 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX-MEM: Agentic Semi-Structured Memory with Temporal Reasoning for Long-Term Conversational AI
Apr 15, 2026Large language models still struggle with reliable long-term conversational memory: simply enlarging context windows or applying naive retrieval often introduces noise and destabilizes responses. We present APEX-MEM, a conversational memory system that combines three key innovations: (1) a property graph which uses domain-agnostic ontology to structure conversations as temporally grounded events in an entity-centric framework, (2) append-only storage that preserves the full temporal evolution of information, and (3) a multi-tool retrieval agent that understands and resolves conflicting or evolving information at query time, producing a compact and contextually relevant memory summary. This retrieval-time resolution preserves the full interaction history while suppressing irrelevant details. APEX-MEM achieves 88.88% accuracy on LOCOMO's Question Answering task and 86.2% on LongMemEval, outperforming state-of-the-art session-aware approaches and demonstrating that structured property graphs enable more temporally coherent long-term conversational reasoning.
APEX-EM: Non-Parametric Online Learning for Autonomous Agents via Structured Procedural-Episodic Experience Replay
Mar 31, 2026LLM-based autonomous agents lack persistent procedural memory: they re-derive solutions from scratch even when structurally identical tasks have been solved before. We present \textbf{APEX-EM}, a non-parametric online learning framework that accumulates, retrieves, and reuses structured procedural plans without modifying model weights. APEX-EM introduces: (1) a \emph{structured experience representation} encoding the full procedural-episodic trace of each execution -- planning steps, artifacts, iteration history with error analysis, and quality scores; (2) a \emph{Plan-Retrieve-Generate-Iterate-Ingest} (PRGII) workflow with Task Verifiers providing multi-dimensional reward signals; and (3) a \emph{dual-outcome Experience Memory} with hybrid retrieval combining semantic search, structural signature matching, and plan DAG traversal -- enabling cross-domain transfer between tasks sharing no lexical overlap but analogous operational structure. Successful experiences serve as positive in-context examples; failures as negative examples with structured error annotations. We evaluate on BigCodeBench~\cite{zhuo2025bigcodebench}, KGQAGen-10k~\cite{zhang2025kgqagen}, and Humanity's Last Exam~\cite{phan2025hle} using Claude Sonnet 4.5 and Opus 4.5. On KGQAGen-10k, APEX-EM achieves 89.6\% accuracy versus 41.3\% without memory (+48.3pp), surpassing the oracle-retrieval upper bound (84.9\%). On BigCodeBench, it reaches 83.3\% SR from a 53.9\% baseline (+29.4pp), exceeding MemRL's~\cite{memrl2025} +11.0pp gain under comparable frozen-backbone conditions (noting backbone differences controlled for in our analysis). On HLE, entity graph retrieval reaches 48.0\% from 25.2\% (+22.8pp). Ablations show component value is task-dependent: rich judge feedback is negligible for code generation but critical for structured queries (+10.3pp), while binary-signal iteration partially compensates for weaker feedback.
Towards LogiGLUE: A Brief Survey and A Benchmark for Analyzing Logical Reasoning Capabilities of Language Models
Oct 02, 2023



Logical reasoning is fundamental for humans yet presents a substantial challenge in the domain of Artificial Intelligence. Initially, researchers used Knowledge Representation and Reasoning (KR) systems that did not scale and required non trivial manual effort. Recently, the emergence of large language models (LLMs) has demonstrated the ability to overcome various limitations of formal Knowledge Representation (KR) systems. Consequently, there is a growing interest in using LLMs for logical reasoning via natural language. This work strives to understand the proficiency of LLMs in logical reasoning by offering a brief review of the latest progress in this area; with a focus on the logical reasoning datasets, tasks, and the methods adopted to utilize LLMs for reasoning. To offer a thorough analysis, we have compiled a benchmark titled LogiGLUE. This includes 24 varied datasets encompassing deductive, abductive, and inductive reasoning. We have standardized these datasets into Seq2Seq tasks to facilitate straightforward training and evaluation for future research. Utilizing LogiGLUE as a foundation, we have trained an instruction fine tuned language model, resulting in LogiT5. We study single task training, multi task training, and a chain of thought knowledge distillation fine tuning technique to assess the performance of model across the different logical reasoning categories. By this comprehensive process, we aim to shed light on the capabilities and potential pathways for enhancing logical reasoning proficiency in LLMs, paving the way for more advanced and nuanced developments in this critical field.
Lexi: Self-Supervised Learning of the UI Language
Jan 23, 2023



Humans can learn to operate the user interface (UI) of an application by reading an instruction manual or how-to guide. Along with text, these resources include visual content such as UI screenshots and images of application icons referenced in the text. We explore how to leverage this data to learn generic visio-linguistic representations of UI screens and their components. These representations are useful in many real applications, such as accessibility, voice navigation, and task automation. Prior UI representation models rely on UI metadata (UI trees and accessibility labels), which is often missing, incompletely defined, or not accessible. We avoid such a dependency, and propose Lexi, a pre-trained vision and language model designed to handle the unique features of UI screens, including their text richness and context sensitivity. To train Lexi we curate the UICaption dataset consisting of 114k UI images paired with descriptions of their functionality. We evaluate Lexi on four tasks: UI action entailment, instruction-based UI image retrieval, grounding referring expressions, and UI entity recognition.
Learning Action-Effect Dynamics for Hypothetical Vision-Language Reasoning Task
Dec 07, 2022



'Actions' play a vital role in how humans interact with the world. Thus, autonomous agents that would assist us in everyday tasks also require the capability to perform 'Reasoning about Actions & Change' (RAC). This has been an important research direction in Artificial Intelligence (AI) in general, but the study of RAC with visual and linguistic inputs is relatively recent. The CLEVR_HYP (Sampat et. al., 2021) is one such testbed for hypothetical vision-language reasoning with actions as the key focus. In this work, we propose a novel learning strategy that can improve reasoning about the effects of actions. We implement an encoder-decoder architecture to learn the representation of actions as vectors. We combine the aforementioned encoder-decoder architecture with existing modality parsers and a scene graph question answering model to evaluate our proposed system on the CLEVR_HYP dataset. We conduct thorough experiments to demonstrate the effectiveness of our proposed approach and discuss its advantages over previous baselines in terms of performance, data efficiency, and generalization capability.
Learning Action-Effect Dynamics from Pairs of Scene-graphs
Dec 07, 2022



'Actions' play a vital role in how humans interact with the world. Thus, autonomous agents that would assist us in everyday tasks also require the capability to perform 'Reasoning about Actions & Change' (RAC). Recently, there has been growing interest in the study of RAC with visual and linguistic inputs. Graphs are often used to represent semantic structure of the visual content (i.e. objects, their attributes and relationships among objects), commonly referred to as scene-graphs. In this work, we propose a novel method that leverages scene-graph representation of images to reason about the effects of actions described in natural language. We experiment with existing CLEVR_HYP (Sampat et. al, 2021) dataset and show that our proposed approach is effective in terms of performance, data efficiency, and generalization capability compared to existing models.
To Find Waldo You Need Contextual Cues: Debiasing Who's Waldo
Mar 30, 2022
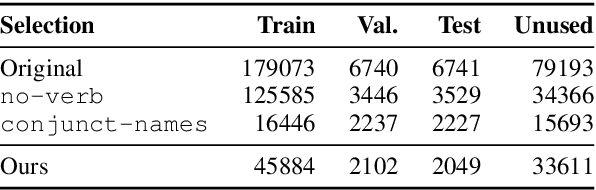
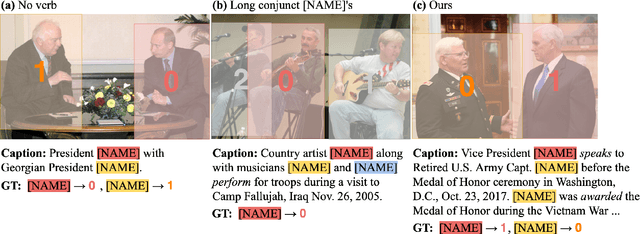
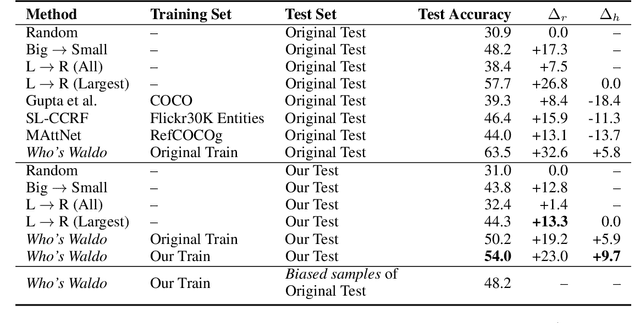
We present a debiased dataset for the Person-centric Visual Grounding (PCVG) task first proposed by Cui et al. (2021) in the Who's Waldo dataset. Given an image and a caption, PCVG requires pairing up a person's name mentioned in a caption with a bounding box that points to the person in the image. We find that the original Who's Waldo dataset compiled for this task contains a large number of biased samples that are solvable simply by heuristic methods; for instance, in many cases the first name in the sentence corresponds to the largest bounding box, or the sequence of names in the sentence corresponds to an exact left-to-right order in the image. Naturally, models trained on these biased data lead to over-estimation of performance on the benchmark. To enforce models being correct for the correct reasons, we design automated tools to filter and debias the original dataset by ruling out all examples of insufficient context, such as those with no verb or with a long chain of conjunct names in their captions. Our experiments show that our new sub-sampled dataset contains less bias with much lowered heuristic performances and widened gaps between heuristic and supervised methods. We also demonstrate the same benchmark model trained on our debiased training set outperforms that trained on the original biased (and larger) training set on our debiased test set. We argue our debiased dataset offers the PCVG task a more practical baseline for reliable benchmarking and future improvements.
Unsupervised Natural Language Inference Using PHL Triplet Generation
Oct 16, 2021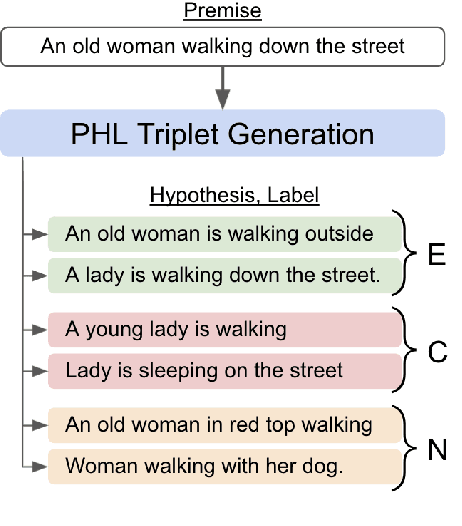

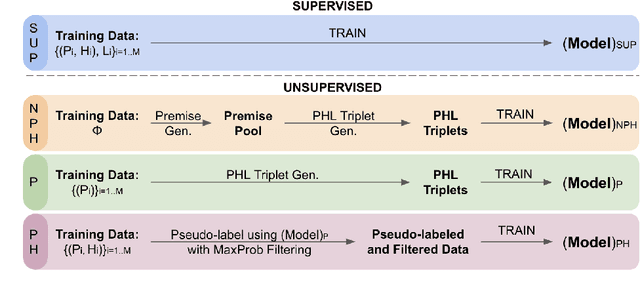
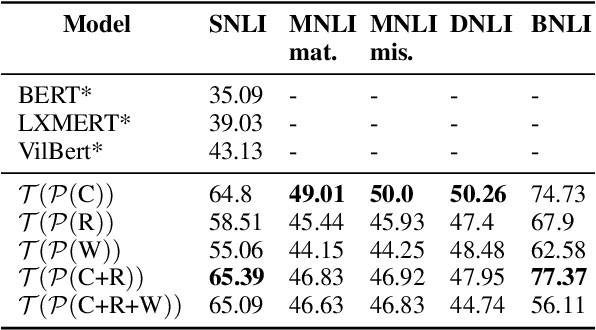
Transformer-based models have achieved impressive performance on various Natural Language Inference (NLI) benchmarks, when trained on respective training datasets. However, in certain cases, training samples may not be available or collecting them could be time-consuming and resource-intensive. In this work, we address this challenge and present an explorative study on unsupervised NLI, a paradigm in which no human-annotated training samples are available. We investigate NLI under three challenging settings: PH, P, and NPH that differ in the extent of unlabeled data available for learning. As a solution, we propose a procedural data generation approach that leverages a set of sentence transformations to collect PHL (Premise, Hypothesis, Label) triplets for training NLI models, bypassing the need for human-annotated training datasets. Comprehensive experiments show that this approach results in accuracies of 66.75%, 65.9%, 65.39% in PH, P, NPH settings respectively, outperforming all existing baselines. Furthermore, fine-tuning our models with as little as ~0.1% of the training dataset (500 samples) leads to 12.2% higher accuracy than the model trained from scratch on the same 500 instances.
Semantically Distributed Robust Optimization for Vision-and-Language Inference
Oct 14, 2021
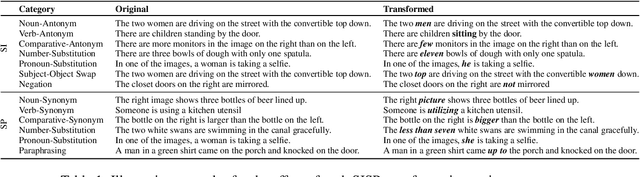
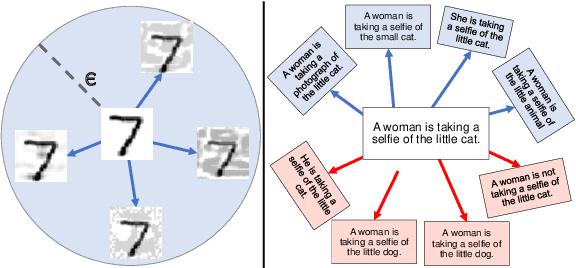
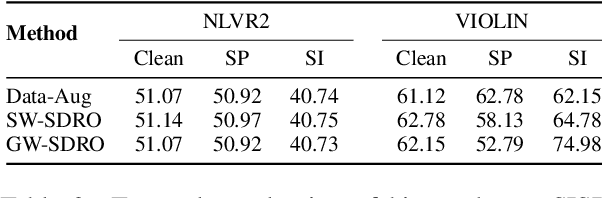
Analysis of vision-and-language models has revealed their brittleness under linguistic phenomena such as paraphrasing, negation, textual entailment, and word substitutions with synonyms or antonyms. While data augmentation techniques have been designed to mitigate against these failure modes, methods that can integrate this knowledge into the training pipeline remain under-explored. In this paper, we present \textbf{SDRO}, a model-agnostic method that utilizes a set linguistic transformations in a distributed robust optimization setting, along with an ensembling technique to leverage these transformations during inference. Experiments on benchmark datasets with images (NLVR$^2$) and video (VIOLIN) demonstrate performance improvements as well as robustness to adversarial attacks. Experiments on binary VQA explore the generalizability of this method to other V\&L tasks.
Weakly-Supervised Visual-Retriever-Reader for Knowledge-based Question Answering
Sep 09, 2021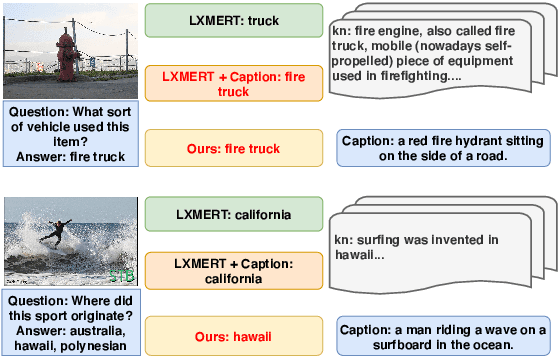
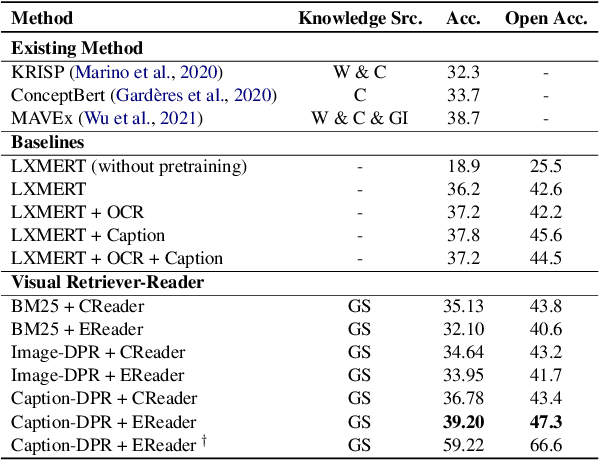
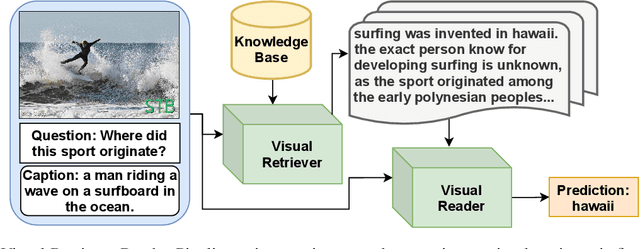

Knowledge-based visual question answering (VQA) requires answering questions with external knowledge in addition to the content of images. One dataset that is mostly used in evaluating knowledge-based VQA is OK-VQA, but it lacks a gold standard knowledge corpus for retrieval. Existing work leverage different knowledge bases (e.g., ConceptNet and Wikipedia) to obtain external knowledge. Because of varying knowledge bases, it is hard to fairly compare models' performance. To address this issue, we collect a natural language knowledge base that can be used for any VQA system. Moreover, we propose a Visual Retriever-Reader pipeline to approach knowledge-based VQA. The visual retriever aims to retrieve relevant knowledge, and the visual reader seeks to predict answers based on given knowledge. We introduce various ways to retrieve knowledge using text and images and two reader styles: classification and extraction. Both the retriever and reader are trained with weak supervision. Our experimental results show that a good retriever can significantly improve the reader's performance on the OK-VQA challenge. The code and corpus are provided in https://github.com/luomancs/retriever\_reader\_for\_okvqa.git