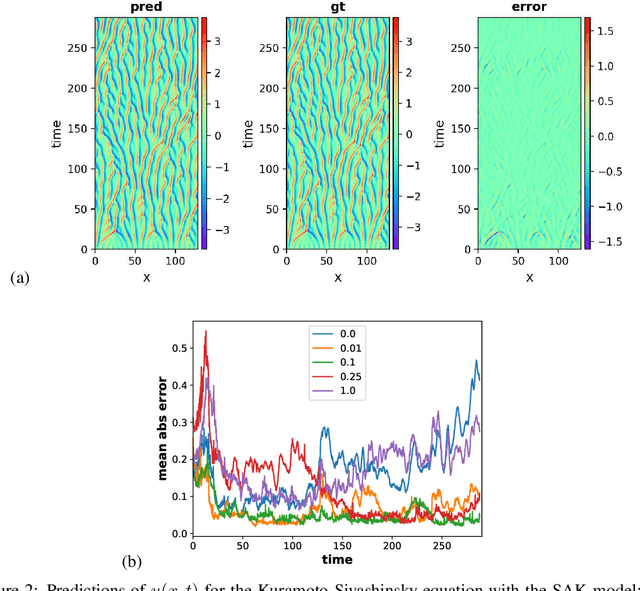
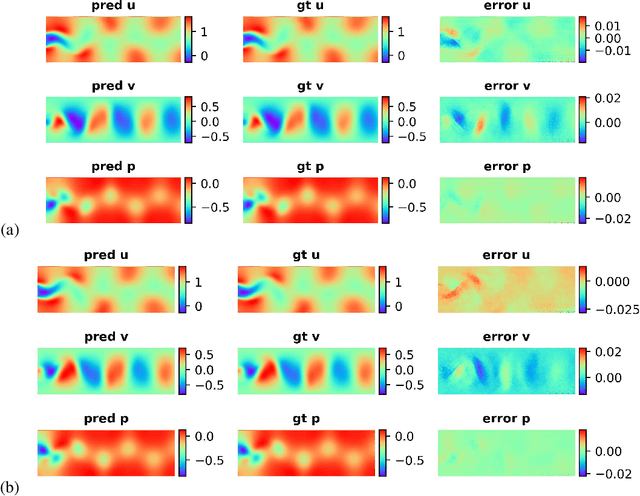

Dynamical systems are ubiquitous and are often modeled using a non-linear system of governing equations. Numerical solution procedures for many dynamical systems have existed for several decades, but can be slow due to high-dimensional state space of the dynamical system. Thus, deep learning-based reduced order models (ROMs) are of interest and one such family of algorithms along these lines are based on the Koopman theory. This paper extends a recently developed adversarial Koopman model (Balakrishnan \& Upadhyay, arXiv:2006.05547) to stochastic space, where the Koopman operator applies on the probability distribution of the latent encoding of an encoder. Specifically, the latent encoding of the system is modeled as a Gaussian, and is advanced in time by using an auxiliary neural network that outputs two Koopman matrices $K_{\mu}$ and $K_{\sigma}$. Adversarial and gradient losses are used and this is found to lower the prediction errors. A reduced Koopman formulation is also undertaken where the Koopman matrices are assumed to have a tridiagonal structure, and this yields predictions comparable to the baseline model with full Koopman matrices. The efficacy of the stochastic Koopman model is demonstrated on different test problems in chaos, fluid dynamics, combustion, and reaction-diffusion models. The proposed model is also applied in a setting where the Koopman matrices are conditioned on other input parameters for generalization and this is applied to simulate the state of a Lithium-ion battery in time. The Koopman models discussed in this study are very promising for the wide range of problems considered.
Efficient Variational Graph Autoencoders for Unsupervised Cross-domain Prerequisite Chains
Oct 06, 2021
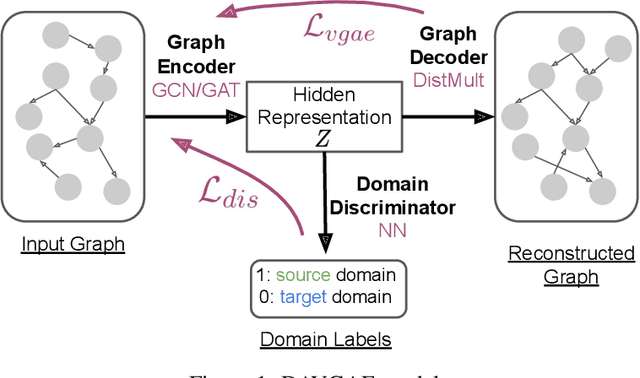
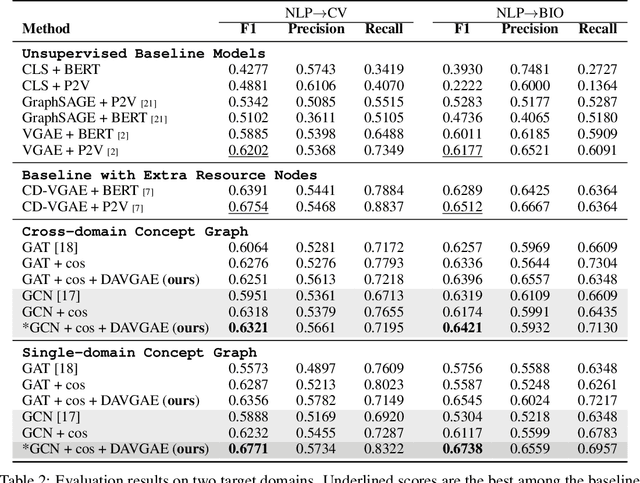
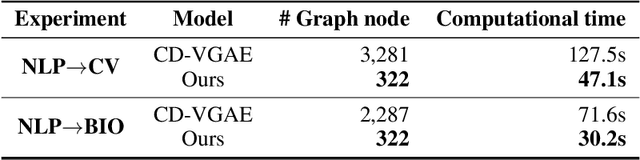
Prerequisite chain learning helps people acquire new knowledge efficiently. While people may quickly determine learning paths over concepts in a domain, finding such paths in other domains can be challenging. We introduce Domain-Adversarial Variational Graph Autoencoders (DAVGAE) to solve this cross-domain prerequisite chain learning task efficiently. Our novel model consists of a variational graph autoencoder (VGAE) and a domain discriminator. The VGAE is trained to predict concept relations through link prediction, while the domain discriminator takes both source and target domain data as input and is trained to predict domain labels. Most importantly, this method only needs simple homogeneous graphs as input, compared with the current state-of-the-art model. We evaluate our model on the LectureBankCD dataset, and results show that our model outperforms recent graph-based benchmarks while using only 1/10 of graph scale and 1/3 computation time.
Self-learned Intelligence for Integrated Decision and Control of Automated Vehicles at Signalized Intersections
Nov 10, 2021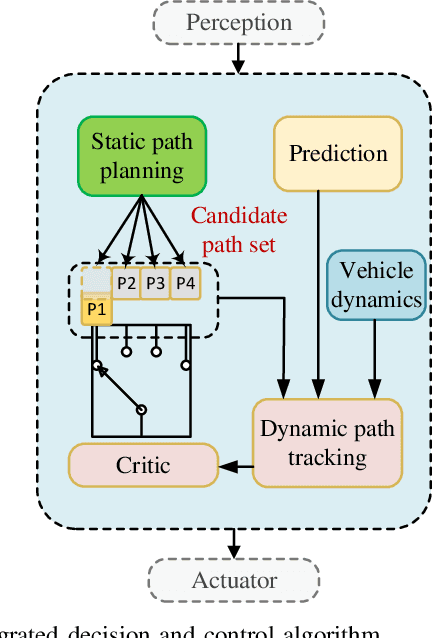
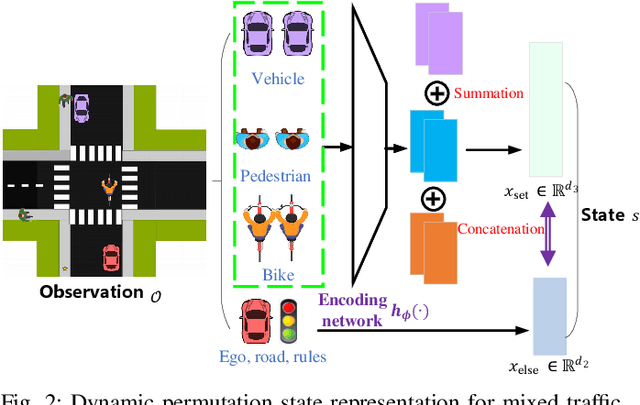
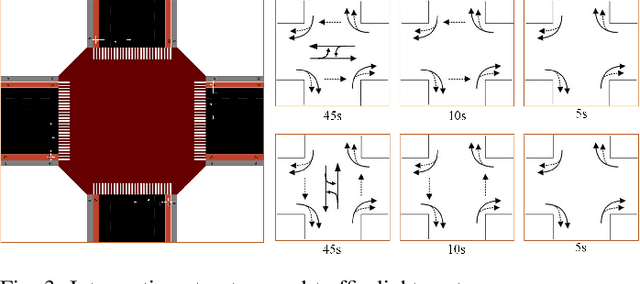
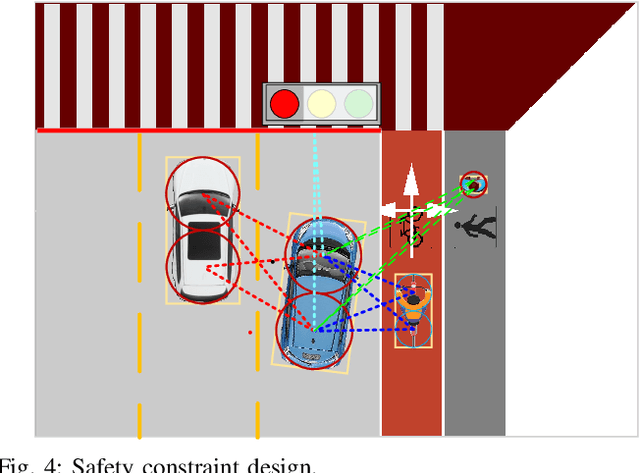
Intersection is one of the most complex and accident-prone urban scenarios for autonomous driving wherein making safe and computationally efficient decisions is non-trivial. Current research mainly focuses on the simplified traffic conditions while ignoring the existence of mixed traffic flows, i.e., vehicles, cyclists and pedestrians. For urban roads, different participants leads to a quite dynamic and complex interaction, posing great difficulty to learn an intelligent policy. This paper develops the dynamic permutation state representation in the framework of integrated decision and control (IDC) to handle signalized intersections with mixed traffic flows. Specially, this representation introduces an encoding function and summation operator to construct driving states from environmental observation, capable of dealing with different types and variant number of traffic participants. A constrained optimal control problem is built wherein the objective involves tracking performance and the constraints for different participants and signal lights are designed respectively to assure safety. We solve this problem by offline optimizing encoding function, value function and policy function, wherein the reasonable state representation will be given by the encoding function and then served as the input of policy and value function. An off-policy training is designed to reuse observations from driving environment and backpropagation through time is utilized to update the policy function and encoding function jointly. Verification result shows that the dynamic permutation state representation can enhance the driving performance of IDC, including comfort, decision compliance and safety with a large margin. The trained driving policy can realize efficient and smooth passing in the complex intersection, guaranteeing driving intelligence and safety simultaneously.
Prediction of properties of metal alloy materials based on machine learning
Sep 20, 2021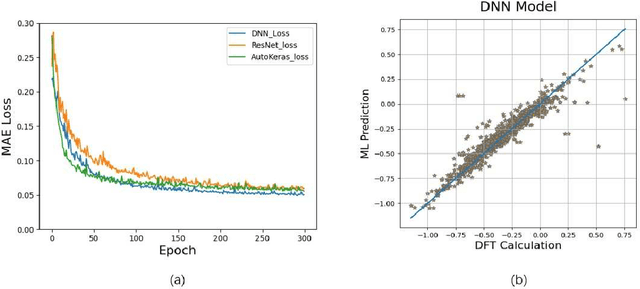
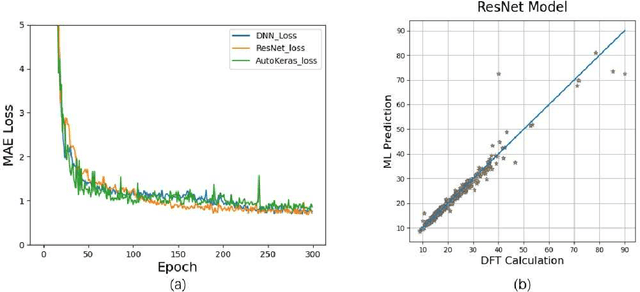
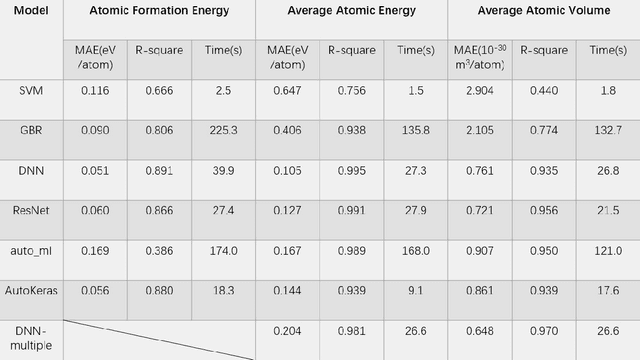
Density functional theory and its optimization algorithm are the main methods to calculate the properties in the field of materials. Although the calculation results are accurate, it costs a lot of time and money. In order to alleviate this problem, we intend to use machine learning to predict material properties. In this paper, we conduct experiments on atomic volume, atomic energy and atomic formation energy of metal alloys, using the open quantum material database. Through the traditional machine learning models, deep learning network and automated machine learning, we verify the feasibility of machine learning in material property prediction. The experimental results show that the machine learning can predict the material properties accurately.